1.UniFormer简介
官方网站自行查看,根据INSTALL.md安装环境,根据DATASET.md准备数据。
为防止该项目GG,我把源码下载到阿里云盘,但是该类型不能分享,只能用万恶的百度云盘
链接: https://pan.baidu.com/s/1tLpQcDiqOo9KtC66K6aGkw?pwd=qz4h 提取码: qz4h 复制这段内容后打开百度网盘手机App,操作更方便哦
2.部署
- 安装conda环境,
conda create -n lyv2 python=3.9 -y- 激活conda环境
conda activate lyv2- 到pytorch官网找到适配自己cuda的安装命令,我的cuda有10.2,于是我安装
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html(你自己要配好cuda的环境变量,版本一定要对得上)
- 使用conda list查看环境
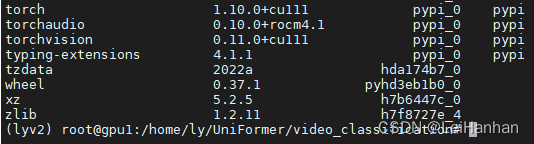
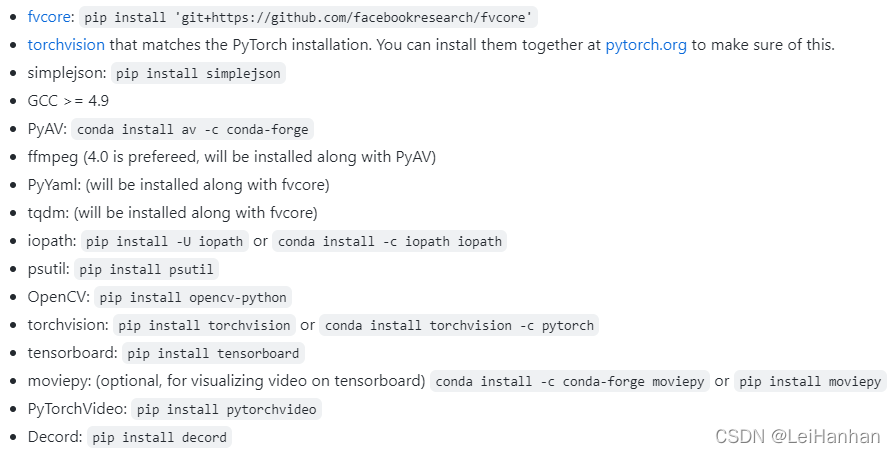
- 接着照着?INSTALL.md安装相应的库(注意,不要死板的全部命令都执行,像我使用上面那句安装torch的代码就安装了torchaudio和torchcision,就没必要执行有关torchaudio和torchvision的命令了)
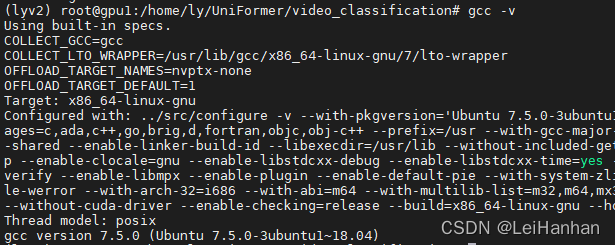
- ?其中GCC可以通过gcc -v来查看是否有GCC
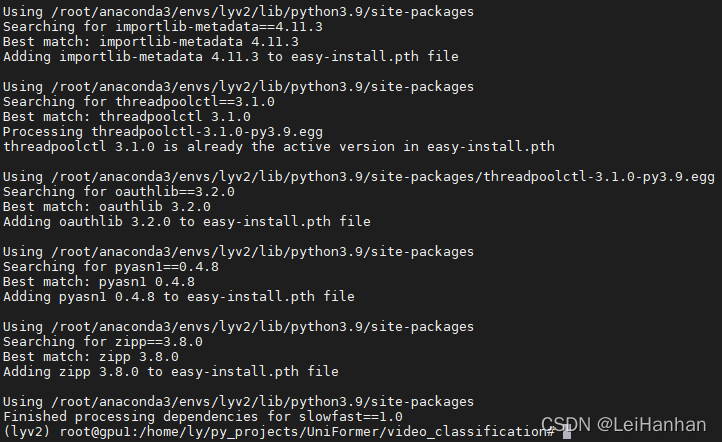
- 上面的依赖库安装好后就下载UniFormer(命令可以一条一条执行)【注意:git clone就是下载网址的文件也就是UniFormer这个源码,所以你先进入一个目录再执行这条命令,这样你就把UniFormer下载到这个目录里面了。cd 就是进入你下载的UniFormer下的video_classification目录。python就是执行这个setup.py文件部署UniFormer】
git clone https://github.com/Sense-X/UniFormer
cd UniFormer/video_classification
python setup.py build develop如果中途由于网络连接的原因出错,重装相关的,多装几次。

成功
3.下载数据集、配置参数、运行执行脚本
没必要下载训练的数据集【因为已经有训练好的pth了,所以没必要再训练了,而且据他所说和我自己的实践,训练和测试会非常慢!!!单GPU和CPU根本跑不动】
下载测试集即可:根据他提供的,k400的测试集一共有19787条。华为那边给我的数据集只有19760条,将就着用吧!【不好到youtube上面扒数据,有的视频已经扒不了了,而且我之前在网上找了个数据集只有19404条】
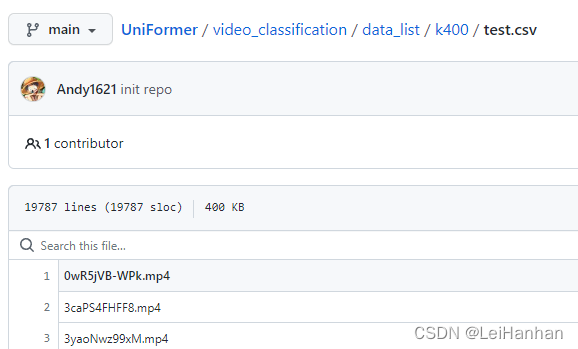
- ?k400[19760条数据]:地址一,地址二
- 抱歉百度云超过4G的文件不让上传,我只把kinetics_400_categroies.txt和test.csv给你们吧,原理都一样,你们也可以自己下载k400数据集。
- 链接:https://pan.baidu.com/s/1QuZb_dkF8Tn7JYBM7AX9mA?pwd=ngyw?提取码:ngyw
- 下载好数据就需要准备数据了【数据裁剪我们就不做了哈】,根据官网提供的,我们可以知道k400目录下有几个文件,train的就不管了,val就相当于test,那么我们只保存和test有关的就行了。也就是这样就行了【我还没有把数据集传到这个目录下,因为需要处理一下】:
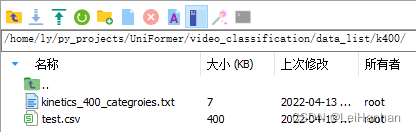
从官网数据格式可知,test.csv里面的数据格式是:数据路径名,标签编号。
而kinetics_400_categroies.txt里面的数据格式是:标签????????标签编号。
我们是不能用官网的test.csv和kinetics_400_categroies.txt的,这个需要根据自己的数据集生成。我写了个脚本生成好了,在地址一中的数据集中都有。
- 把数据放到对应的位置

- 下载模型:uniformer_base_k400_16x4.pth,然后我把它放到了新建的path_to_models文件夹里面【因为在UniFormer.py这个文件里面它定义了这个路径,在这儿改了就不用改UniFormer.py里面的内容了】
?新建test.sh和test.yaml文件,直接把
- 这两个文件复制重命名,得到:
接着就是修改参数了:
- test.sh,文件路径根据自己的进行设置:(如果是在cpu上运行,torch要按照cpu版本的,这里的NUM_GPUS 1,设置成1,还有官网提供的测试时需要修改的参数。)
work_path=/home/ly/py_projects/UniFormer/video_classification/
PYTHONPATH=$PYTHONPATH:./slowfast \
python tools/run_net.py \
--cfg /home/ly/py_projects/UniFormer/video_classification/exp/uniformer_b16x4_k400/test.yaml \
DATA.PATH_TO_DATA_DIR /home/ly/py_projects/UniFormer/video_classification/data_list/k400/val \
DATA.PATH_PREFIX /home/ly/py_projects/UniFormer/video_classification/data_list/k400/val \
DATA.PATH_LABEL_SEPARATOR "," \
TRAIN.EVAL_PERIOD 5 \
TRAIN.CHECKPOINT_PERIOD 1 \
TRAIN.BATCH_SIZE 40 \
NUM_GPUS 1 \
UNIFORMER.DROP_DEPTH_RATE 0.3 \
SOLVER.MAX_EPOCH 110 \
SOLVER.BASE_LR 1.25e-4 \
SOLVER.WARMUP_EPOCHS 10.0 \
DATA.TEST_CROP_SIZE 224 \
TEST.NUM_ENSEMBLE_VIEWS 4 \
TEST.NUM_SPATIAL_CROPS 1 \
TEST.CHECKPOINT_FILE_PATH /home/ly/py_projects/UniFormer/video_classification/path_to_models/uniformer_base_k400_16x4.pth \
RNG_SEED 6666 \
OUTPUT_DIR $work_path
- test.yaml中,由于只使用test,那么把TRAIN: False(即不训练),使用uniformer_base_k400_16x4,如果是单GPU那么NUM_GPUS要设置成1,不然会报no more GPU devices的错,还有官网提供的测试时需要修改的参数。
TRAIN:
ENABLE: False
DATASET: kinetics
BATCH_SIZE: 8
EVAL_PERIOD: 10
CHECKPOINT_PERIOD: 10
AUTO_RESUME: True
DATA:
USE_OFFSET_SAMPLING: True
DECODING_BACKEND: decord
NUM_FRAMES: 16
SAMPLING_RATE: 4
TRAIN_JITTER_SCALES: [224, 224]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3]
# PATH_TO_DATA_DIR: path-to-imagenet-dir
TRAIN_JITTER_SCALES_RELATIVE: [0.08, 1.0]
TRAIN_JITTER_ASPECT_RELATIVE: [0.75, 1.3333]
UNIFORMER:
EMBED_DIM: [64, 128, 320, 512]
DEPTH: [5, 8, 20, 7]
HEAD_DIM: 64
MLP_RATIO: 4
DROPOUT_RATE: 0
ATTENTION_DROPOUT_RATE: 0
DROP_DEPTH_RATE: 0.1
SPLIT: False
PRETRAIN_NAME: 'uniformer_base_k400_16x4'
AUG:
NUM_SAMPLE: 2
ENABLE: True
COLOR_JITTER: 0.4
AA_TYPE: rand-m7-n4-mstd0.5-inc1
INTERPOLATION: bicubic
RE_PROB: 0.25
RE_MODE: pixel
RE_COUNT: 1
RE_SPLIT: False
MIXUP:
ENABLE: True
ALPHA: 0.8
CUTMIX_ALPHA: 1.0
PROB: 1.0
SWITCH_PROB: 0.5
LABEL_SMOOTH_VALUE: 0.1
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
ZERO_WD_1D_PARAM: True
BASE_LR_SCALE_NUM_SHARDS: True
BASE_LR: 0.0001
COSINE_AFTER_WARMUP: True
COSINE_END_LR: 1e-6
WARMUP_START_LR: 1e-6
WARMUP_EPOCHS: 30.0
LR_POLICY: cosine
MAX_EPOCH: 200
MOMENTUM: 0.9
WEIGHT_DECAY: 0.05
OPTIMIZING_METHOD: adamw
COSINE_AFTER_WARMUP: True
MODEL:
NUM_CLASSES: 400
ARCH: uniformer
MODEL_NAME: Uniformer
LOSS_FUNC: soft_cross_entropy
DROPOUT_RATE: 0.5
TEST:
ENABLE: True
DATASET: kinetics
BATCH_SIZE: 64
NUM_SPATIAL_CROPS: 1
DATA_LOADER:
NUM_WORKERS: 8
PIN_MEMORY: True
TENSORBOARD:
ENABLE: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
- 执行运行脚本
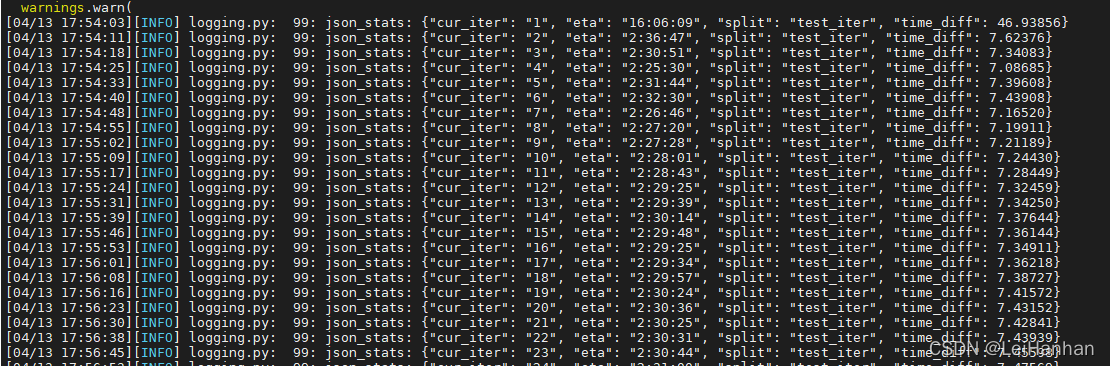
bash exp/uniformer_b16x4_k400/test.sh这就开始运行啦:
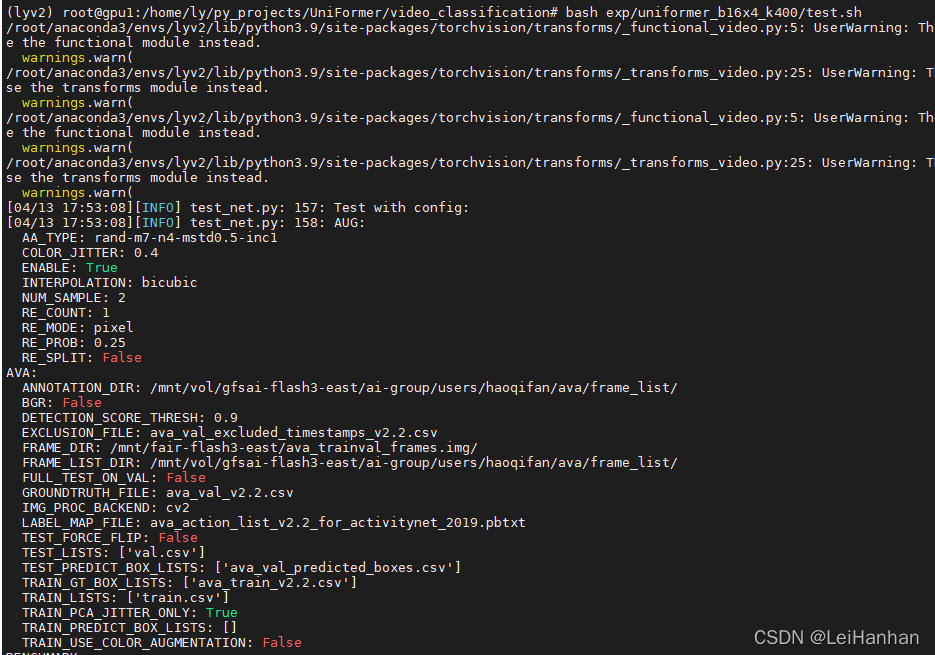
?
?*************************************************************
【在CPU上面会出很多问题,包括(自己根据情况分析,不要任意改动不该改的代码!)
1.我注释了218行
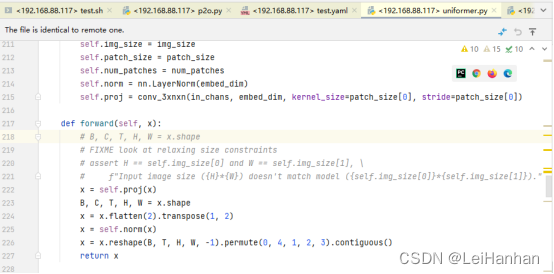
1.
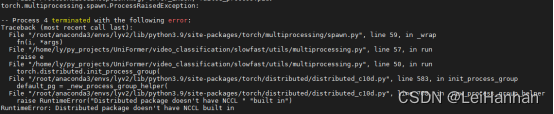
c10d.py中,加了backend = “gloo”,恢复的时候删掉(但会报错)

2.


】*******************************************************************************
4.接下来就是pytorch转onnx啦!!!!
源码仓里面没有转onnx的代码!那么我就得自己写了!p2o.py文件,位于path_to_models文件夹内,
import torch
import numpy as np
from slowfast.models import build_model
"""Wrapper to train and test a video classification model."""
from slowfast.config.defaults import assert_and_infer_cfg
from slowfast.utils.parser import load_config, parse_args
"""
要想把Pytorch转成onnx
1.那么首先要得到pytorch模型.torch保存模型有两种方式:
(1).
保存模型:
torch.save(model.state_dict(),pth_path) #只保存权重参数
调用模型的方法是:
model = my_model() #首先你要根据相关参数新建一个模型(就是你得有这个容器)
model.load_state_dict(torch.load(pth_path)) #再把pth放到这个容器里面
model.eval()
(2).
保存模型:
torch.save(model,pth_path) #这就是保存整个模型(包括容器和权重参数)
调用:
model = torch.load(pth_path) #这里就不需要新建模型(容器)了,因为pth里面有
model.eval()
【ps.当你出现错误:collections.OrderedDict‘ object has no attribute ‘eval‘,极有可能是因为pth只保存了权重参数,没保存整个模型,
而你有没有新建模型,导致调用.eval()的时候就报错了】
2.load模型了,就可以设置一些参数然后调用torch.onnx.export转模型了
"""
# 命令行传参数:python ly_pth/p2o.py --cfg /home/ly/py_projects/UniFormer/video_classification/exp/uniformer_b16x4_k400/test.yaml
# pytorch model path
input_file = "/home/ly/py_projects/UniFormer/video_classification/path_to_models/uniformer_base_k400_16x4.pth"
# onnx model path
output_file = "tmp.onnx"
# 我直接调用代码仓里面现有的加载参数的函数,这样就不用我手动写了
args = parse_args()
cfg = load_config(args)
cfg = assert_and_infer_cfg(cfg)
# 然后利用build函数新建一个模型
model = build_model(cfg)
# 再把权重参数读到这个模型里面(我是这么理解的)
model.load_state_dict(torch.load(input_file))
# 调整模型为eval mode
model.eval()
# 输入节点名
input_names = ["video"]
# 输出节点名
output_names = ["class"]
# 动态(我还不太懂)
dynamic_axes = {'video': {0: 'batch'}, 'class': {0: 'batch'}}
# 形状1, 3, 8, 224, 224对应的是
# `channel`,`num frames`,`height`,`width`
dummy_input = torch.randn(1, 1, 3, 8, 224, 224)
# 转成onnx模型,verbose=True,支持打印onnx节点和对应的PyTorch代码行
torch.onnx.export(model, dummy_input, output_file, dynamic_axes = dynamic_axes, input_names = input_names, output_names = output_names, opset_version=11, verbose=True)
print("hello world*" * 10)?因为我之前在CPU上面弄过一次,这次是在GPU上面弄的,但是两次都是绝对成功的。
上面这个转onnx的代码是在CPU上转的执行这个代码的命令是
python path_to_models/p2o.py --cfg /home/ly/py_projects/UniFormer/video_classification/exp/uniformer_b16x4_k400/test.yaml?转成功了:
?如果运行报错,重启一下服务器
报错及解决:
1.? ? B, C, T, H, W = x.shape
ValueError: not enough values to unpack (expected 5, got 4)?

定位到那一行,直接注释掉。

2.RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should
 解决:?
解决:?
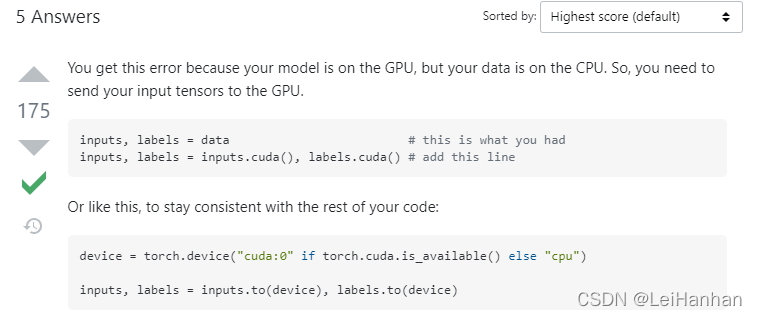
?也就是说在p2o.py里面,把这两句加进去
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dummy_input = torch.randn(1, 1, 3, 8, 224, 224).cuda()?这次真的行了:
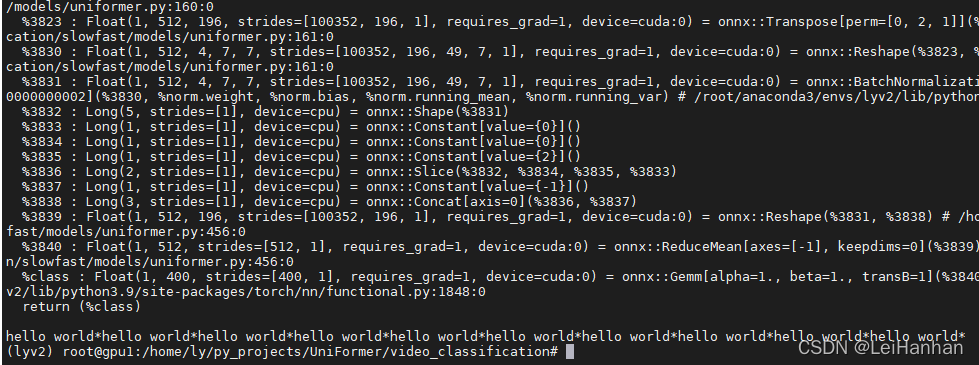
?
?有问题大家一起讨论,一起交流哈哈哈哈

