DRConv(CVPR 2021)
本文提出了一种动态区域感知卷积Dynamic Region-Aware Convolution(DRconv)算法。它可以自动地将多个卷积分配给特征表示相似的空间区域,在local动态卷积的基础上引入了空间维度的分组。在提升性能的同时,还维持了一定的空间不变性。
引言
当前主流的标准卷积是在空间域上进行滤波器共享实现的(即同一个卷积通道),因此想要提取更丰富的信息只能通过增加通道层数实现。
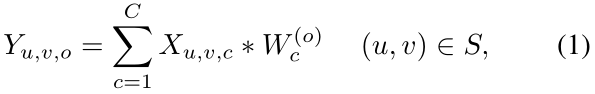
local convolution,卷积核在空间维度不共享,每个像素进行单独的处理,公式如下:
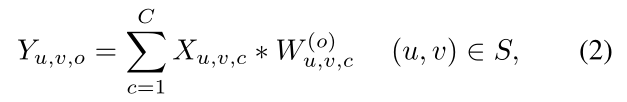
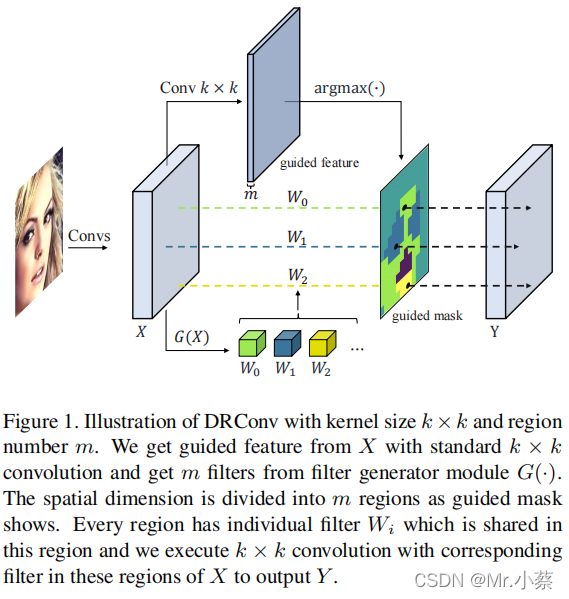
论文中,作者设计了一个可学习的引导掩码(Learnable guided mask)模块和滤波器生成模块(Filter generator module)。引导掩码模块将特征图划分为多个区域,滤波器生成模块根据输入图片动态生成每个区域的卷积核,卷积过程中将不同卷积核分配到不同区域中。
Our Approach
作者提出DRConv,首先定义了一个引导掩膜
M
=
S
0
,
?
?
?
,
S
m
?
1
M=S_{0},・・・,S_{m-1}
M=S0?,???,Sm?1?来表示空间维度划分的区域,在每个区域中共享一个滤波器。作者将区域中的滤波器表示为
W
=
[
W
0
,
?
?
?
,
W
m
?
1
]
W= [W_{0},・・・,W_{m-1}]
W=[W0?,???,Wm?1?],因此DRConv可以表示为:
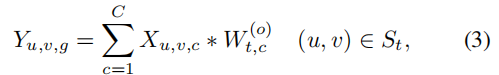
总的来说,DRConv主要分为两个步骤。首先,使用一种可学习的引导掩码模块将特征在空间维度上划分为若干个区域,如上图所示,引导掩码中具有相同颜色的像素被归到相同区域,类似于语义分割。
其次,在每个共享区域中,利用滤波器生成模块生成一个定制的滤波器,执行卷积操作。定制的滤波器可以根据输入图像的重要特征自动调整。
Learnable guided mask

可学习引导掩膜模块决定了滤波器在空间维度上的分布(哪个滤波器被分配到哪个区域),并通过损失函数进行优化,以便滤波器可以根据输入自适应地分配到相应位置。
假设需要有
m
m
m个区域地的
k
×
k
k×k
k×k滤波器。
首先使用
k
×
k
k×k
k×k卷积来生成
m
m
m个通道的引导特征,用
F
∈
R
U
×
V
×
m
F∈R^{U×V×m}
F∈RU×V×m表示。对于每个位置
(
u
,
v
)
(u,v)
(u,v),选取通道上最大值的索引。因此,引导掩膜取值在
0
到
m
?
1
0到m-1
0到m?1之间。
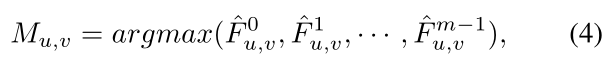
为了使引导掩码可学习,必须得到引导掩码的梯度。为了解决argmax无梯度的问题,作者提出了类似近似梯度的方法。
Forward propagation
获得引导掩膜(4)后,能得到每个位置
(
u
,
v
)
(u,v)
(u,v)的滤波器
W
^
u
,
v
\hat W_{u,v}
W^u,v?:
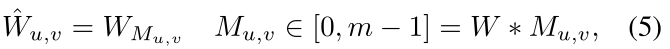
其中
W
M
u
,
v
W_{M_{u,v}}
WMu,v??是由滤波生成器生成的滤波
[
W
0
,
?
?
?
,
W
m
?
1
]
[W_{0},・・・,W_{m-1}]
[W0?,???,Wm?1?]中的其中之一。m个滤波器于所有位置建立对应关系,并将整个像素空间划分为m个组。
Backward propagation
作者定义
F
^
\hat F
F^,它是在反向传播时用来代替one-hot掩码的形式:
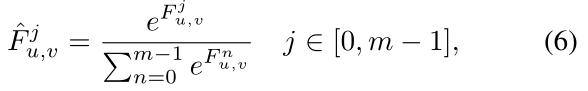
本质上是个softmax,作者通过在通道维度上进行softmax,期望
F
^
\hat F
F^尽可能接近
0
?
1
0-1
0?1。
F
^
\hat F
F^的梯度如下:
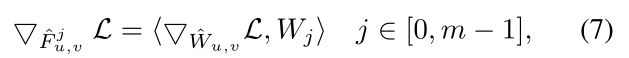
结合(6)可以得到
F
F
F最后的梯度:
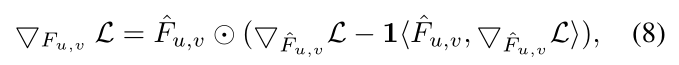
Dynamic Filter: Filter generator module
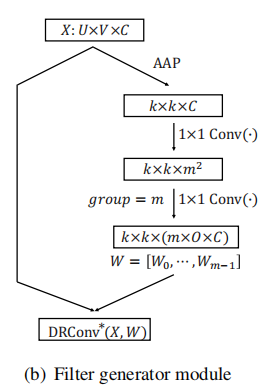
卷积生成模块主要包含两个卷积层,卷积核为
1
×
1
1×1
1×1。
首先通过自适应平均池化得到
k
×
k
×
c
k×k×c
k×k×c的特征图,之后使用两个
1
×
1
1×1
1×1的卷积。第一个卷积后接sigmoid激活函数,第二个卷积采用分组卷积,group=m,后面不加激活函数。如图(b)所示,分别根据每个样本的特征预测卷积滤波器。因此,每个滤波器都可以根据其自身的特性进行自动调整。
实验结果
总结分析
改论文实际上是利用了特征图的空间特性显著提升了网络性能,缺点是非常不利于并行优化(batchsize的并行可以通过group 卷积实现),对硬件也非常不友好。

