机器学习 Cifar图像分类竞赛
一、实验环境
PC机,Python
二、代码
#%%
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torch.optim as optim
import torchvision.models as models
import PIL.Image as Image
import os
#%%
image_size = (224,224)
data_transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
#%%
train_data=dset.ImageFolder(root="../input/cifar10",transform=data_transform)
# 数据集长度
totallen = len(train_data)
print('train data length:',totallen)
#%%
trainlen = int(totallen*0.95)
vallen = totallen - trainlen
train_db,val_db=torch.utils.data.random_split(train_data,[trainlen,vallen])
print('train:',len(train_db),'validation:',len(val_db))
#%%
# batch size
bs=20
# 训练集
train_loader=torch.utils.data.DataLoader(train_db,batch_size=bs, shuffle=True,num_workers=2)
# 验证集
val_loader=torch.utils.data.DataLoader(val_db,batch_size=bs, shuffle=True,num_workers=2)
#%%
def get_num_correct(out, labels):
return out.argmax(dim=1).eq(labels).sum().item()
#%%
batch = next(iter(train_loader))
#%%
batch[1]
#%%
import torchvision.models as models
resnext101= models.resnet.resnext101_32x8d(pretrained=True)
#%%
model = resnext101
n_classes = len(train_data.classes)
model.fc = nn.Linear(2048, n_classes)
#%%
import torch.nn.init as init
for name, module in model._modules.items():
if(name=='fc'):
# print(module.weight.shape)
init.kaiming_uniform_(module.weight, a=0, mode='fan_in')
#%%
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
#%%
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min',patience=1)
epoch_num = 12
model = model.to('cuda')
for epoch in range(epoch_num):
total_loss=0
total_correct=0
val_correct=0
for batch in train_loader:#GetBatch
images,labels=batch
images = images.to('cuda')
labels = labels.to('cuda')
outs=model(images)#PassBatch
loss=F.cross_entropy(outs,labels)#CalculateLoss
optimizer.zero_grad()
loss.backward()#CalculateGradients
optimizer.step()#UpdateWeights
total_loss+=loss.item()
total_correct+=get_num_correct(outs,labels)
scheduler.step(total_loss)
for batch in val_loader:
images,labels=batch
images = images.to('cuda')
labels = labels.to('cuda')
outs=model(images)
val_correct+=get_num_correct(outs,labels)
print("loss:",total_loss,"train_correct:",total_correct/trainlen, "val_correct:",val_correct/vallen)
#%%
torch.save(model, 'Cifar10-Resnext101_0.978.pkl')
#%%
import os
def file_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.png':
L.append(os.path.join(root, file))
L.sort()
return L
#%%
model = torch.load('Cifar10-Resnext101_0.978.pkl')
model.eval()
#%%
test_path=file_name('/ilab/datasets/local/cifar10/test')
#%%
model.to('cpu')
pre=[]
for i in range(9000):
filename=test_path[i]
input_image = Image.open(filename).convert('RGB')
input_tensor = data_transform(input_image)
input_batch = input_tensor.unsqueeze(0)
output = model(input_batch)
#print(output[0].shape)
prob = F.softmax(output[0], dim=0)
indexs = torch.argsort(-prob)
#if i%100==0:
print("i=",i," index:", indexs[0].item(), " prob: ", prob[indexs[0]])
pre.append(indexs[0].item())
#%%
with open('/home/ilab/submission','a') as f:
for i in range(9000):
f.write('%04d.png %s\n'%(i+1,train_data.classes[pre[i]]))
二、实验结果与分析
1、猎豹平台提交结果:
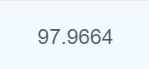
2、承接上文实验五垃圾分类,本文中所进行的操作大致与上文相同,但cifar-10图像分类数据集是远大于垃圾分类数据集的。因此,在平台上提交时会存在断联的情况,面对这种情况,我们按文件路径分批次进行预测保存。本文与垃圾分类的另一大区别在于的学习率的动态调整,scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,‘min’,patience=1)。
动态调整学习率的相关操作介绍

