报这个错误是embedding层的张量输入超过了合法范围,下标超了
原因
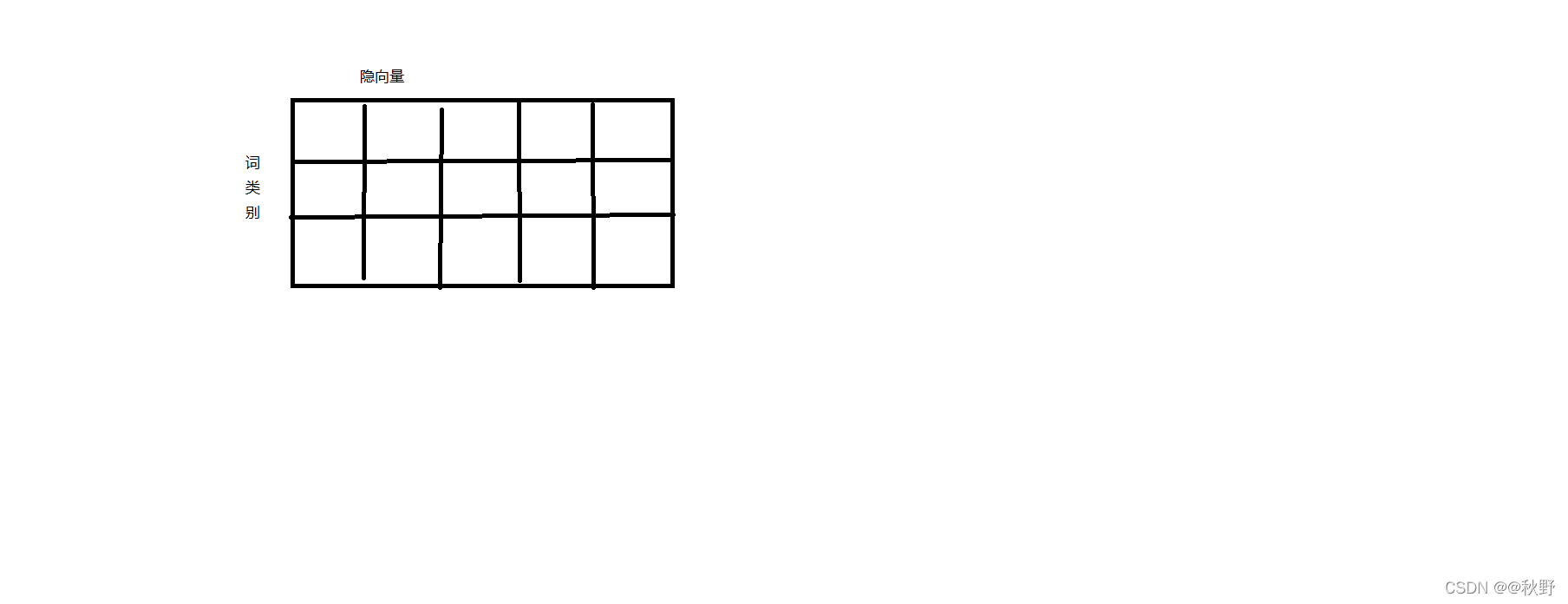
进行词嵌入(embedding)操作时,权重矩阵的每一行可以理解为字典中的每一个键,one-hot的各个类别,每一列为隐向量,相当于词的特征,字典中的值。
在输入时,只有数据是这个字典的键的时候才能找到对应的隐向量进行计算。
而键用下标表示的就是,输入数据的index在[0, num_embeddings-1](权重矩阵的行数-1)之间。
这就是embedding的结果,权重矩阵,下图为三行五列,三个词,每个词五个特征
验证
#查看embedding层
print(self.embed_layers)
(embed_0): Embedding(8, 4),八行四列,八个词,每个词四个特征
#查看输入数据最大下标
sparse_inputs[:, i].max()
tensor(6098),最大下标6098,大于8,超了
解决
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
nn.Embedding(num_embeddings=feat[‘feat_num’])检查输入数据列的顺序,是否和你embedding时列序一致

