ժҪ
�����������ļ���λ���������Ȩ�ؿ���ʹ���Ǹ�Ч�ؼ���ʹ洢���ڴ���,�������Dz����ƶ��豸����Դ���豸��������Ҫ��Ȼ��,�������������ٵ�λ��ͨ�����;��ȡ�Ϊ�˽���������,���ǽ���ͨ��һ����ѵ�����������������������ɢ���ǡ������˵,���Dz����� quantization intervals(��������),��ͨ��ֱ����С�������������ʧ�����������ֵ������quantization-interval-learning��������ѧϰ(QIL)�����������籣��λ������4λ��ȫ����(32λ)����ľ���,��ͨ����һ������λ��(��3λ��2λ)����С�������˻�������,���ǵ��������������칹���ݼ��Ͻ���ѵ��,��˿�����������Ԥ��ѵ����������,������������ǵ�ѵ�����ݡ�������ImageNet���ݼ�����ʾ�����ǵĿ�ѵ������������Ч��,��ResNet-18,-34��AlexNet,����Щ����ܹ���,���������еķ���,�Դﵽ���Ƚ��ľ��ȡ�
1. ����
- ���������һ�־��в���������Ŀ�ѵ��������,��ͬʱִ�м�֦�ͼ��С�
- ���ǽ����ǵĿ�ѵ��������Ӧ������������Ȩֵ�ͼ���,���Զ˵��˷�ʽ��������Ż���Ŀ������Ȩֵ,��ʵ�������ض�����ʧ��
- ���ǵ�ʵ�����,���ǵ��������ڼ��͵�λ��(2��3��4λ)�����ImageNet�ϴﵽ�����Ƚ��ķ��ྫ��,���Ҽ�ʹ��ʹ���칹���ݼ�����ѵ����Ӧ����Ԥѵ��������ʱҲ�ܴﵽ�����ܡ�
�����������ѵ��������ͬʱ���м�֦�ͼ��еĿ�ѵ����������,��ͨ�����ò�����Ӧ����Ȩֵ�ͼ�������,���DZ��ַ��ྫ����ȫ����������ͬ,ͬʱ����������λ����
3. ����
��ѵ����������������������������Χ,���ͼ�����Χ������֮�⡣���ǽ���ѵ������������Ӧ���ڼ����Ȩ������,������������ʧ��������Ż�(ͼ1)���ڱ�����,�������Ȼع˺ͽ��͵�λ���������������,Ȼ��������ǵľ�����������Ŀ�ѵ����������
3.1.��λ�������е�����
����ȫ���Ⱦ���������(CNN)�ĵ�l��,ȨֵWl�����뼤��Xl���о���,����Wl��Xl��ʵֵ���������Ƿֱ���wl��xl��ʾWl��Xl��Ԫ�ء�Ϊ�˱��ڷ���,���ǽ��±�lȥ��������λ���������漰һ����������,��������ͨ���������������Ȩֵ��w�ʡ�W���������뼤�x�ʡ�X,

�ڱ�����,���Dz�����������(��ѹ��),ʹ���ѵ�������ǹ̶������,��Щ������������������ģ�͵�Ȩֵһ����������Ż������ǿ��Եõ����ŵġ�W�͡�X,ֱ����С�����������������ʧ(��������������ʧ)(ͼ1(b)),�����Ǽؽ���ȫ���ȵ�Ȩ��/����,������ W ? X W*X W?X �� \approx �� W �� \overline{W} W * X �� \overline{X} X��������,����,?Ϊ�������㡣
3.2.��ѵ�����������
Ϊ�����������,���ǿ��������ֲ���:���кͼ�֦(ͼ1(a))�����еĻ���˼�����������ӻ�[27,4]���Ͻ硣��С�Ͻ���������Ͻ��ڵ������ֱ���,�Ӷ���ߵ�λ������ľ��ȡ���һ����,����������õ�̫��,���ȿ��ܻή��,��Ϊ��ü�̫���ֵ�����,����һ���ʵ��ļ�����ֵ���ڱ��������������������Ҫ�ġ���֦ɾ����ֵȨ�ز���[7]�����Ӽ�֦��ֵ��������������ֱ���,����ģ�͵ĸ��Ӷ�,������֦��ֵ���õù��ᵼ�������½�,��ԭ������з�����ɵ�ԭ����ͬ��
���Ƕ���������������ͬʱ���Ǽ�֦�ͼ��С�Ϊ���Զ���������,ÿһ�������ֱ���c?��d?(?��{W,X})������,����c?��d?�ֱ��ʾ��������ĺ;������ĵľ��롣��ע��,��ֻ��һ�����ѡ��,���������͵IJ�����,������½���Ͻ�IJ�����,Ҳ�ǿ��ܵġ����������ȿ���Ȩ�ص���������ΪȨֵͬʱ������ֵ��ֵ,��������������ֵ�����϶����жԳ��ԡ������������cW��dW,���Ƕ�ת����TW�Ķ�������:


���������ɿ�ѵ�����������cW��dW�� �� ��ơ����� �� �ķ����Ժ��������������ڵķֲ���ͼ2�е�ͼ����ʾ�˾��в�ͬ�õ�ת����(��ɫ����)������Ӧ��������(��ɫʵ��)�������=Ϊ1,���ѹ����һ���ֶ����Ժ���,����������ڲ�ֵ����������(ͼ2(a))��ͨ������ ��,���Զ��ڲ�ֵ���зǾ�������(ͼ2(b��c))���� ��������Ϊ�̶�ֵ,Ҳ���Ծ���ѵ����������ʵ����֤���˦õ����á������
��
\neq
��?= 1,�������ӡ�Ȼ��,Ȩ����������ѵ����ɾ��,����ֻʹ��������Ȩֵ�������������,������ӵķ����Ժ����������ή�������ٶȡ�ʵ������ֵthp ?�ͼ�����ֵthc ?�����cW��dW�� �� ���仯,��ͼ2��ʾ������,��=1����µ�thp ?��thc ?��������: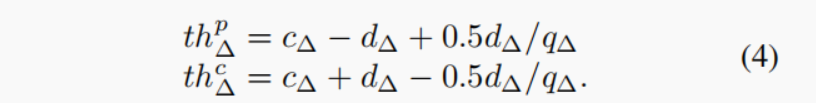
ע��,Ȩ�ص�����������qW���Լ���ΪqW=2NW~?1^?1(һ��,0����),����λ��NW�����,2λ��Ȩֵʵ��������Ԫ��{?1,0,1}��
����ReLU����,���뵽������ļ����ǷǸ��ġ����ڼ�������,������cX+dX��ֵ�ü���ӳ��Ϊ1,���ǽ�С��cX?dX��ֵ��Ϊ0���м��ֵ������ӳ�䵽[0,1],����ζ����Щֵ�����������ڱ����ȵ���������Ȩ��������ͬ,��������Ӧ�����������������߽���,������ǽ��ù̶�Ϊ1�Խ��п��ټ��㡣Ȼ��,�����ת����TX��������(ͼ2(a)):

����,��X=0.5/dX�ͦ�X=?0.5cX/dX+0.5�����������λ��NX,��������qX(0����)���Լ���ΪqX=2NX?1;��,����2λ����,����ֵΪ{0��1��2��3}��
����ʹ������ݶ��½����Ż�Ȩֵ���������IJ�������Щת�����Ƿֶο���,������ǿ��Լ����������������c?,d?�ͦõ��ݶȡ�����ʹ��ֱ�ӹ�����[2,27]������ɢ�����ݶȡ�
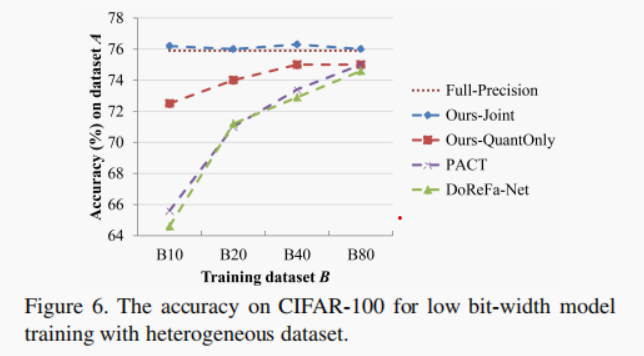
������,���ǵķ���������������ѵ��Ȩֵ������Ȼ��,Ҳ�п�����һ������ȫ����Ȩֵ��Ԥ��ѵ������������ѵ�������������˾��ȵ���,ֻѵ����������û�и���Ȩ��Ҳ�ܲ����൱�õľ���,�����侫�ȵ�������ѵ��(��ͼ6)��

4. ʵ����
4.1 ImageNet

��ʼ��
�������õIJ�����ʼ������,�����ѵ����ĵͱ��ؿ�����[17,19]�ľ��ȡ�Ϊ��ʵ�����õij�ʼ��,���Dz�����һ�����ķ�������[17]��,�������дӸ�λ������λ��������,�Ի�ø��õij�ʼ�������DZȽ���ȫ���������ֱ���������1λ��λ������������Ľ��(��2)��Ϊ�˽��н���ʽ����,��������ѵ��4/4��3/3��2/2λ����(��,2/2λ�����FP��5/5��4/4��3/3��2/2)��һ����˵,�������ľ��ȸ���ֱ����������������2/2λ����(9.7%�ĵ㾫�����)������Ҫ,����4/4��3/3λ�����Ӱ���С(�ֱ��Ϊ0.2%��0.5%�ĵ����)��
����ѵ��vs������
Ȩ�ز�������������������ͬ�����Ż���������ֻ���Ż�������,ͬʱ����Ȩ�ز������䡣��3��ʾ��ResNet-18����������������µ�top1�����ȡ�����������������˽���ʽ��������������Ȩֵ������ѵ����ֻѵ��������Ч������,�������ǵ�ֱ����һ�µġ����ѵ�����������,����ѵ���ڼ��ٱ��ؿ���ͬʱ���ֳ����ŵ������½���Ȼ��,��������4λ����ߵ�λ��ʱ�ľ������൱����ġ�����,4/4λģ�͵ľ����½���Ϊ2.1%(70.1%��68.0%)��

������
Ϊ�˿������ǵ��������ļ�֦Ч��,���Ǽ����֦����,����ĸ���ռȨֵ�������ı�����ͼ3��ʾ��ResNet-18��AlexNet�����������ƽ����֦�ʡ�����Ԥ�ڵ�����,��֦������λ���ļ�С�����ӡ���λ����ʱ,���������ֱ��ʸ�,���Էſ��������䡣Ȼ������λ������,Ӧ���ҵ������յļ��������ȷ��,���,��֦�����ӡ�����2/2λ����,AlexNet��ResNet-18��Ȩ��ƽ���ֱ�Ϊ91%��81%����(ͼ3)��AlexNet��ResNet-18������,��ΪAlexNet��ȫ���Ӳ�,�����Ⱦ������18��64��,ȫ���Ӳ���п��ܱ�����������λ����Ӱ���С��ͼ4ΪResNet-18�����鼶��֦�ʡ����Ǽ���ÿ���������������һ����Ծ������ɵ�ResBlock�����ȡ����ڼ���,�ϲ���п��ܱ���,���������Ϊ����ij������ڸ��ߵIJ㡣


ѵ�� �� �� ��
����Ȩ������,�����æ�(Eq.3)�������������ڵķֲ��������о���ѵ���õ�Ч������4��ʾ�˸���3/3��2/2λAlexNet�ĸ��֦õ�top1�����ȡ����DZ����˿�ѵ���Ħú̶��Ħá�����3/3λģ��,��ѵ���ò�Ӱ��ģ�;���;����ѵ����Ϊ61.4%,��=1Ϊ61.3%��Ȼ��,��ѵ���Ħö���2/2λģ������Ч��,���=1���,ǰ1�ľ��������0.9%,���̶��Ħ�Ϊ0.5��0.75�ľ������=1���ơ��̶��Ħ�ֵΪ1.5 �����½���

Ȩ������
Ϊ��֤�����ǵķ�����Ȩ�������ϵ���Ч��,����ֻ������Ȩ��,�������˼����ȫ���ȡ����Dz�����ResNet-18�Ͼ��в�ͬλ����Ȩ�صľ���,�����������е��������������˱Ƚ�(��6)�������ǵķ�������������ľ����Ը���ʹ�õڶ��ŷ���(LQ-Nets[26])��
Ȩ�غͼ������ķֲ�
ͼ5��ʾ�˲�ͬʱ�ڵ�Ȩ�غͼ������ķֲ�����������ͬʱѵ��Ȩֵ��������,���Ȩֵ����������ķֲ���ѵ�������з����˱仯����ע��,Ȩ�طֲ��ķ�ֵ������ÿ������ֵ�Ĺ��ɴ������Ŀ������С���������,��ô���ֲַ��Dz���ȡ�ġ��������ǵ�Ŀ������С��������ʧ,��ѵ��������,ֻ�е�����ˮƽ��ͬʱ,��ʧ�ű�ͬ�����,Ȩ��ֵ����ɱ߽��ƶ������ǻ������˾������ͼ�����ֵ�ļ���ֲ���(ͼ5:(d))��

4.2 CIFAR-100
�ڱ�ʵ����,���Ǵ�һ��û��ԭʼѵ�����ݼ���Ԥ��ѵ���õ�ȫ����������ѵ��һ����λ�����硣��ʵ���Ŀ����Ϊ����֤��û�и���ԭʼѵ�����ݼ�ʱ,�Ƿ��п���ѵ����λ��ģ����Ϊ����ʾ�������,����ʹ����CIFAR-100[14],����100�������,ÿ�������500��ѵ��ͼ���100����֤ͼ��,����100���౻�ֳ�20������(ÿ��������5����)�����ǽ����ݼ�����Ϊ�������ཻ����A(4������,20����)��B(16������,80����),����A��ԭʼѵ����,B��Ϊ�칹���ݼ�����ѵ����λ��ģ��(��ʵ����Ϊ4/4λģ��)��B��һ����Ϊ4���Ӽ�B10��B20��B40��B80(B10?B20?B40?B80=B),�ֱ�Ϊ10��20��40��80�ࡣ
5.����
�����һ�־��в�������������Ŀ�ѵ����������ѵ���ͱ��ؿ����硣���ǵĿ�ѵ����������Ȩ�غͼ���ͬʱ�������ͼ���,ͬʱͨ��ѧϰ�ʵ����������������ȫ���������ȷ�ԡ�����û����֮ǰ�Ĺ�������,��С����ȫ���������Ȩֵ/������ص��������,����ͨ��ֱ����С��������ʧ������ѵ������������Ȩֵ�����,�����ڴ��ģ��ImageNet�������ݼ���ȡ���˷dz���ϣ���Ľ����ʹ�����ǵķ�����õ�4λ���籣���˾��и�����ϵ�ṹ��ȫ��������ľ���,3λ��������ľ�����ȫ���������൱,��2λ����ľ�����ʧ��С�����ǵ�������Ҳʵ�������õ���������,��ʹ���칹���ݼ��Ͻ���ѵ��ʱҲ�������еķ���,��ʹ������Ԥѵ������û�з���ԭʼѵ�����ݵ�����·dz�ʵ�á�δ���Ĺ������ܰ����÷ֶ����Ժ�������ȷ�IJ��������������ʹ�ñ�Ҷ˹������