前文再续,书接上一回,我们看看wav2vec2怎么提取特征。
在论文中,wav2vec2是通过conv1d进行特征提取的。如下图:
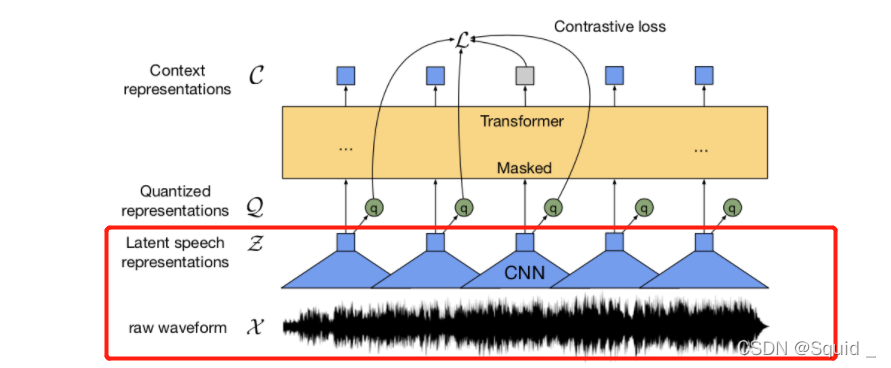
而conv1d的具体结构也已经给出:
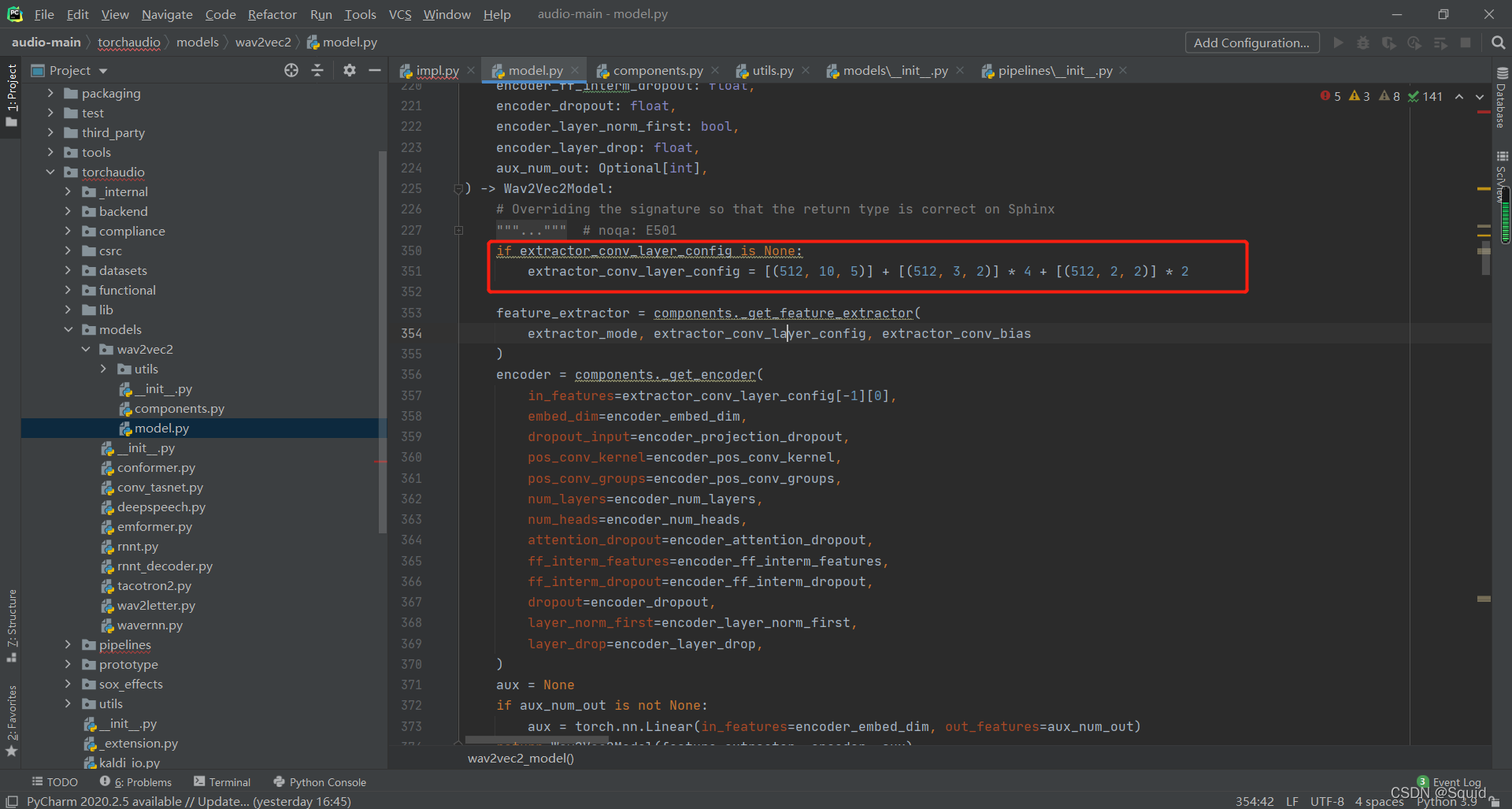
extractor_conv_layer_config列表中的三元组的含义分别表示:out_channels、kernel_size、stride。
然后我们看看feature_extractor是怎么生成的。
特征提取
我们跟着提示点进components.py文件中找到_get_frature_extractor方法。
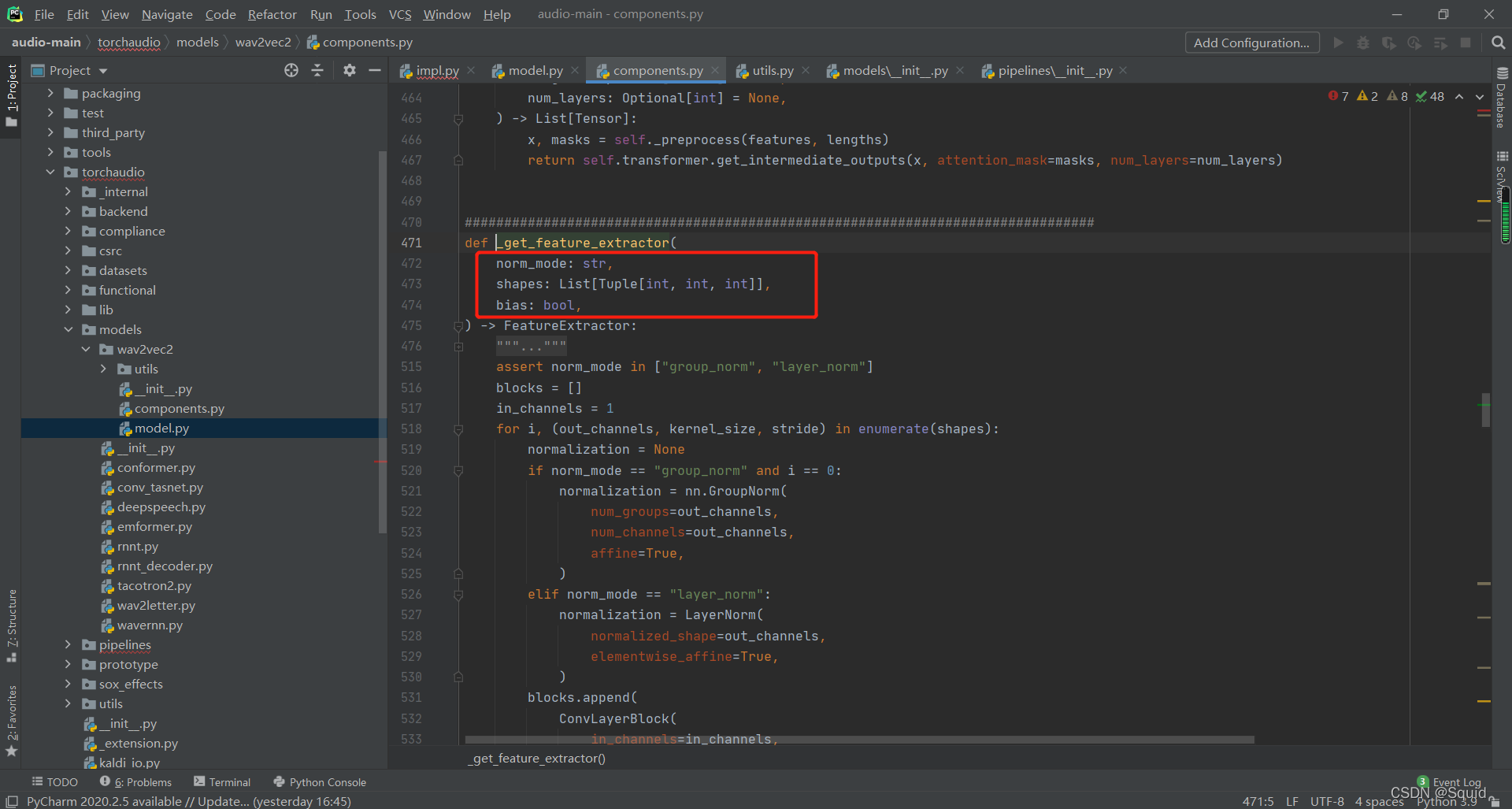
主要工作:
这个函数做的主要就是构造一个conv1d模型,用于对原音频的特征提取。
三个形参为:norm_mode表示归一化的模式选择、shapes表示conv1d的结构参数、bias表示是否设置偏置值
里面的归一化模型参数有:
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)*H*W的均值
- LayerNorm:channel方向做归一化,算C*H*W的均值
总体结构如下代码:
def _get_feature_extractor(
norm_mode: str,
shapes: List[Tuple[int, int, int]],
bias: bool,
) -> FeatureExtractor:
assert norm_mode in ["group_norm", "layer_norm"]
# 块
blocks = []
# 输入:语音
in_channels = 1
# 穷举结构参数
for i, (out_channels, kernel_size, stride) in enumerate(shapes):
# 归一化模型
normalization = None
# 如果归一化模型是组归一化
if norm_mode == "group_norm" and i == 0:
# 组归一化模型构造
normalization = nn.GroupNorm(
num_groups=out_channels,
num_channels=out_channels,
affine=True,
)
# 如果是层归一化
elif norm_mode == "layer_norm":
# 层归一化模型构造
normalization = LayerNorm(
normalized_shape=out_channels,
elementwise_affine=True,
)
# conv1d模型构造,把归一化也传进去
blocks.append(
ConvLayerBlock(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
bias=bias,
layer_norm=normalization,
)
)
# 输出channel变输入channel(1变512、512变512.....)
in_channels = out_channels
# 把列表blocks转换成pytorch模型列表然后返回提取特征的结果
return FeatureExtractor(nn.ModuleList(blocks))
ConvLayerBlock对象
点开ConvLayerBlock对象查看相关代码:
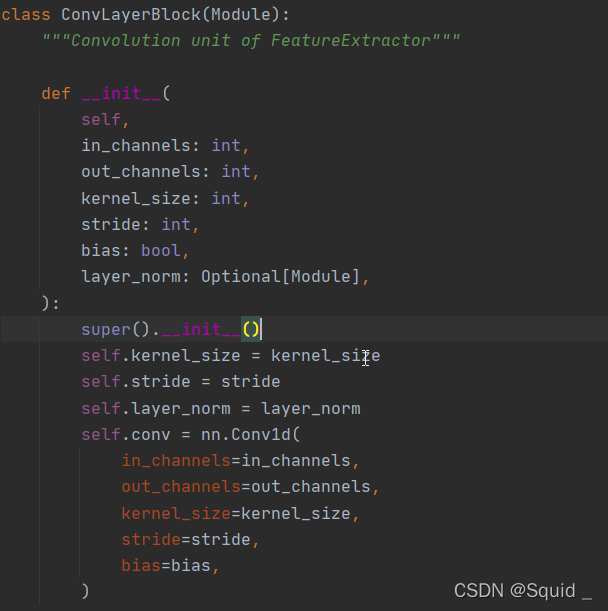
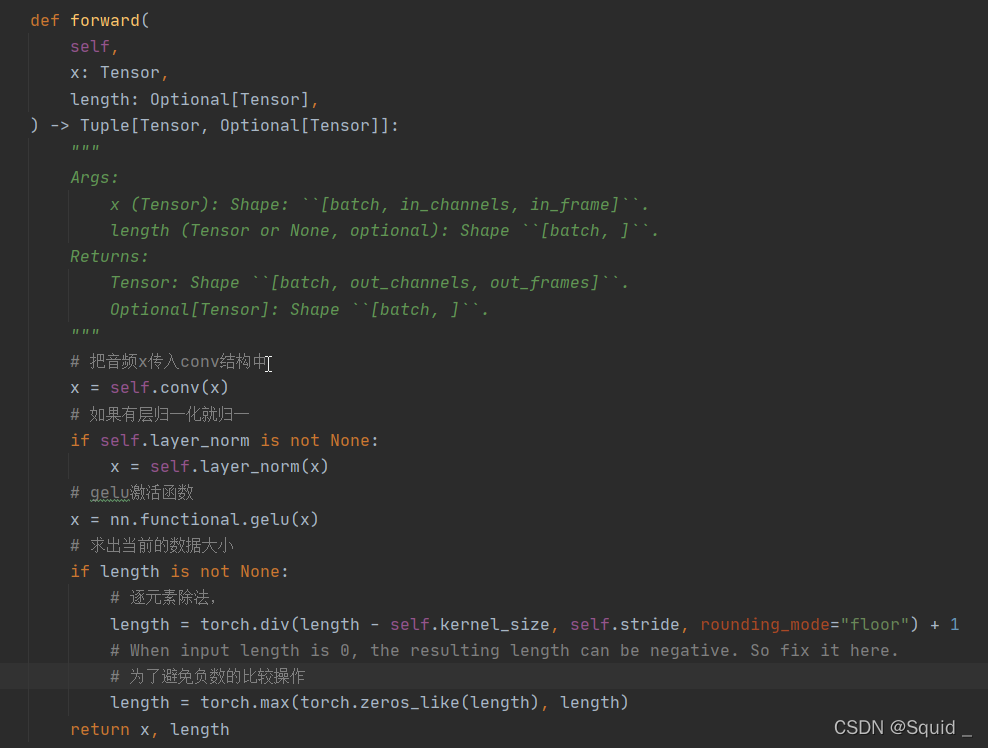
这是ConvLayerBlock对象的初始化代码。就是设计conv1d的结构。然后还有forword函数如下(forword函数就是把数据传入模型中跑的函数):
FeatureExtractor对象
接下来看看_get_feature_extractor函数要返回的FeatureExtractor对象。
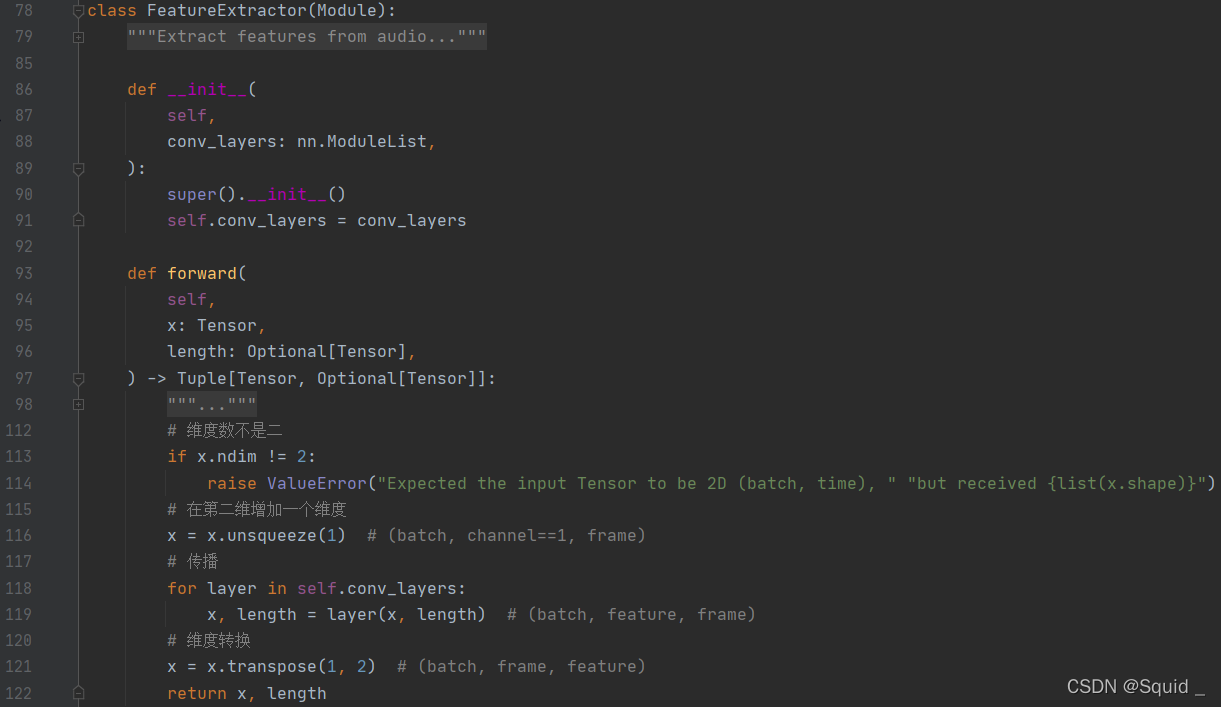
初始化就是把conv1d的nn.ModuleList模型传进去。主要就是forword函数了。
这里的116行增加一个维度是为了符合in_channel=1的设定。
这里的119行的layer就是调用了ConvLayerBlock对象中的forword函数。
总结
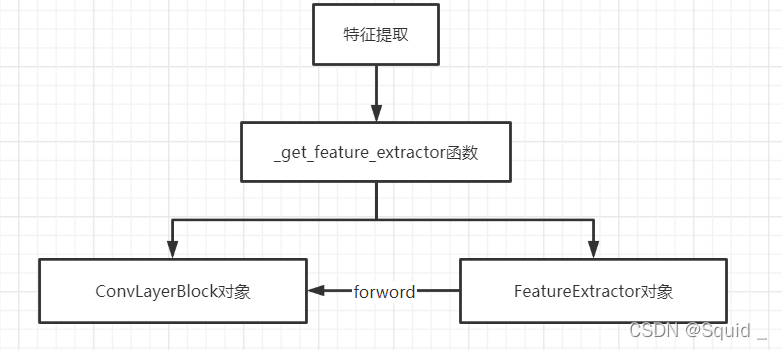
特征提取需要用到_get_frature_extractor方法,其中_get_frature_extractor方法主要调用了ConvLayerBlock对象和FeatureExtractor对象进行特征提取模型的构建和使用。
下一个博客我们看transfromer_encoder的构建。