
为什么需要中文分词?
●与英文为代表的拉丁语系语言相比,英文以空格作为天然的分隔符,而中文由于继承自古代汉语的传统,词语之间没有分隔。
●古代汉语中除了连绵词和人名地名等,词通常就是单个汉字,所以当时没有分词书写的必要。而现代汉语中双字或多字词居多,一个字不再等同于一个词。

分词作用
互联网绝大多数应用都需要分词,典型应用实例
?汉字处理:拼音输入法、手写识别、简繁转换
?信息检索: Google、 Baidu
?内容分析:机器翻译、广告推荐、内容监控
?语音处理:语音识别、语音合成
举例

中文的语义与字词的搭配相关

定义
●什么是分词?
?分词就是利用计算机识别出文本中词汇的过程。比如句子“内塔尼亚胡说的确实在理"

中文分词常用算法
分词算法分类
●基于字符串匹配的分词算法
●基于统计的分词算法
●基于理解的分词算法
基于字符串匹配的分词算法
字符串匹配分词(机械分词)

正向最大匹配算法
基本思想:
选取固定长个汉字的符号串作为最大符号串,把最大符号串与词典中的单词条目相匹配,如果不能匹配,就去掉一一个汉字继续匹配,直到在词典中找到相应的单词为止。
匹配方向是从左向右,减字方向是从右向左。




机械分词
●优点
?程序简单易行,开发周期短
?没有任何复杂计算,分词速度快
●不足
?不能处理歧义
?不能识别新词
?分词精度不能满足实际的需要(规范文本80%,互联网文本在70%左右)
基于统计的分词算法
统计分词
●生成式统计分词
●判别式统计分词



生成式分词
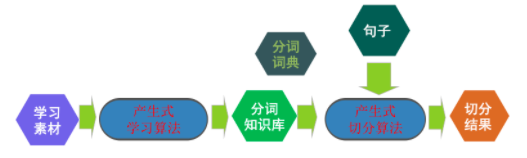
●优点
?在训练语料规模足够大和覆盖领域足够多的情况下,可以获得较高的切分正确率(>=95%)
●不足
?需要很大的训练语料?新词识别能力弱
?解码速度相对较慢
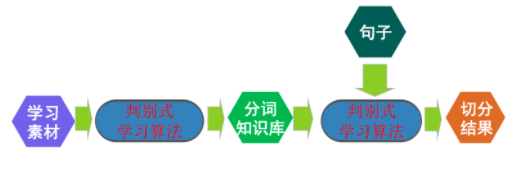
判别式分词
原理
?在有限样本条件下建立对于预测结果的判别函数,直接对预测结果进行判别,建模无需任何假设。
?由字构词的分词理念,将分词问题转化为判别式分类问题
优势
?能充分利用各种来源的知识
?需要较少的训练语料
?解码速度更快
?新词识别性能好

分词过程示例


判别式分词
●特征所涉及的语言学知识
?字的上下文知识
?形态词知识:处理重叠词、离合词、前后缀
?仿词知识: 2000年
?成语/惯用语知识
?普通词词典知识
?歧义知识
?新词知识/用户词典
?新词的全局化知识
优点
?理论基础扎实
?解码速度快
?分词精度高
?新词识别能力强
?所需学习素材少
弱点
?训练速度慢
?需要高配置的机器训练
基于理解的分词算法
(1)通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
(2)包括三个部分
●分词子系统
●句法语义子系统
●总控部分
特点
(1)在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。
(2)这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。

中文分词的难点及应用领域




常见分词系统
●ICTCLAS
Institute of Computing Technology, Chinese Lexical Analysis System
由中国科学院计算技术研究所开发
主要功能有
自动分词
词性标注
●斯坦福分词系统
(1)斯坦福分词系统是- 一个开源的软件,它基于CRF (Condition Random Field, 条件随机场)机器学习理论。
(2)该系统提供了了两个分词数据模型,
- 一个是基于宾州中文树库
- 另外一个是基于北京大学为sighan第二届中文分词竞赛提供的数据
(3)使用形式如下:
●segment ctb| pk filename encoding
●参数说明如下:
●ctb:宾州中文树库。
●pk:北京大学语料库。
●filename: 待分词的文件名。
●encoding: 待分词文件的编码,可以是UTF 8, GB18030等java所支持的编码。
中文分词的应用领域

中文新词识别
新词的定义
(1)词典参照的角度
●现代汉语基本词汇所没有的词语
新形式
新意义
新用法
(2)时间参照角度
●在某一时间段内或自某一时间点以来首次出现的具有新词形、新词义或者新用法的词汇
●随着互联网不断发展,新词大量涌现
未登录词与新词
●未登录词:未在当前所用词典中出现的
●新词:随着时代的发展而新出现或旧词新用的词
多数研究者对这两个概念不加区别
●中文信息处理领域新词识别
一般把新词视为未登录词来进行处理
●对未登录词的处理在实用分词系统中举足轻重
新词的分类

新词识别的任务
●候选新词的提取
●垃圾字串的过滤
●新词的词性猜测
新词识别的发展过程(一)
(1)最早的一篇文章是1990年汪华峰的《汉语自然语言理解中词切分中新词问题初探》
●基于统计的方法,只考虑了词频一个特征
(2)在之后的十年研究成果较少
(3)2002年郑家恒等人的《基于构词法的网络新词自动识别初探》
●采用了规则的方法
●对新词的词长、构词规则进行了总结,依靠语言学规则进行新词识别,取得了较好的效果


新词识别的方法
- 基于规则的方法
- 基于统计的方法
- 规则与统计相结合的方法
基于规则的方法
(1)利用语言学知识,总结新词的构词特点建立规则库,利用规则库筛选新词
(2)优点
●准确率高
(3)缺点
●构建规则库工作量大、成本高
●规则不能概括所有的语言现象
对于不符合规则的新词会造成遗漏,且规则过多规则之间容易相互冲突
●规则库的更新困难.
新词产生的速度快、组词灵活,构建的规则库难以适应新词产生的速度
●移植性差
规则方法常与特定领域相关
●新词词性规则
新词主要集中在名词、动词、形容词这三类实词上
名词所占比例最高
虚词一般不构成新词
基于统计的方法
(1)统计方法主要以大规模语料库作为训练语料,根据新词的特点统计各种有效数据来识别新词。逐渐成为主流方法。
(2)优点:
●不依赖规则
●不限定领域
●移植性好
(3)缺点
●统计方法的计算量大
●大规模语料进行模型训练
●由于使用的语言知识较少,一般都存在数据稀疏和准确率低的问题
●会形成大量垃圾串,垃圾串的过滤是统计方法的难点。
新词识别的统计特征
●字或词的频数和出现文数
●词内部概率
●时间特征
●邻接类别
字或词的频数和出现文数

时间特征

词内部概率

邻接类别
●新词作为词,内部要稳定,上下文要灵活
●上下文邻接(左邻接、右邻接)集合
集合元素越多,说明词的上下文语境越灵活,越可能是一个新词
规则和统计相结合的方法
(1)规则方法和统计方法各有不足,将两种方法相结合以提高识别效果。
●实践中采用统计方法为主辅之以规则方法过滤,对规则的深入研究和运用仍然较少。
●采用统计和规则相结合的方法来识别新词的文献
新词识别的基础知识
●正确率=提取出的正确新词数/提取出的新词数
●召回率=提取出的正确新词数/样本中的新词数
两者取值在0和1之间,数值越接近1,正确率或召回率就越高。
●F值=正确率召回率2/(正确率+召回率)
F值即为正确率和召回率的调和平均值
新词识别研究的主要技术方法
●基于支持向量机(SVM)
●基于最大熵模型(ME)
●条件随机场模型(CRF)
●基于隐马尔科夫模型(HMM)
●基于决策树(DT)
支持向量机(SVM)



存在的问题
●新词识别方法具有一定局限性
●识别效果有待提高
●新词定义不统一, 人工判定新词的具有主观性
●新词产生时间的模糊性
●分词后识别方法中的分词错误
●垃圾串过滤的复杂性
●少数民族语的新词识别研究几乎没有
●多语种的新词识别研究成果非常少