����Ŀ¼
һ������
torch==1.10.2
transformers==4.16.2
������ȱɶװɶ
����ģ��
����ƪ������,���ܹ�ʹ��������ģ����ѵ��,�Ա�ѵ��Ч�����ֱ���
- BiLSTM
- BiLSTM + CRF
- Bert + BiLSTM + CRF
1��BiLSTM
ģ�ʹ��½ṹ
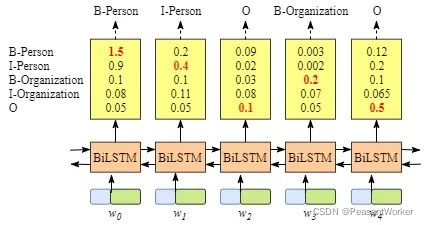
ֻ��BiLSTM����NER�Ļ�,ʵ���Ͼ��Ƕ����,��Ȼ�Ƕ����,��ô������ʧ�����Ϳ����ý���������ʾ��ģ��������ʧ��������:
class BiLSTM(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size, drop_out=0.5, use_pretrained_w2v=False):
super(BiLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
if use_pretrained_w2v:
print("����Ԥѵ��������...")
vec_path = get_pretrained_char_vec_path()
word2id_path = get_word2id_path()
id2word_path = get_id2word_path()
embedding_pretrained = GetPretrainedVec.get_w2v_weight(emb_size, vec_path, word2id_path, id2word_path)
self.embedding.weight.data.copy_(embedding_pretrained)
self.embedding.weight.requires_grad = True
self.bilstm = nn.LSTM(emb_size, hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size*2, out_size)
self.dropout = nn.Dropout(drop_out)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward(self, x, lengths):
x = x.to(self.device)
emb = self.embedding(x)
emb = self.dropout(emb)
emb = nn.utils.rnn.pack_padded_sequence(emb, lengths, batch_first=True)
emb, _ = self.bilstm(emb)
output, _ = nn.utils.rnn.pad_packed_sequence(emb, batch_first=True, padding_value=0., total_length=x.shape[1])
scores = self.fc(output)
return scores
def predict(self, x, lengths, _):
scores = self.forward(x, lengths)
_, batch_tagids = torch.max(scores, dim=2)
return batch_tagids
def cal_bilstm_loss(logits, targets, tag2id):
PAD = tag2id.get('<pad>')
assert PAD is not None
mask = (targets != PAD)
targets = targets[mask]
out_size = logits.size(2)
logits = logits.masked_select(
mask.unsqueeze(2).expand(-1, -1, out_size)
).contiguous().view(-1, out_size)
assert logits.size(0) == targets.size(0)
loss = F.cross_entropy(logits, targets)
return loss
�������ǿ���ѡ���Ƿ�ʹ��Ԥѵ������������Ϊembeeding��ij�ʼ������,�Ҳ�������ģ��ѵ���ڼ���и��¡�
�ڼ���ȷ��ʱ,����������ǩ��ȷ��,ѡ���˶�ner�����Ϊ������ʵ�弶ȷ��
���㷽������:
from .help import flatten_lists
def _find_tag(labels, B_label="B-COM",I_label="M-COM", E_label="E-COM", S_label="S-COM"):
result = []
lenth = 0
for num in range(len(labels)):
if labels[num] == B_label:
song_pos0 = num
if labels[num] == B_label and labels[num+1] == E_label:
lenth = 2
result.append((song_pos0,lenth))
if labels[num] == I_label and labels[num-1] == B_label:
lenth = 2
for num2 in range(num,len(labels)):
if labels[num2] == I_label and labels[num2-1] == I_label:
lenth += 1
if labels[num2] == E_label:
lenth += 1
result.append((song_pos0,lenth))
break
if labels[num] == S_label:
lenth = 1
song_pos0 = num
result.append((song_pos0,lenth))
return result
tags = [("B-NAME","M-NAME", "E-NAME", "S-NAME"),
("B-TITLE","M-TITLE", "E-TITLE", "S-TITLE"),
("B-ORG","M-ORG", "E-ORG", "S-ORG"),
("B-RACE","M-RACE", "E-RACE", "S-RACE"),
("B-EDU","M-EDU", "E-EDU", "S-EDU"),
("B-CONT","M-CONT", "E-CONT", "S-CONT"),
("B-LOC","M-LOC", "E-LOC", "S-LOC"),
("B-PRO","M-PRO", "E-PRO", "S-PRO")]
def find_all_tag(labels):
result = {}
for tag in tags:
res = _find_tag(labels, B_label=tag[0], I_label=tag[1], E_label=tag[2], S_label=tag[3])
result[tag[0].split("-")[1]] = res
return result
def precision(pre_labels,true_labels):
'''
:param pre_tags: list
:param true_tags: list
:return:
'''
pre = []
pre_labels = flatten_lists(pre_labels)
true_labels = flatten_lists(true_labels)
pre_result = find_all_tag(pre_labels)
true_result = find_all_tag(true_labels)
result_dic = {}
for name in pre_result:
for x in pre_result[name]:
if result_dic.get(name) is None:
result_dic[name] = []
if x:
if pre_labels[x[0]:x[0]+x[1]] == true_labels[x[0]:x[0]+x[1]]:
result_dic[name].append(1)
else:
result_dic[name].append(0)
# print(f'tag: {name} , length: {len(result_dic[name])}')
sum_result = 0
for name in result_dic:
sum_result += sum(result_dic[name])
# print(f'tag2: {name} , length2: {len(result_dic[name])}')
result_dic[name] = sum(result_dic[name]) / len(result_dic[name])
for name in pre_result:
for x in pre_result[name]:
if x:
if pre_labels[x[0]:x[0]+x[1]] == true_labels[x[0]:x[0]+x[1]]:
pre.append(1)
else:
pre.append(0)
total_precision = sum(pre)/len(pre)
return total_precision, result_dic
ģ��Ч��:
��ʹ��Ԥѵ��������
curren best val loss: 2.845144033432007
ʵ�弶ȷ��Ϊ: 0.0027247956403269754
��ʵ���Ӧ��ȷ��Ϊ: {
"NAME": 0.009708737864077669,
"TITLE": 0.002797202797202797,
"ORG": 0.0019267822736030828,
"RACE": 0.0,
"EDU": 0.0,
"CONT": 0.0
}
��ȷ�ʵ͵��㲻�ò���pycharmȥ���ԡ�����
�������˷���ȷʵ�ܵ�
�������������ݲ����°�:
text = "������,��ѧ����,��ҵ�ڶ���������ѧ,���塣"
���:
['B-NAME', 'O', 'O', 'O', 'B-EDU', 'M-EDU', 'M-EDU', 'E-EDU', 'O', 'O', 'O', 'O', 'B-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'E-ORG', 'O', '<end>', '<end>', 'O']
ʵ���ǩ
{'ORG': ['����������ѧ'], 'EDU': ['��ѧ����']}
ʹ��Ԥѵ��������
curren best val loss: 2.830146700143814
ʵ�弶ȷ��Ϊ: 0.002779708130646282
��ʵ���Ӧ��ȷ��Ϊ: {
"NAME": 0.009615384615384616,
"TITLE": 0.002894356005788712,
"ORG": 0.0019342359767891683,
"EDU": 0.0,
"CONT": 0.0
}
Ϊ�˸���˵������,���Ǹ���һ�²�������
text = "������,��ѧ����,��ҵ�ڶ���������ѧ,����,����������"
���:
['B-NAME', 'M-NAME', 'E-NAME', 'O', 'B-EDU', 'M-EDU', 'M-EDU', 'E-EDU', 'O', 'O', 'O', 'O', 'O', 'M-ORG', 'M-ORG', 'M-PRO', 'M-EDU', 'E-EDU', 'O', 'B-EDU', 'E-EDU', 'O', 'B-ORG', 'M-ORG', 'M-TITLE', 'M-ORG', '<end>']
{'NAME': ['������'], 'EDU': ['����', '��ѧ����']}
����ģ�Ͷ����,Ч���dz���
���������۲���Ԥ��Ľ��,����ѡȡһ����:
'M-ORG', 'M-ORG', 'M-PRO', 'M-EDU', 'E-EDU'
����:M-ORG��ǩ����˸�M-EDU��ǩ,��ϸ����,M��ǩ��Ӧ�ø�E��ǩ�Ŷ�,M��ǩ֮ǰӦ����B��ǩ�Ŷ�,BiLSTMģ��,��Ԥ���ǩʱȡ�������÷ֵı�ǩ,��ǩ���ǩ֮�䲻����Լ����ϵ,�������Ǵ���������ӿ��Կ���:��NER������,��ǩ���ǩ֮���Ǵ��ڹ�ϵ�ġ�
��������,����CRF���DZ�Ҫ�ġ�
2��CRF
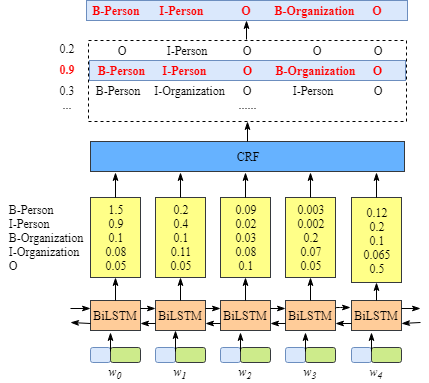
������,CRF����ʵ����һ�� out_size * out_size��С�ľ���,out_sizeΪ��ǩ������
CRF����������յ�Ԥ���ǩ����һЩԼ��,��ȷ����������Ч�ġ���ЩԼ��������CRF����ѵ�������д�ѵ�����ݼ��Զ�ѧϰ��
- �����е�һ�����ʵı�ǩӦ���ԡ�B-����O����ͷ,�����ǡ�M-��
- ��B-label1 M-label2 M-label3 E-label4��,�����ģʽ��,label1��label2��label3��label4Ӧ������ͬ������ʵ���ǩ������,��B-Person M-Person E-Person������Ч��,���ǡ�B-Person M-Organization������Ч�ġ�
- ��O M-label����Ч��һ������ʵ��ĵ�һ����ǩӦ���ԡ�B-�������ǡ�M-����ͷ,���仰˵,��Ч��ģʽӦ���ǡ�O B-label��
- ��
������Щ���õ�Լ��,��ЧԤ���ǩ���е��������������١�
������������������CRF����ģ�ʹ���:
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size, dropout, use_pretrained_w2v):
super(BiLSTM_CRF, self).__init__()
self.bilstm = BiLSTM(vocab_size, emb_size, hidden_size, out_size, dropout, use_pretrained_w2v)
self.transition = nn.Parameter(torch.ones(out_size, out_size) * 1 / out_size)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward(self, sents_tensor, lengths):
emission = self.bilstm(sents_tensor, lengths).to(self.device)
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(2).expand(-1, -1, out_size, -1) + self.transition.unsqueeze(0)
return crf_scores
���Կ���,ȷʵֻ�DZ�BiLSTM���˸�out_size*out_size��С��ת�ƾ���
����,����CRF������ʧ����,�Ͳ����ǽ�������ʧ�ˡ�����CRF�����ʧ����,����ʵ·���÷ֺ����п���·�����ܵ÷���ɡ������п��ܵ�·����,��ʵ·���ĵ÷�Ӧ������ߵġ�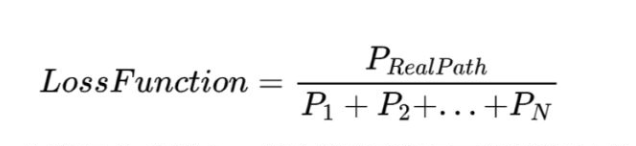
ѵ���Ĺ���,���������ʵ·�������п���·���ı�ֵ,һ�����Ǹ�ϰ�߽��������ת������С������,��Loss����ǰ�Ӹ����ż��������С�����⡣
����CRF Loss���������,����ϸ�����ݿ��Բο�-ͨ����!BiLSTM�ϵ�CRF,������ʵ��ʶ������������CRF,Ϊ�˱���ƪ������(��ʵ����),���ﲻ������
����CRF��Loss�������:
def cal_bilstm_crf_loss(crf_scores, targets, tag2id):
pad_id = tag2id.get('<pad>')
start_id = tag2id.get('<start>')
end_id = tag2id.get('<end>')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size, max_len = targets.size()
target_size = len(tag2id)
mask = (targets != pad_id)
lengths = mask.sum(dim=1)
targets = indexed(targets, target_size, start_id)
targets = targets.masked_select(mask)
flatten_scores = crf_scores.masked_select(
mask.view(batch_size, max_len, 1, 1).expand_as(crf_scores)
).view(-1, target_size*target_size).contiguous()
golden_scores = flatten_scores.gather(
dim=1, index=targets.unsqueeze(1)).sum()
scores_upto_t = torch.zeros(batch_size, target_size).to(device)
for t in range(max_len):
batch_size_t = (lengths > t).sum().item()
if t == 0:
scores_upto_t[:batch_size_t] = crf_scores[:batch_size_t,
t, start_id, :]
else:
scores_upto_t[:batch_size_t] = torch.logsumexp(
crf_scores[:batch_size_t, t, :, :] +
scores_upto_t[:batch_size_t].unsqueeze(2),
dim=1
)
all_path_scores = scores_upto_t[:, end_id].sum()
loss = (all_path_scores - golden_scores) / batch_size
return loss
def indexed(targets, tagset_size, start_id):
batch_size, max_len = targets.size()
for col in range(max_len-1, 0, -1):
targets[:, col] += (targets[:, col-1] * tagset_size)
targets[:, 0] += (start_id * tagset_size)
return targets
��������ֱ������BiLSM+CRFģ����NER�����ϵ�Ч��:
3��BiLSTM + CRF
��ʹ��Ԥѵ��������
ʵ�弶ȷ��Ϊ: 0.9232673267326733
��ʵ���Ӧ��ȷ��Ϊ: {
"NAME": 0.9905660377358491,
"TITLE": 0.9320261437908497,
"ORG": 0.8971119133574007,
"RACE": 1.0,
"EDU": 0.9298245614035088,
"CONT": 1.0,
"LOC": 1.0,
"PRO": 0.8125
}
ʵ�弶ȷ�������92.3%,��Ȼ,����CRF��֮��,ģ��ȷʵ��ѧ���˱�ǩ֮���Լ����ϵ��
��������:
text = "������,��ѧ����,��ҵ�ڶ���������ѧ,���塣"
���:
['B-NAME', 'M-NAME', 'E-NAME', 'O', 'B-EDU', 'M-EDU', 'M-EDU', 'E-EDU', 'O', 'O', 'O', 'O', 'B-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'E-ORG', 'O', 'B-RACE', 'E-RACE', 'O']
{'NAME': ['������'], 'ORG': ['����������ѧ'], 'RACE': ['����'], 'EDU': ['��ѧ����']}
Ч��ȷʵ����
ʹ��Ԥѵ��������
ʵ�弶ȷ��Ϊ: 0.9362229102167182
��ʵ���Ӧ��ȷ��Ϊ: {
"NAME": 1.0,
"TITLE": 0.951058201058201,
"ORG": 0.8969804618117229,
"RACE": 1.0,
"EDU": 0.9818181818181818,
"CONT": 1.0,
"LOC": 1.0,
"PRO": 0.8
}
ȷ�������1%,������
��������:
text = "������,��ѧ����,��ҵ�ڶ���������ѧ,���塣"
���:
['B-NAME', 'M-NAME', 'E-NAME', 'O', 'B-EDU', 'M-EDU', 'M-EDU', 'E-EDU', 'O', 'O', 'O', 'O', 'B-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'M-ORG', 'E-ORG', 'O', 'B-RACE', 'E-RACE', 'O']
{'NAME': ['������'], 'ORG': ['����������ѧ'], 'RACE': ['����'], 'EDU': ['��ѧ����']}
������������������Bert�����:
4��Bert + BiLSTM + CRF
ģ�ͽṹ:
class BertBiLstmCrf(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size, drop_out=0.1, use_pretrained_w2v=False):
super(BertBiLstmCrf, self).__init__()
self.bert_path = get_chinese_wwm_ext_pytorch_path()
self.bert_config = BeitConfig.from_pretrained(self.bert_path)
self.bert = BertModel.from_pretrained(self.bert_path)
emb_size = 768
for param in self.bert.parameters():
param.requires_grad = True
self.bilstm = nn.LSTM(emb_size, hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size*2, out_size)
self.dropout = nn.Dropout(drop_out)
self.transition = nn.Parameter(torch.ones(out_size, out_size) * 1 / out_size)
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward(self, x, lengths):
emb = self.bert(x)[0]
emb = nn.utils.rnn.pack_padded_sequence(emb, lengths, batch_first=True)
emb, _ = self.bilstm(emb)
output, _ = nn.utils.rnn.pad_packed_sequence(emb, batch_first=True, padding_value=0., total_length=x.shape[1])
output = self.dropout(output)
emission = self.fc(output)
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(2).expand(-1, -1, out_size, -1) + self.transition.unsqueeze(0)
return crf_scores
��BiLSTM + CRF���,Bert + BiLSTM + CRFֻ�ǽ�embedding�㻻����bert,�ڼ���loss��Ԥ��ʱ,��BiLSTM + CRF��һ��,û�κβ��������Ӧ�������Ԥѵ����������BiLSTM + CRFģ��Ч����ࡣ
����ֱ�����������:
����16��epochѵ����ɺ�õ���ģ��ȥ����ʵ�弶ȷ��,���,�����ˡ�����
curren best val loss: 179.17918825149536
/opt/anaconda3/lib/python3.8/site-packages/torch/nn/modules/rnn.py:694: UserWarning: RNN module weights are not part of single contiguous chunk of memory. This means they need to be compacted at every call, possibly greatly increasing memory usage. To compact weights again call flatten_parameters(). (Triggered internally at ../aten/src/ATen/native/cudnn/RNN.cpp:925.)
result = _VF.lstm(input, batch_sizes, hx, self._flat_weights, self.bias,
Epoch: 75%|������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������ | 15/20 [04:22<01:27, 17.52s/it]
Traceback (most recent call last):
File "main.py", line 10, in <module>
model_train.train(use_pretrained_w2v=use_pretrained_w2v, model_type=model_type)
File "BiLSTM-CRF-NER/src/train/train.py", line 82, in train
ner_model.train(train_word_lists, train_tag_lists, dev_word_lists, dev_tag_lists, test_word_lists, test_tag_lists, word2id, tag2id)
File "BiLSTM-CRF-NER/src/train/train_helper.py", line 87, in train
self.test(test_word_lists, test_tag_lists, word2id, tag2id)
File "BiLSTM-CRF-NER/src/train/train_helper.py", line 158, in test
total_precision, result_dic = precision(pre_tag_lists, tag_lists)
File "BiLSTM-CRF-NER/src/tools/get_ner_level_acc.py", line 86, in precision
total_precision = sum(pre)/len(pre)
ZeroDivisionError: division by zero
������˼����,ģ��һ����ǩҲû��ȷԤ�������
�п����Ǵ���ԭ��,�ۼ��ͬѧ����æ���ҡ�
emmm��
Ч���ܲ�,���dz������ϡ�
�����±����ģ�ʹ�С,�����Ѿ��ﵽ�˿�400M,�dz���
��BilSTM + CRFʹ��Ԥѵ����������ѵ��������ģ��,ֻ��13.4M�Ĵ�С��
��ʵ�ʵ�����������,ģ��Ч����ģ�ʹ�С֮����Ҫ��һ��ƽ��,��ʱ��,��ʹ��ģ��Ч������,����Ҳ��һ����ѡ���ģ�͡����Bert+BiLSTM+CRF��ģ�ͽ���BiLSTM+CRFȷ�ʲ�������ٷֱȵĻ�,�Ҹ�������BiLSTM+CRF��
�ܽ�
- ��ʹ��
BiLSTM��ѵ��NERģ�͵�Ч����Ȼ���֮��,�е�ˢ����֪,ԭ����Ϊֻ���е��,��û�뵽��ô��,ʵ�����֪�� - ��ʹ��ģ��ȷ�ʸ���,��Ҳ������ڴ�ռ��̫�������,ģ�ʹ�С��ģ��Ч����Ҫ�и�ƽ�⡣
ȫ�����뼰���ݼ����ϴ���Github,·����С�����Զ���С�ֵ�� star 🌟
����:https://github.com/seanzhang-zhichen/BiLSTM-CRF-NER
����Ҫ�Լ���ע���ݼ���ͬѧ,�Ƽ�ʹ��NER��ע����Label-Studio,�����÷����Բο�:����ʵ��ʶ��(NER)��ע��������Label Studio ��ʹ��
���������κδ�������Github����issue,���������κδ���ϣ����λ����ָ��,�dz���л���ı������🌹

