1.зїепНщЩм
едвЛНЃ,Фа,ЮїАВЙЄГЬДѓбЇЕчзгаХЯЂбЇдК,2021МЖбаОПЩњ
баОПЗНЯђ:ЛњЦїЪгОѕгыШЫЙЄжЧФм,
ЕчзггЪМў:962022932@qq.com
СѕЫЇВЈ,Фа,ЮїАВЙЄГЬДѓбЇЕчзгаХЯЂбЇдК,2021МЖбаОПЩњ,еХКъЮАШЫЙЄжЧФмПЮЬтзщ
баОПЗНЯђ:ЛњЦїЪгОѕгыШЫЙЄжЧФм
ЕчзггЪМў:1461004501@qq.com
2.Ъ§ОнМЏНщЩм
ИУГЬађЭЈЙ§ЩњГЩШ§ИіВтЪдЕу,ЗжБ№ЮЊ(1,1,)(1,-1)(-1,-1),жЎКѓдкШ§ИіВтЪдЕужмЮЇИїЩњГЩ300ИібљБОЕузюжеБуаЮСЫAPдЫЫуЕФЪ§ОнМЏ
3.ЪЕбщДњТы
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
# ЩњГЩВтЪдЪ§Он
centers = [[1, 1], [-1, -1], [1, -1]]
# ЩњГЩЪЕМЪжааФЮЊcentersЕФВтЪдбљБО300Иі,XЪЧАќКЌ300Иі(labels_trueЮЊЦфЖдгІЕФецЪЧРрБ№БъЧЉx,y)ЕуЕФЖўЮЌЪ§зщ,
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5,
random_state=0)
# МЦЫуAP
ap = AffinityPropagation(preference=-50).fit(X)
cluster_centers_indices = ap.cluster_centers_indices_ # дЄВтГіЕФжааФЕуЕФЫїв§,Шч[123,23,34]
labels = ap.labels_ # дЄВтГіЕФУПИіЪ§ОнЕФРрБ№БъЧЉ,labelsЪЧвЛИіNumPyЪ§зщ
n_clusters_ = len(cluster_centers_indices) # дЄВтОлРржааФЕФИіЪ§
cluster_center = X[cluster_centers_indices]
print(cluster_center)
print('дЄВтЕФОлРржааФИіЪ§:%d' % n_clusters_)
print('ЭЌжЪад:%0.3f' % metrics.homogeneity_score(labels_true, labels))
print('Эъећад:%0.3f' % metrics.completeness_score(labels_true, labels))
print('V-жЕ: % 0.3f' % metrics.v_measure_score(labels_true, labels))
print('ЕїећКѓЕФРМЕТжИЪ§:%0.3f' % metrics.adjusted_rand_score(labels_true, labels))
print('ЕїећКѓЕФЛЅаХЯЂ: %0.3f' % metrics.adjusted_mutual_info_score(labels_true, labels))
print('ТжРЊЯЕЪ§:%0.3f' % metrics.silhouette_score(X, labels, metric='sqeuclidean'))
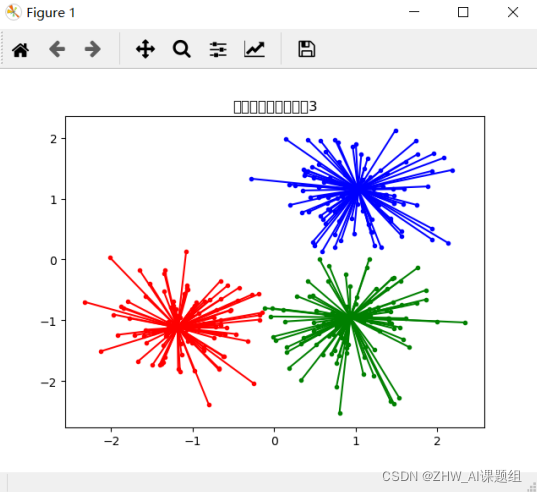
# ЛцжЦЭМБэеЙЪО
import matplotlib.pyplot as plt
from itertools import cycle
plt.close('all') # ЙиБеЫљгаЕФЭМаЮ
plt.figure(1) # ВњЩњвЛИіаТЕФЭМаЮ
plt.clf() # ЧхПеЕБЧАЕФЭМаЮ
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
# бЛЗЮЊУПИіРрБъМЧВЛЭЌЕФбеЩЋ
for k, col in zip(range(n_clusters_), colors):
# labels == k ЪЙгУkгыlabelsЪ§зщжаЕФУПИіжЕНјааБШНЯ
# Шчlabels = [1,0],k=0,дђЁЎlabels==kЁЏЕФНсЙћЮЊ[False, True]
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]] # ОлРржааФЕФзјБъ
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], markerfacecolor=col,
markeredgecolor='k', markersize=14)
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title('дЄВтОлРржааФИіЪ§:%d' % n_clusters_)
plt.show()
4.ЪЕбщНсЙћгыЗжЮі
зюжеЕФдЫааНсЙћЕФV-жЕЮЊ0.872,V-жЕЪЧЭЌжЪадКЭЭъећадЕФЕїКЭЦНОљЪ§,ЫќЕФШЁжЕЧјМфдк0-1жЎМф,жЕдНДѓЯрЫЦЖШдНИпЁЃЕїећКѓЕФРМЕТжИЪ§(ARI)ЮЊ0.912,ARIЕФШЁжЕЗЖЮЇЮЊ-1ЁЊ1,жЕдНДѓвтЮЖзХОлРрНсЙћгыецЪЕЧщПідНЮЧКЯЁЃДгЙувхНЧЖШЩЯРДНВ,ARIЪЧКтСПСНИіЪ§ОнЗжВМЕФЮЧКЯГЬЖШЁЃ
ДгвдЩЯСНзщЪ§ОнЗжЮіЕУжЊAPОлРрЫуЗЈЕФзМШЗЖШЪЧЯрЖдПЩППЕФЁЃ
дЫааЭМШчЯТ