1. Seq2seq model
1.1 Seq2seq model 的应用场景
-
语音辨识, 中文音频到中文 文字, 音频到文字
-
语言翻译, 中文文字到英文, 文字 到文字;
-
语音翻译, 中文音频 到 英文 文字, 结合上述两个;
世界上7000 多种语言,还有 很多语言,还没有文字 , -
文本 到语音: 输入文本,输出音频;
-
用于文法解析(用于编译过程中, 编译),seqseq for syntactic Parsing, “ Grammar as Foreign Language ” 14 年;
-
-
for Muli label calssifiction: 即 同一个目标对象 它同时属于多个标签;
区别于Mutil class, 多个类别中 分类出一个类别; -
for Object Detectiono;
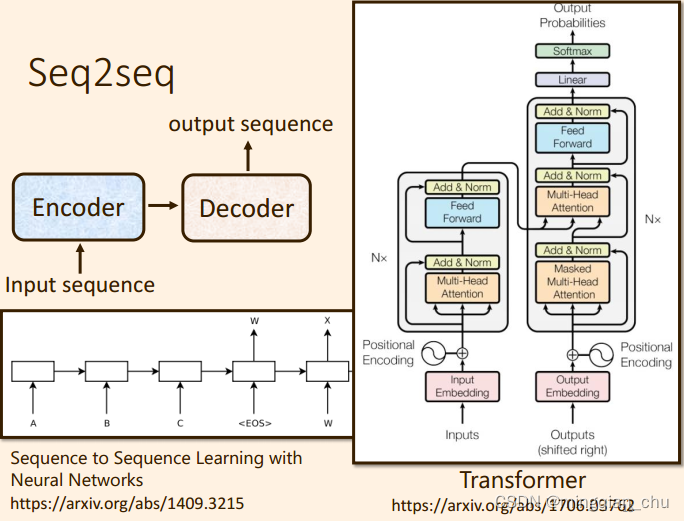
2. Seq2seq model 组成模块
主成分两块:
- Encoder
- Decoder 部分;
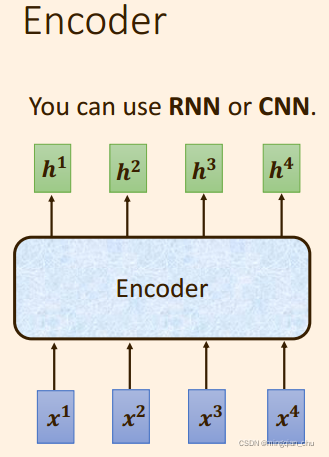
2. Encoder 编码器
多个输入向量 编码后 得到多个输出向量
3. Transformer 中的 Encoder
-
Transformer 中的Encodr 编码器可以看做是多个Block 组成。
-
每个Block 在 self attention 的基础上 增加了残差连接 + Layer Norm + FC;
-
注意,这里每一个Block 是模型中多个 Layer 所做的事情;
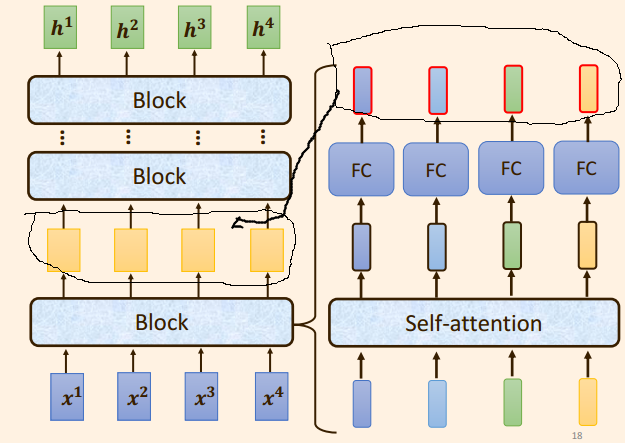
3.1 单个Block 中的内容
- 每个Block中包含了:
自注意力机制 + 残差链接 + LayerNorm + FC + 残差链接 + layer Norm, 此时的输出 = 一个 Block 的输出;

3.2 单个Block 中的具体实现步骤
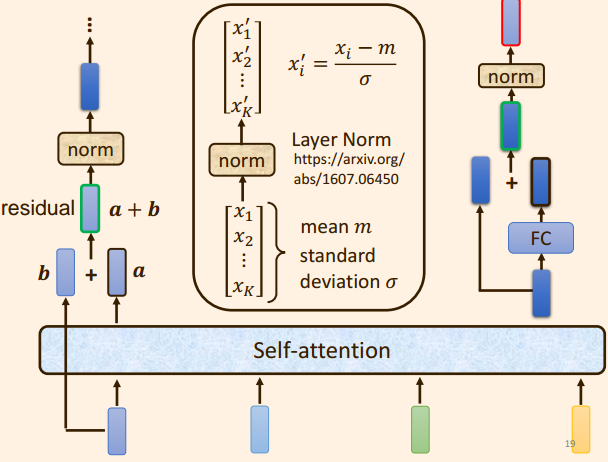
- 原始的输入向量
b
b
b 与 输出向量
a
a
a 残差相加 得到 向量
a
+
b
a + b
a+b;
注意, b b b 是原始的输入向量,下图中输出向量 a a a 是考虑整个序列的输入向量得到的结果;

Layer Normation: 不需要考虑batch;
同一个样本, 同一个 feature , 不同的 dimeation 中 去计算 mean 和 方差;
Batch Normalization:
不同的样本, 不同的特征,但是 同一个 dimeation 去计算 mean ,和方差;
- 将向量 a + b a + b a+b 通过 Layer Normation 得到 向量 c c c;
图中左侧部分:
图中右侧部分:
-
将向量 c c c 通过 FC layer 得到 向量 d d d ;
-
向量 c c c 与向量 d d d 残差相加 ,得到向量 e e e ;
-
向量 e e e 通过 Layer Norm 输出 向量 f f f,
-
此时得到的输出向量 f f f 才是 Encoder中 单个Block中的一个输出向量;
3.3 上述步骤的等价
上述步骤,便是原始论文Transformer 中,Encoder 的设计;
注意到, 这里的Multi Head Attention 多头注意力, 是 self attention 的 基础上增加了
q
q
q,
k
k
k ,
v
v
v 的数量, 从而称作是多头;
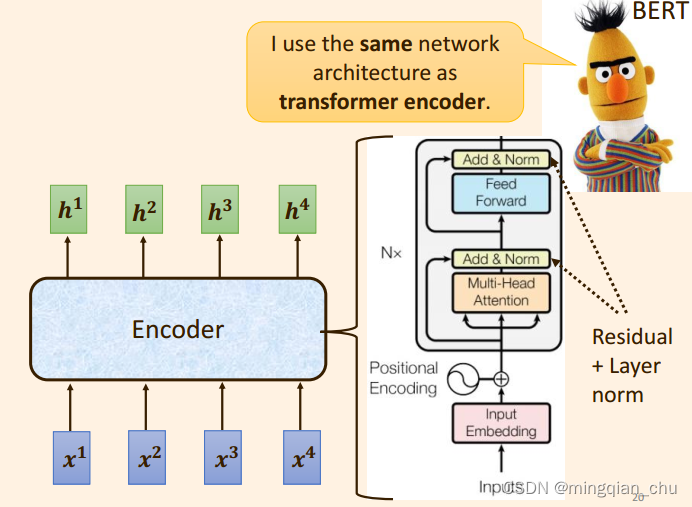
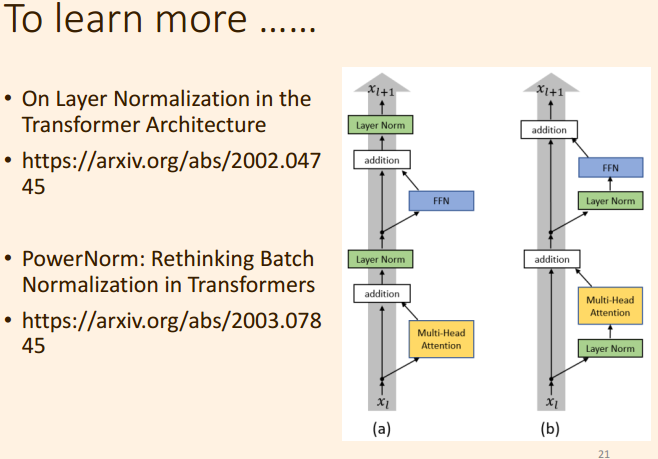
3.4 网络的优化
- 更改LayerNorm 的 位置顺序;
- 更换层, layerNorm --> PowerNorm;