
ժҪ:
����ͼ������(GNN)�ڸ߽���ͨ��ѧϰ��ʾ���������,����GNN��Эͬ�������Ƽ�ϵͳ�еõ��˹㷺��Ӧ�á�����,Ϊ�˿˷�����ϡ��������,���һЩ����GNN��ģ�ͳ��Խ��罻��Ϣ��������,����ƶԱ�ѧϰ��Ϊ��������,��Э����Ҫ�Ƽ��������е�GNN�ͻ��ڶԱ�ѧϰ���Ƽ�ģ���ԶԳƵķ�ʽѧϰ�û�����Ŀ��ʾ,���Ը��ӵķ�ʽ���������Ϣ�ͶԱ�ѧϰ���������ֲ��Ե�����Щģ��Ҫô�����û�����Ŀ֮�����ز�ƽ������ݼ���Ч,Ҫô�����û�����Ŀ̫������ݼ�Ч�ʵ��¡����������,���������һ���Ա�ͼѧϰ(CGL)ģ��,����һ�ּ�ǿ��ķ�ʽ������罻��Ϣ�ͶԱ�ѧϰ��CGL������ģ�����:������readout��Ԥ�⡣����ģ��ݹ�ؾۺϺͼ����罻��Ϣ����Ȥ��Ϣ,��ѧϰ�û�����Ŀ�ı�ʾ�����ģ�齫���д�������û�Ƕ��ƽ��ֵ�����һ�����������ĿǶ��ƽ��ֵ�ֱ���Ϊ�û�����Ŀ�������Ԥ��ģ��ʹ����Ȥͼ����Ԥ��������ǿ����Ȥ��Ϣ����������ֲ�ͬ����ʧ��ȷ��ÿ��ģ��Ĺ��ܡ������������ݼ��Ͻ����˴�����ʵ��,��֤�˸�ģ�͵���Ч�ԡ�
1 ����
��������Ŀ��ٷ�չ,�û�Խ��Խ�ѴӴ�����������Ϣ����ȡ���õ���Ϣ���Ƽ�ϵͳ�ڽ����һ�����з�������Ҫ������,���ѳ�Ϊ�ڵ��������罻ý���������������߾���Ч���һ������ǰ;�Ľ���������Ƽ�ϵͳ����Ҫ������Ϊÿ���û��ṩ����Ȥ����Ŀ,��Ϊ�û���ʡ�˴�����ʱ��,�����˹�˾����ת�ʡ������е��Ƽ�����֮һ��Э������(CF),�����������û���Э����Ϊ���ƶ�ÿ���û�����Ŀ����Ȥ,������Ҫ��ʽ���û�����Ŀ������Ϣ������ֽ�(MF)�Ǵ������ѧϰ��CFģ�͵Ĺؼ���ɲ���,�����û�-��Ŀ��������ֽ�Ϊ������άDZ�ھ���,�����û�����Ŀ��ʾ[6]��Ȼ��,����Э���źŲ���,����MF��ģ�Ͳ�û�ж��û�����ĿǶ����б��롣Ϊ�˻�úõ�CFǶ��,һ��ͼ������(GNN)[7]�ѳɹ���Ӧ�����Ƽ�ϵͳ[8�C10]������GNN[11]�ĸ߽���ͨ��,����GNN��ģ�Ϳ��Դӷḻ����ʷ�������ھ�����߽��ھ����ڵ�Э���ź�;���,���������ɸ�ǿ��Ľڵ��ʾ��������ʵ����ij�����,���Ǻ����ռ����㹻����ʷ������Ϣ��Ϊ�˿˷�����ϡ���Ե�����,������ǰ��CFģ��[12�C14]���罻��Ϣ����ʷ������Ϣ�������,�Ӷ�������Ƽ�������������,Ϊ�˽�һ���������ϡ��������,�����о����Լලѧϰ�����Ƽ�ϵͳ�������е��Լලѧϰ�����ǶԱ�ѧϰ,���ѳɹ���Ӧ�����������Ա�ѧϰ�ԶԱȵķ�ʽ�����Լල�ź�,����������Ŀ��Ƕ������,������������Ŀ��Ƕ���ƿ���Ϊ�˻�ø��õ��Ƽ�����,�������е��Ƽ�ģ��[19�C21]ͨ��GNN��ܶԽڵ�Ƕ����б���,����ѧϰ������ͬʱ���öԱ�ѧϰ����Ȼ��Щģ�ͽ����罻�Ƽ�����Ϊ��Ŀ��֮һ,��������Ȼ�����¹��еľ�������Ҫ�����
����,���еĻ���GNN��ģ��[11,22]����ͬ�ķ�ʽѧϰ�û�����Ŀ�ı�ʾ,���������û�����Ŀ�IJ�ͬϡ����������ʵ������,�û�����Ŀ��������ϡ����ͨ���Dz�ͬ��������,��Flickr���ݼ�[23,24]��,��Ŀ�������������û���10����������ϡ�����ϵľ����,��ѧϰ�ο��Ա���Ŀ����ػ�ø��������û���ʾ�����,����ͬ��ʽѧϰ���û�����Ŀ�ı�ʾ���ܻή��Ƕ������,�Ӷ�����ģ�͵��Ƽ�������
���,��ȻһЩ�罻�Ƽ��о��Ѿ�Ŭ�����Ա�ѧϰ���罻��Ϊ�������,�������Խ��Ա�ѧϰ�ʵ���Ӧ�õ��罻�Ƽ��С�һ����,���е�����Ƽ�ģ��[19,25]��һ���൱���ӵķ�ʽ���öԱ�ѧϰ,����볬ͼ��������ǿ�����ָ��ӵķ�ʽ���ܻ��ƻ�ԭ�е����ͼ�ṹ,�˷��罻��Ϣ����һ����,���е�����Ƽ�ģ��[19,25]��Ԥ������в�û��ֱ�����������Ϣ,����ܻ�����罻��Ϣ��Ӱ�졣��֮,���еĶԱ���ѧϰ��ʽ�������罻�Ƽ�ģ�͵ĸ�����,����û�г�������罻��Ϊ����������������Ϣ��
����̽������ο˷����еĻ���GNN�ͶԱ�ѧϰ���Ƽ�ģ�͵�����������,�������һ����������Ƽ��ĶԱ�ͼѧϰ(CGL)ģ�͡����罻�Ƽ�ϵͳ��,ÿ���û����������ھ�:��ʷ������Ŀ�ͽ����û���һ����˵,������ƫ�õ��û����п��ܳ�Ϊ���ѡ�ͬ����,���ܵ�����ͨ��Ҳ�����Ƶ�ƫ�á����,ͨ����Ŀ�ۺϺ����Ѿۺ�������ÿ���û���ƫ���Ǻ�����,��Ҫ���������ͼ(�û�-��Ŀͼ���û�-�û�ͼ)��ѧϰ���û���ʾ����һ����������۵��ʹ���Ǽ����罻�û�Ƕ�����Ȥ�û�Ƕ��֮��ĶԱ�ѧϰ����������,Ϊ��ȷ���罻�û�Ƕ��Ҳ������Ԥ�����,�����ܵ�һЩ����ģ�͵�����,��һ�ִ����ķ�ʽѧϰ�û�Ƕ�롣����ɢ�����е�ÿһ��,ͨ��ȡ����û�����Ȥ�û�Ƕ���ƽ��ֵ,�õ����ɵ��û�Ƕ��������,Ϊ�˱����û�����Ŀ[27]�IJ�ͬϡ���Ե�����Ӱ��,���������һ������û�����Ŀ�ķǶԳ�readout����,�ֱ����д�������û�Ƕ���ƽ��ֵ�����һ�����������ĿǶ����Ϊ������������ǵ�ģ�͵�������Ϊ�û��ҳ����ʵ���Ŀ,�������ھ�DZ�ڵ��罻����,����������ģ�͵����Ϊ���յľۺ�������һ���������Ȥͼ�����,ȷ����ʷ�ϵĻ�����Ϊ���罻��Ϊ���Ƽ������Ӱ������Ƿdz���Ҫ�ġ�
��������,����������Ҫ��������:
- ���Ƽ�ϵͳ��,����ͨ���Ա�ѧϰ�ɹ��ؽ��罻��Ϣ�뽻����Ϣ����,����������Ƽ������������
- ���������һ���µ�readout�����������û�����Ŀϡ���ԵIJ�ƽ������,�ò����ֱ������������в���û�Ƕ���ƽ��ֵ�����һ�����ĿǶ���ƽ��ֵ��Ϊ�����
- �����ԶԱȵķ�ʽ�����û�����Ŀ֮��������ʧ,�ṩ�������������������ǽ�����ʧ�ͳɶ���ʧ���ڲ�ͬ��ģ����,�Խ�һ������Ƽ����ܡ�
- ������������ʵ���ݼ��Ͻ������ģ����6�����Ƚ��Ļ��߽��бȽ�,ʵ����֤�������ǵ�ģ�͵���Ч�ԡ�
���ĵ����ಿ����֯���¡���2���ܽ����Ƽ�ϵͳ�е�һЩ��ع�������3�ڽ����˱�Ҫ�ķ���,�����������ǵ�ģ�͡��ڵ�4����,���Ǹ�����һЩʵ��������֤�������ģ�͵���Ч��,�������˳�������Ӱ�졣��5���ܽ������ǵĹ���,��������δ�������п��ܴ��ڵ�һЩ���⡣
2 ��ع���
���Ǽ�Ҫ�ع��˻���MF���Ƽ�ģ�ͺͻ���GNN���Ƽ�ģ�͡�
2.1 ����MF���Ƽ�
���Ƽ�ϵͳ��,���ྭ���Эͬ�����㷨�����ھ���ֽ�(MF)[28]�ࡣ����MF��ģ�ͽ��û�����ĿͶ�䵽һ����ά��DZ�ڿռ���,��ͨ��һ������[29]����ʾһ���û���һ����Ŀ���û���������Ŀ�������ڻ���ʾ�û�����Ŀ�������������MF��ģ�����Ƽ�ϵͳ�еõ��˹㷺��Ӧ�á�SocialMF[30]���罻������ʹ����MF����,������ÿ���û�����������������/����ֱ���ھӡ�����ÿ���û�������������Ӧ�����罻�ھӱ���һ�¡�TrustMF[31]���������д�����˫��Ӱ��,�����������ߺͱ�������֮��IJ�ͬ���塣Ϊ�����������ֶ����ܵIJ�ͬӰ��,TrustMF�������һ���ۺϲ���,��������ģ���뱻������ģ��[32]���ϡ�NeuMF[33]�ǵ�һ����MF��������������ķ��������ϵ�ģ�͡��������Ԥѵ�������ֲ�ͬģ������е���Ҫ��,�Ȼ���MF��ģ�ͺͻ������������(DNN)��ģ�;��и��õ����ܡ�DASO[34]ͨ��ʹ������ʽ�Կ�����(GAN)[35]��̬��ѧϰ�û�����Ŀ�ı�ʾ��
2.2 ����GNN���Ƽ�
������,GNN���Ƽ������Ѿ�չ�ֳ�������Ч�ԡ�GNN��Ŀ����ѧϰÿ���ڵ��Ƕ��,���а����ھ�[36,37]����Ϣ����Ϊ���GNN,LightGCN[22]�����ھӾۺ�֮��û���κθ��ӵIJ���,������Ȼ�ﵽ�����Ƚ����Ƽ����ܡ�GraphRec���״����罻�Ƽ�ϵͳʹ��GNN���ڸ�ģ����,ע�������Ʊ��㷺��Ӧ���ھۺ��ھ���Ϣ���ھۺϹ���֮��,����ͨ�����û�����ĿǶ�뵽DNN����������֡�ConsisRec[39]����ͬ���罻��ϵ��������,�����仮��Ϊ�����IJ��ϵ�㡣Ϊ�˽�������IJ��ϵIJ�ͬ��,ͨ�������ھ�Ƕ�����ѯǶ��֮��ľ���õ�һ���Ե÷�,Ȼ����������һ���Է��������,��һ�����ھӽ��в�����Ȼ��,����ע���������ڹ�ϵ�����Ͻ����һ�������⡣ DiffNet++[24]������һ��ͳһ�Ŀ���������罻��������Ӱ�����Ȥ�������ȤӰ�졣���������罻�������Ȥ�������Ϣ���������,����������Իع�ķ�ʽ���ղ�ͬ����Ϣ,�Ӷ�ѧϰ����ǿ���ͼ�ڵ��ʾ��SGL[26]���Ƚ��Ƽ�����Ա�ѧϰ,�����GNN�Ƽ���ȷ�Ժ�³���ԡ�SGLͨ���Բ�ͬ�ķ�ʽ�ı�ͼ�Ľṹ�����ɾ��в�ͬ��ͼ��ͼ,Ȼ�����ô���Щ��ͼ���ɵļල�ź�������һ���������Լලѧϰ����SEPT[19]���������罻�Ƽ����ϵĶԱ�ѧϰ����ͨ��������ǿ���ܹ�����������ͬ����ͼ,����ÿ����ͼ����������ͼ�ṩ�˼ල�źš����״β��öԱ�ѧϰ�ķ��������罻�Ƽ�,�ֱ��Ƽ�ѧϰ�ͶԱ�ѧϰ��Ϊ��Ҫ�����������
3 CGLģ��

�ڱ�����,���ǽ��������ǵ�CGLģ�͡�ͼ1չʾ��CGL�ĸ���,����һ���û���һ����ĿΪ����CGL���������в�ͬ���ܵ�ģ����ɡ�
- ��һ����һ������ģ��,������Ȥ�������罻��ϵ֮�佨����ϵ,���Եݹ�ķ�ʽ���б�ʾѧϰ��
- �ڶ��������ģ��,���Բ��ԳƵķ�ʽ�����û�Ƕ�����ĿǶ��,�Ա����û�����Ŀ�IJ�ƽ�����⡣
- ��������һ��Ԥ��ģ��,��Ϊ�û������Ƽ���
�ڵ�3.1���ж�����һЩ��Ҫ�ķ��š���3.2�ڡ���3.3�ں͵�3.4�ڷֱ�����˴���ģ�顢���ģ���Ԥ��ģ�顣��ģ�͵�ѵ����������3.5�ڡ����,�ڵ�3.6���з�����CGL�ĸ����ԡ�
3.1 ����

3.2 ����ģ��
����ģ����L��,ÿһ�㶼����Ȥͼ�ۺϡ��罻ͼ�ۺϼ������ǵ�������ɡ���һ��������dz�ʼ�����û�DZ��Ƕ�� u ( 0 ) i u^(0)_i u(0)i?����ĿDZ��Ƕ�� v ( 0 ) j v^(0)_j v(0)j?,����������������Ǹ��Ե�ǰһ�����������������зֲ������ͼ��,�ݹ��ȥ��ģ�û���DZ��ƫ�ú���Ŀ��DZ��ƫ�á�LightGCN[22]��һ������ͼ��������(GCN)��ͨ���Ƽ�ģ��,��������GCNs�е�����������:�����任�ͷ����Լ����������LightGCN��CGL��ʵ�־ۺϲ�����
Ϊ������ȤͼGr�оۺϽ�����Ϣ,����ͨ��LightGCN�ķ����ۺ�ÿ���ڵ���ھ���Ϣ��������˵,���ڸ������û�i����Ŀj,�� u i ( l ? 1 ) u_i^{(l-1)} ui(l?1)?�� v j ( l ? 1 ) v_j^{(l-1)} vj(l?1)?�ֱ��ʾ���Ե�(l?1)����û�Ƕ�����ĿǶ�롣��l����Ȥ�ۺϹ������¡�
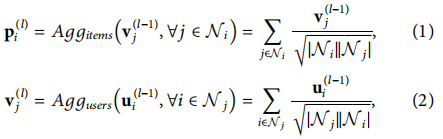
����,
N
i
N_i
Ni?�����û�i��������Ŀ����,Nj������Ŀj�������û����ϡ�LightGCN�������GCNs[40]��ͬ�Ĺ�һ������,���ھۺ���Ϣʱʹ�õ�ǰ�ڵ�;ۺϽڵ���ھ��������й�һ�����ò��Զ��ڱ�����ͼ����������Ƕ��IJ������������൱��Ҫ�ġ�
Ϊ�˾ۺ��罻ͼ
G
s
G_s
Gs?���罻��Ϣ,����Ҳ�����˻���LightGCN�Ľڵ�ۺϡ���ע��,���罻ͼ��ֻ���û��ڵ㡣��
u
i
(
l
?
1
)
u_i^{(l?1)}
ui(l?1)?������(l?1)����û�Ƕ��,
T
i
T_i
Ti?���û�i�����ӵ��罻�ھӼ��ϡ���l������ۼ����̱�����Ϊ
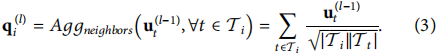
����ʽ��ʾ,LightGCNͨ��ȡ��ǰ�ڵ�;ۺϽڵ���ھ��������й�һ����
��Ȥͼ�ϵľۺ������û�Ƕ��
p
i
(
l
)
p_i^{(l)}
pi(l)?,�罻ͼ�ϵľۺ������û�Ƕ��
q
i
(
l
)
q_i^{(l)}
qi(l)?���������û�Ƕ������˹����û�i�IJ�ͬ��Ϣ,����һ������,���ڵ�l�������û�Ƕ��
u
i
(
l
)
u_i^{(l)}
ui(l)?�����Ǽ�ͨ��ȡ
p
i
(
l
)
p^{(l)}_i
pi(l)?��
q
i
(
l
)
q^{(l)}_i
qi(l)?��ƽ��ֵ�������ǽ��м��ɡ������ڵ�l��õ��˼��ɵ��û�Ƕ��Ϊ:

Ȼ���ɵ��û�Ƕ��
u
i
(
l
)
u_i^{(l)}
ui(l)?�;ۺϵ���ĿǶ��
v
j
(
l
)
v_j^{(l)}
vj(l)?���뵽(l+1)��,�Ӷ�����Ȥ���罻��Ϣ������ͼ�д�����ͨ����ÿһ�㼯���罻�û�Ƕ�����Ȥ�û�Ƕ��,���ǿ����������¼��ɵ��û�Ƕ�롣���,�罻��Ϣ����Ȥ��Ϣ֮����ں��ھ��������б��Խ��Խ���ܡ�����,��Ȼ��ĿǶ��û�в��봫������,������GNN�еĸ߽���ͨ��,�罻�û�Ƕ�����ĿǶ����Ȼ���������ǿ���Ӱ��,�ر��ǵ���������Խ��Խ��ʱ��
CGL�Ĵ����������ܵ�����ģ��DiffNet++����Ч�Ե�����,������DiffNet++Ҫ���öࡣ��DiffNet++��ͬ,CGL�����û�����Ŀ���������������������κ���Ϣ�������κ�ע�������ơ�ǰ�߽��������Ǵ�����ʱ����������������,�����߽�ʹ��DNNs�����,���ǵ���ɢ���̵�ʱ�临�Ӷȱ�DiffNet++Ҫ�͡�
3.3 readoutģ��
�ھ���L����ɢ����֮��,���Ƿֱ�Ϊ�û�����Ŀ����readout����,Ȼ����Щ������͵�����Ԥ��ģ���е����һ����Ȥͼ�����ǹ���readout�IJ��Բ�ͬ�����еĻ���GNN���Ƽ�ģ�͡������еĻ���GNN��ģ����,�����ֲ��Կ���ΪԤ��λ�������������Ƕ�롣һ����ȡ�û�����Ŀ�����в��Ƕ��ƽ��ֵ,��һ����ȡ���һ���Ƕ��ֵ�������ֲ��Զ��ԶԳƵķ�ʽ�����û�����Ŀ,��ѵ�������е��û�����Ŀ�����кܴ�IJ�ͬ,�����ģ����ѧϰ�û�����Ŀ�����ñ�ʾ��Ϊ�˻�����һ����,���ǽ������ֲ��Խ������,�����û�����Ŀ��readout,���û�����ǰ��,����Ŀ���ú��ߡ������罻��Ϣ�Ĵ���ʹ��,�û�Ƕ������ɢ���̵�ÿһ���ж�����Э���ź�,���������û�Ƕ������������,����ɢ���̵����ڽξͿ������ɸ��������û���ʾ���������������ɢ������ʹ�����е��û�Ƕ���������û���readout��������˵,�û�i��readout
u
i
u_i
ui?������Ϊ��������������L��Ƕ���ƽ��ֵ:
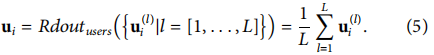
����һ����Ŀ,������Ŀ������ϡ�衢ȱ��������Ϣ,������ɢ�������ڵ�Ƕ����ܽϲ���,��Ŀj��readout
v
j
v_j
vj?������Ϊ���ڴ������̵������һ���Ƕ��:
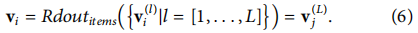
�ӵ�ʽ5�͵�ʽ6�п��Կ���,���Ƕ��û�����Ŀ��readout�����Dz��ԳƵġ�
3.4 Ԥ��ģ��
���ǵ��Ƽ���������Ԥ���û�����Ŀ֮��Ľ���,����������һ����������Ȥͼ��ǿ�����ǵ����֮��Ľ�����Ϣ��Ӱ�졣�ֱ�ͨ������Ȥͼ�оۺ�
u
i
S
��
u_iS��
ui?S��v_jS���������յ��û�Ƕ��$ ^
u
i
u_i
ui?����ĿǶ��$^
v
j
v_j
vj?��������ʾ:
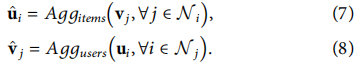
Ȼ��,Ԥ��ģ�鶨���������û�����ĿǶ��֮����ڻ���

���ڻ���Ϊ���������������Ƽ���
3.5 ģ��ѵ��
Ϊ��ѵ����ģ��,��������˴���ģ����Լල��ʧ��readoutģ���Ԥ��ģ��ļල��ʧ���ڴ���ģ���ÿһ��,��Ȥͼ���罻ͼ�ֱ�Ϊÿ���û����������û�Ƕ�롣Ϊ��ʹ�����ǵļ��ɸ��Ӻ���,���������һ���Լල��ʧ��ʹ��ͬһ�û�������Ƕ���������û�����Ŀ���Ƽ�ϵͳ����������,���ǿ���Ϊ�������û��Ƽ���Ŀ,Ҳ����Ϊ��������Ŀѡ���û�����������������,���Ƿֱ������readoutģ���Ԥ��ģ��ļල��ʧ��ͨ�������Ż�����������ʧ,ȥѧϰģ���еIJ�����
3.5.1 �Լල��ʧ
����ͨ����ʽ4,�ڴ������̵�ÿһ���м������罻�û�Ƕ�����Ȥ���û�Ƕ�롣����ֱ�Ӽ��ɲ��Կ���ʹ����Ƕ�����������,�����ܱ�֤������ѵ����������˽������,�����ڴ���ģ����������һ���罻�Ա�ѧϰ��ʧ������Ҫ˼���������罻��Ϊͨ�����Է�ӳ�û���ƫ�õļ��衣���,�û��罻ͼ�е�Ƕ��Ӧ������Ȥͼ�е�Ƕ����������ϵ��

����,r(��)Ϊ���Ҳ�������ô�û�Ƕ�����ĵ�i�п������û�i��DZ��Ƕ��,����ĿǶ�����ĵ�j�п�������Ŀj��DZ��Ƕ�롣���,�����û�i����Ŀj,���ǿ��Դ�P�еõ���Ȥ�û�Ƕ��
p
i
p_i
pi?,��Q�еõ���ʵ�罻�û�Ƕ��
q
i
q_i
qi?,��~ Q�еõ����罻�û�Ƕ��~
q
i
q_i
qi?�����Ǽ�����ٵ��罻�û�Ƕ��������Ӧ����Ȥ�û�Ƕ���кܴ�IJ�ͬ�����ǽ�ÿ���ٵ�����û�Ƕ�������Ӧ����Ȥ�û�Ƕ��֮���һ������С��,�����ڴ���ģ���е��罻�Ա�ѧϰ��ʧ���Ա�ʾΪ:
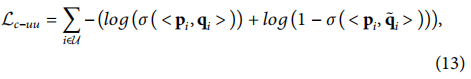
3.5.2 �ල��ʧ
��Ԥ��ģ����,���ǿ���ͨ����ʽ9�õ����ַ���.Ϊ��ȷ���۲쵽�Ľ�����δ�۲쵽�Ľ�����ø��ߵķ���,����ʹ�óɶԱ�Ҷ˹���Ի�����(BPR)��ʧ��Ϊ���ǵ���Ҫ��ʧ������ģ��ѧϰ,����Ϊ��ʹ�۲쵽�Ľ���������δ�۲쵽�Ľ���ǰ�档CGL�е�BPR��ʧ�Ĺ�ʽΪ:
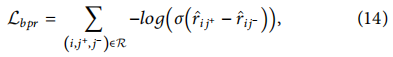
ͨ����С��BPR����ʧ,һ���۲쵽�Ľ������õ�Ԥ��������Ա�ǿ��ִ��Ϊ������δ�۲쵽�Ķ�Ӧ�Ȼ��,��Ϊ��������ʧ,��������Ԥ���������ʵ����֮���һ���ԡ�����,BPR��ʧֻ���������û��ṩ������������,�����Ŀ�Dz���ƽ��,ʹ�ú���ѧϰ�õ���Ŀ��ʾ��
Ϊ�˿˷����ȱ��,���Dz��������ʧ��ΪBPR��ʧ�IJ���,�������ʾΪ:
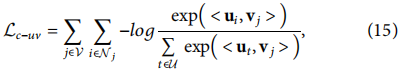
����,ÿ��
u
i
u_i
ui?��
v
j
v_j
vj?�ֱ��ɷ���ʽ5�ͷ���ʽ6��������Ȼ,������ʧΪһ����������Ŀ�ṩ�����ĺ��ļල�ź�,������һ���������û���ͨ����С����ʽ15,Ԥ�������������ʵ������һ�¡�ֵ��һ�����,������readoutģ���ж�������ʧ,��������Ԥ��ģ���С������������е��칹��ʧ��ͬ,����ͨ�������Ԥ��ģ���е������ʧ�ͳɶ���ʧ����Ҫԭ��������ͨ��ʹ�ò�ͬ���û�����Ŀ��ʾ������Ԥ��������������������ʧ��ע�ڸ�����Ŀ���û�,����ǿ��ֱ����������Ȥͼ�����ͼ�ϵľۺϲ������û���ʾ����Щ��ǿ���û�����Ŀ��ʾ�����ھۺ������������Ȥͼ�ϵ���Ϣ��
3.5.3 ���յ���ʧ
����CGLģ�͵�����ģ���е�����������ʧ,���ǽ���������ʧ��Ϊ:
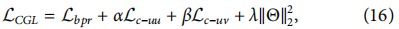
����,���ͦ������������������,�ֱ����Lc?uu��Lc?uv��ǿ��;�������п�ѧϰ�����ļ���;�˿�����L2����ǿ�ȡ����㷨1�и�����CGL������ѵ�����̡�


