ǿ��ѧϰ���� ��ɢ�����������ռ�(��������ݶ���ȷ�������ݶ�)
1. �����ռ�
1.1 ��ɢ�����ռ�
- ����: { l e f t , r i g h t , u p } \{left,right,up\} {left,right,up}
- DQN����������ɢ�Ķ����ռ�(��������)
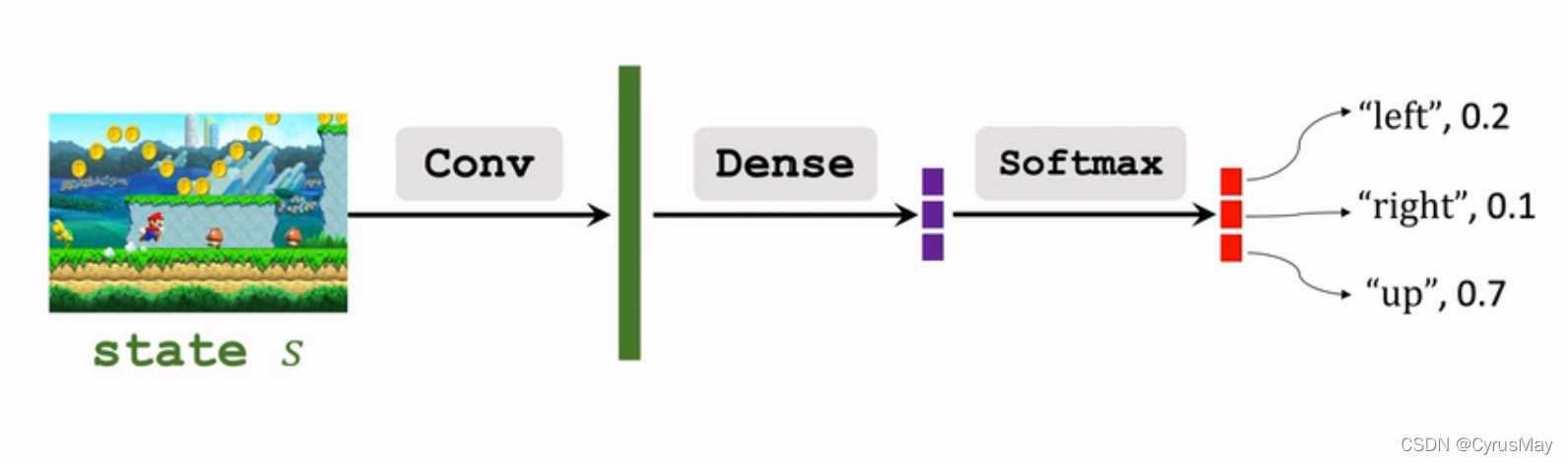
1.2 ���������ռ�
- ����:
A
=
[
0
��
,
18
0
��
]
?
[
0
��
,
36
0
��
]
A=[0^{\circ} ,180^{\circ} ]*[0^{\circ} ,360^{\circ} ]
A=[0��,180��]?[0��,360��]
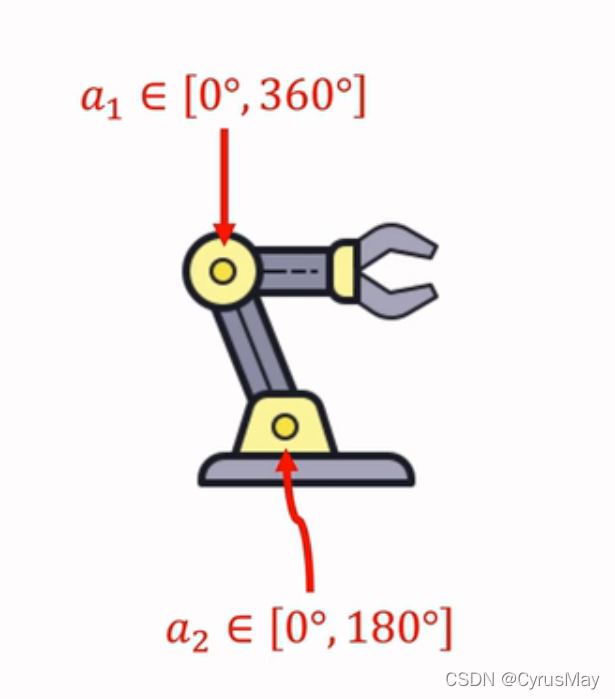
- ���������ռ�����ִ�����ʽ:
- ��ɢ��(discretization):�����е�۽��ж�ά���֡�����dΪ���������ռ�����ɶ�,������ɢ���������������d�����ӳ���ָ������,�Ӷ����ά�����ѡ�
- ʹ��ȷ�������ݶȡ�
- ʹ����������ݶȡ�
2. ȷ�������ݶ�����������
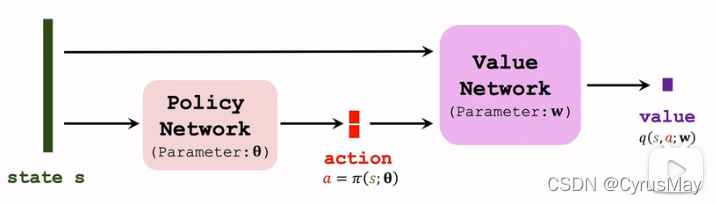
- �����ռ�Ϊ R d R^d Rd��һ���Ӽ�
2.1 ȷ�������ݶ��Ƶ�
- ȷ����������: a = �� ( s ; �� ) a = \pi(s;\theta) a=��(s;��)
- ��ֵ����(���Ϊһ������):
q
(
s
,
a
;
W
)
q(s,a;W)
q(s,a;W)
����ѧϰ����Ϊ:
- �۲һ��transition: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st?,at?,rt?,st+1?)
- ����tʱ�̼�ֵ����ĺ���ֵ: q t = q ( s t , a t ; W ) q_t = q(s_t,a_t;W) qt?=q(st?,at?;W)
- ����t+1ʱ�̼�ֵ����ĺ���ֵ: a t + 1 ? = �� ( s t + 1 ; �� ) q t + 1 = q ( s t + 1 , a t + 1 ? ; W ) a_{t+1}^-=\pi(s_{t+1};\theta)\\q_{t+1}=q(s_{t+1},a_{t+1}^-;W) at+1??=��(st+1?;��)qt+1?=q(st+1?,at+1??;W)
- TD ErrorΪ: �� t = q t ? ( r t + �� ? q t + 1 ) \delta_t=q_t-(r_t+\gamma\cdot q_{t+1}) ��t?=qt??(rt?+��?qt+1?)
- ���¼�ֵ����: W �� W ? �� ? ? q ( s t , a t ; W ) ? W W\gets W-\alpha\cdot\frac{\partial q(s_t,a_t;W)}{\partial W} W��W?��??W?q(st?,at?;W)?
- ���²�����������IJ����ݶ��Ƶ�: �� �� �� �� �� Ŀ �� Ϊ ͨ �� �� �� �� �� a = �� ( s ; �� ) �� �� �� �� �� �� �� �� �� �� ֵ �� �� q = q ( s , a ; W ) �� ֵ �� �� �� ȷ �� �� �� �� �� ( d e t e r m i n i s t i c p o l i c y g r a d i e n t , D P G ) Ϊ : g = ? q ( s , �� ( s ; �� ) ; W ) ? �� = ? q ( s . �� ( s ; �� ) ; W ) ? �� ( s ; �� ) ? ? �� ( s ; �� ) ? �� ���������Ŀ��Ϊͨ����������a=\pi(s;\theta)\\�����ľ��߿������Ӽ�ֵ����q=q(s,a;W)��ֵ��\\ ���ȷ�������ݶ�(deterministic policy gradient, DPG)Ϊ:\\ g=\frac{\partial q(s,\pi(s;\theta);W)}{\partial \theta}=\frac{\partial q(s.\pi(s;\theta);W)}{\partial \pi(s;\theta)}\cdot \frac{\partial \pi(s;\theta)}{\partial \theta} ����������Ŀ��Ϊͨ����������a=��(s;��)��������������������ֵ����q=q(s,a;W)��ֵ������ȷ����������(deterministicpolicygradient,DPG)Ϊ:g=?��?q(s,��(s;��);W)?=?��(s;��)?q(s.��(s;��);W)???��?��(s;��)?
- ����ȷ�������ݶȽ��в��������������: g = ? q ( s , �� ( s ; �� ) ; W ) ? �� = ? q ( s . �� ( s ; �� ) ; W ) ? �� ( s ; �� ) ? ? �� ( s ; �� ) ? �� �� �� �� + �� ? g g=\frac{\partial q(s,\pi(s;\theta);W)}{\partial \theta}=\frac{\partial q(s.\pi(s;\theta);W)}{\partial \pi(s;\theta)}\cdot \frac{\partial \pi(s;\theta)}{\partial \theta}\\ \theta\gets \theta+\beta\cdot g g=?��?q(s,��(s;��);W)?=?��(s;��)?q(s.��(s;��);W)???��?��(s;��)?������+��?g
2.2 ȷ�������ݶ�����ĸĽ�
2.2.1 ʹ��Target����
Bootstrapping����:
- TD TargetΪ: �� t = q t ? ( r t + �� ? q t ? 1 ) \delta_t =q_t-(r_t+\gamma\cdot q_{t-1}) ��t?=qt??(rt?+��?qt?1?)
- ��ֵ����ʹ�õ����Լ��Ĺ����������Լ�,�������������߹����
- �������Ϊ:ʹ�ò�ͬ��������������TD Target����
Target����ĺ���˼��:
- ʹ�ü�ֵ������� t t tʱ�̵ļ�ֵ����ֵ: q t = q ( s t , a t ; W ) q_t = q(s_t,a_t;W) qt?=q(st?,at?;W)
- ʹ�����������ṹ���ֵ����Ͳ�������һ�µ����������t+1ʱ�̵ļ�ֵ����ֵ�Ͷ�������: a t + 1 ? = �� ( s t + 1 ; �� ? ) q t + 1 = q ( s t + 1 , a t + 1 ? ; W ? ) a_{t+1}^-=\pi(s_{t+1};\theta^-)\\q_{t+1}=q(s_{t+1},a_{t+1}^-;W^-) at+1??=��(st+1?;��?)qt+1?=q(st+1?,at+1??;W?)
����Target����ľ���ѧϰ����Ϊ:
- ������������: a t = �� ( s t ; �� ) a_t=\pi(s_t;\theta) at?=��(st?;��)
- ����ȷ�������ݶ�(DPG)���²�������: �� �� �� + �� ? ? q ( s t , �� ( s t ; �� ) ; W ) ? �� ( s t ; �� ) ? ? �� ( s t ; �� ) ? �� \theta\gets \theta+\beta\cdot \frac{\partial q(s_t,\pi(s_t;\theta);W)}{\partial \pi(s_t;\theta)}\cdot \frac{\partial \pi(s_t;\theta)}{\partial \theta} ������+��??��(st?;��)?q(st?,��(st?;��);W)???��?��(st?;��)?
- ����tʱ�̵ļ�ֵ���纯��ֵ: q t = q ( s t , a t ; W ) q_t=q(s_t,a_t;W) qt?=q(st?,at?;W)
- ʹ��Target�������t+1ʱ�̵ļ�ֵ: a t + 1 ? = �� ( s t + 1 ; �� ? ) q t + 1 = q ( s t + 1 , a t + 1 ? ; W ? ) a_{t+1}^-=\pi(s_{t+1};\theta^-)\\q_{t+1}=q(s_{t+1},a_{t+1}^-;W^-) at+1??=��(st+1?;��?)qt+1?=q(st+1?,at+1??;W?)
- ����TD Error: �� t = q t ? ( r t + �� ? q t + 1 ) \delta_t=q_t-(r_t+\gamma \cdot q_{t+1}) ��t?=qt??(rt?+��?qt+1?)
- ���¼�ֵ����IJ���: W �� W ? �� ? �� t ? ? q ( s t , a t ; W ) ? W W\gets W-\alpha\cdot \delta_t \cdot \frac{\partial q(s_t,a_t;W)}{\partial W} W��W?��?��t???W?q(st?,at?;W)?
Target ����IJ������²���Ϊ:
- �趨������ �� �� [ 0 , 1 ] \tau \in [0,1] ����[0,1]
- ����ֵ���硢����������Target����IJ������м�Ȩƽ��,�Ӷ�ʵ�ֲ�������: �� ? = �� ? �� + ( 1 ? �� ) ? �� ? W ? = �� ? W + ( 1 ? �� ) ? W ? \theta^- = \tau\cdot\theta+(1-\tau)\cdot \theta^-\\W^-=\tau\cdot W+(1-\tau)\cdot W^- ��?=��?��+(1?��)?��?W?=��?W+(1?��)?W?
2.2.2 ����Ľ�
- ����ط�(experience replay)
- Multi-step TD Target
2.3 �ܽ�
| / | ����������� | ȷ���Բ������� |
|---|---|---|
| ���Ժ��� | �� ( a �O , s ; �� ) \pi(a|,s;\theta) ��(a�O,s;��) | a = �� ( s ; �� ) a = \pi(s;\theta) a=��(s;��) |
| ��� | �����ռ�ĸ��ʷֲ� | ȷ���Ķ��� a a a |
| ���߷�ʽ | ���ݶ����ռ�ĸ��ʷֲ������������ | ֱ�����һ������ a a a |
| Ӧ�ó��� | ��������ɢ���� | �������� |
3. ����������������������
3.1 ��������
- �ۿۻر�: U t = R t + �� ? R t + 1 + �� 2 ? R t + 2 + . . . U_t = R_t+\gamma\cdot R_{t+1}+\gamma^2\cdot R_{t+2}+... Ut?=Rt?+��?Rt+1?+��2?Rt+2?+...
- ������ֵ����: Q �� ( s t , a t ) = E [ U t �O S t = s t , A t = a t ] Q_\pi(s_t,a_t)=E[U_t|S_t=s_t,A_t=a_t] Q��?(st?,at?)=E[Ut?�OSt?=st?,At?=at?]
- ״̬��ֵ����: V �� ( s t ) = E A t [ Q �� ( s t , A t ) ] V_\pi(s_t)=E_{A_t}[Q_\pi(s_t,A_t)] V��?(st?)=EAt??[Q��?(st?,At?)]
- �����ݶ�: ? V �� ( s t ) ? �� = E A t �� �� [ Q �� ( s t , A t ) ? ? l o g ( �� ( A t �O s t ; �� ) ) ? �� ] g ( A t ) = Q �� ( s t , A t ) ? ? l o g ( �� ( A t �O s t ; �� ) ) ? �� \frac{\partial V_\pi(s_t)}{\partial \theta}=E_{A_t\sim \pi}[Q_\pi(s_t,A_t)\cdot\frac{\partial log(\pi(A_t|s_t;\theta))}{\partial \theta}]\\g(A_t)=Q_\pi(s_t,A_t)\cdot\frac{\partial log(\pi(A_t|s_t;\theta))}{\partial \theta} ?��?V��?(st?)?=EAt?����?[Q��?(st?,At?)??��?log(��(At?�Ost?;��))?]g(At?)=Q��?(st?,At?)??��?log(��(At?�Ost?;��))?
- �������ؿ�����ƺ�IJ����ݶ�Ϊ: a t �� �� ( ? �O s t ; �� ) g ( a t ) = Q �� ( s t , a t ) ? ? l o g ( �� ( a t �O s t ; �� ) ) ? �� a_t\sim\pi(\cdot|s_t;\theta)\\g(a_t)=Q_\pi(s_t,a_t)\cdot\frac{\partial log(\pi(a_t|s_t;\theta))}{\partial \theta} at?����(?�Ost?;��)g(at?)=Q��?(st?,at?)??��?log(��(at?�Ost?;��))?
3.2 ��������
3.2.1 ���ɶ�Ϊ1�����������ռ�
- ���� �� \mu ���� �� \sigma ��Ϊ״̬ s s s�ĺ���
- ������Ժ���Ϊ��̬�ֲ��ĸ����ܶȺ���: �� ( a �O s ) = 1 2 �� ? �� e ? ( a ? �� ) 2 2 �� 2 \pi(a|s)=\frac{1}{\sqrt{2\pi}\cdot\sigma}e^{-\frac{(a-\mu)^2}{2\sigma^2}} ��(a�Os)=2��??��1?e?2��2(a?��)2?
3.2.2 ���ɶȴ���1(Ϊ d d d)�����������ռ�
- �����ռ�Ϊdά����
- �� \mu ���� �� \sigma ��Ϊ״̬ s s s�ĺ���: s �� R d s\to R^d s��Rd
- �� i \mu_i ��i?�� �� i \sigma_i ��i?Ϊ �� ( s ) \mu(s) ��(s)�� �� ( s ) \sigma(s) ��(s)�ĵ� i i i��Ԫ��
- ������Ժ���Ϊ: �� ( a �O s ) = �� i = 1 d 1 2 �� ? �� i e ? ( a ? �� i ) 2 2 �� i 2 \pi(a|s)=\Pi_{i=1}^d \frac{1}{\sqrt{2\pi}\cdot\sigma_i}e^{-\frac{(a-\mu_i)^2}{2\sigma_i^2}} ��(a�Os)=��i=1d?2��??��i?1?e?2��i2?(a?��i?)2?
3.2.3 ��������
- �Ծ�ֵ�Ľ���: �� ( s ) �� �� ( s ; �� �� ) \mu(s)\gets \mu(s;\theta^\mu) ��(s)����(s;����)
- �Է���Ķ������н���: �� i = l o g ( �� i 2 ) i = 1 , 2 , . . . , d �� �� �� ( s ; �� �� ) \rho_i = log(\sigma_i^2) \quad i = 1,2,...,d\\\rho\gets \rho(s;\theta^\rho) ��i?=log(��i2?)i=1,2,...,d������(s;����)
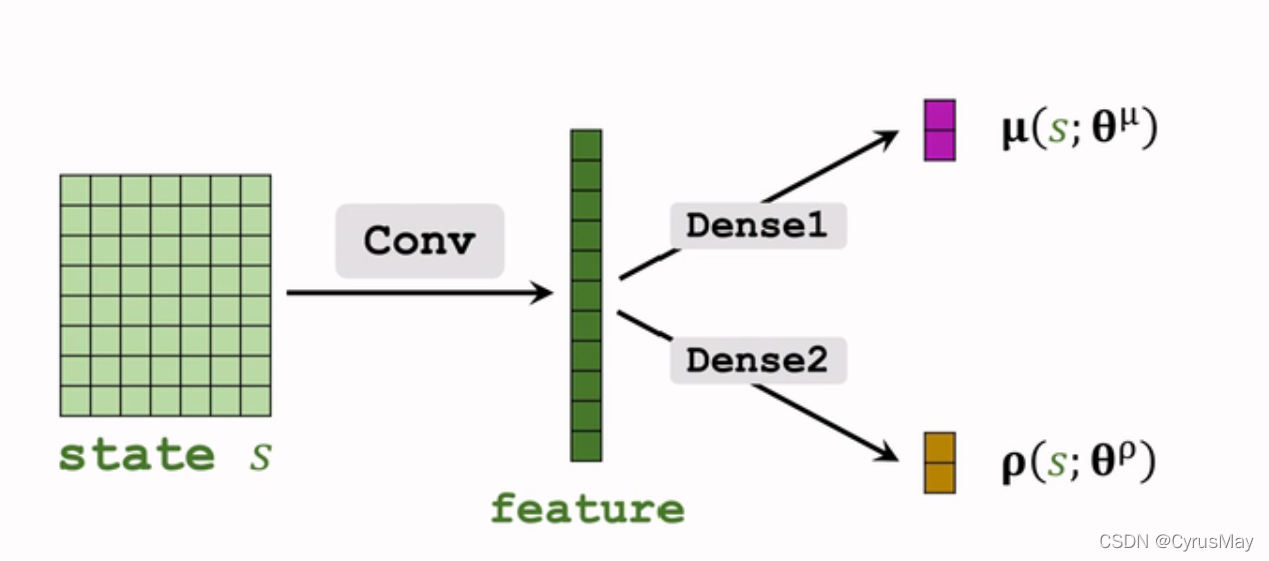
3.2.4 �������Ʋ���
- �۲״̬ s t s_t st?
- ͨ������������ֵ�ͷ���: �� ^ = �� ( s t ; �� ) �� ^ = �� ( s t ; �� ) �� i ^ 2 = e �� i i = 1 , 2 , . . . , d \hat{\mu}=\mu(s_t;\theta)\\\hat{\rho}=\rho(s_t;\theta)\\\hat{\sigma_i}^2=e^{\rho_i} \quad i = 1,2,...,d ��^?=��(st?;��)��^?=��(st?;��)��i?^?2=e��i?i=1,2,...,d
- ������������õ����� a a a: a i �� N ( u i ^ , �� i ^ 2 ) i = 1 , 2 , . . . , d a_i\sim N(\hat{u_i},\hat{\sigma_i}^2)\quad i = 1,2,...,d ai?��N(ui?^?,��i?^?2)i=1,2,...,d
3.2.5 ���Ӹ���������
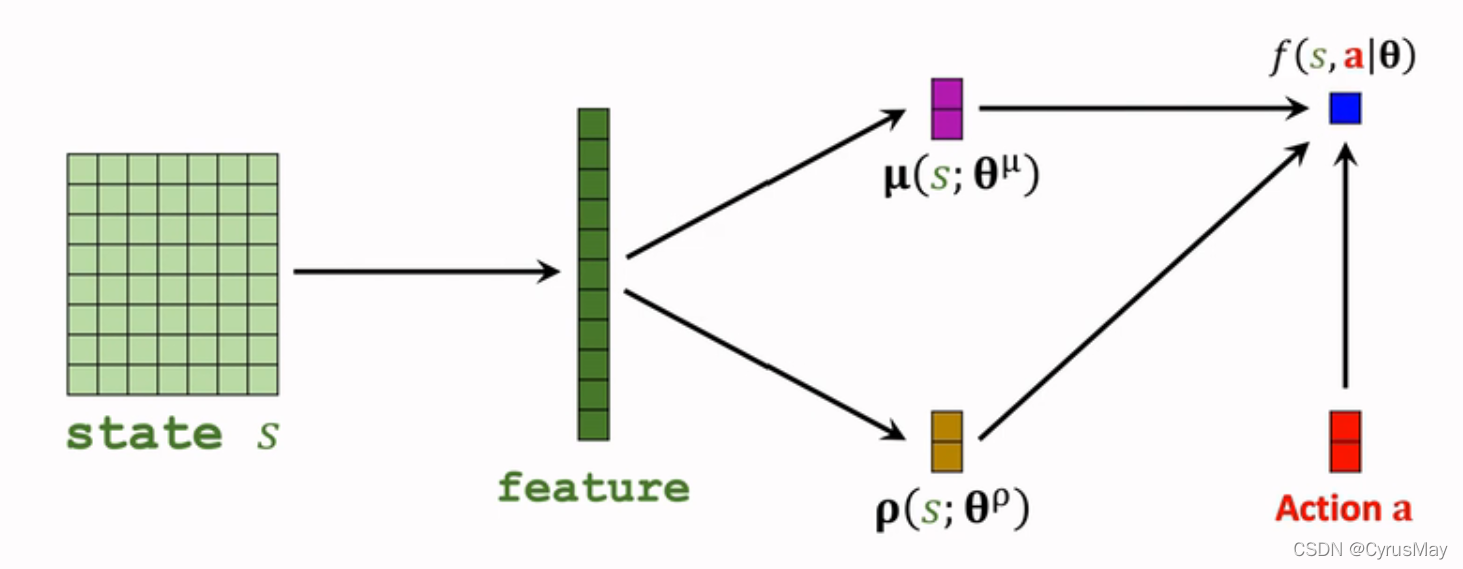
- ��������Ϊ: �� ( a �O s ; �� �� , �� �� ) = �� i = 1 d 1 2 �� ? �� i ? e ? ( a ? �� i ) 2 2 �� i 2 l o g ( �� ( a �O s ; �� �� , �� �� ) ) = �� i = 1 d [ ? l o g ( �� i ) ? ( a ? �� i ) 2 2 �� i 2 ] + c o n s t l o g ( �� ( a �O s ; �� �� , �� �� ) ) = �� i = 1 d [ ? �� i 2 ? ( a ? �� i ) 2 2 ? e �� i ] + c o n s t log ? ( �� ( a �O s ; �� �� , �� �� ) ) = f ( s , a ; �� ) �� = ( �� �� , �� �� ) \pi(a|s;\theta^\mu,\theta^\rho)=\Pi_{i=1}^d\frac{1}{\sqrt{2\pi}\cdot\sigma_i}\cdot e^{-\frac{(a-\mu_i)^2}{2\sigma_i^2}} \\ log(\pi(a|s;\theta^\mu,\theta^\rho))=\sum_{i=1}^d[-log(\sigma_i)-\frac{(a-\mu_i)^2}{2\sigma_i^2}]+const\\log(\pi(a|s;\theta^\mu,\theta^\rho))=\sum_{i=1}^d[-\frac{\rho_i}{2}-\frac{(a-\mu_i)^2}{2\cdot e^{\rho_i}}]+const\\\log(\pi(a|s;\theta^\mu,\theta^\rho))=f(s,a;\theta)\quad \theta=(\theta^\mu,\theta^\rho) ��(a�Os;����,����)=��i=1d?2��??��i?1??e?2��i2?(a?��i?)2?log(��(a�Os;����,����))=i=1��d?[?log(��i?)?2��i2?(a?��i?)2?]+constlog(��(a�Os;����,����))=i=1��d?[?2��i???2?e��i?(a?��i?)2?]+constlog(��(a�Os;����,����))=f(s,a;��)��=(����,����)
- ���������� f ( s , a ; �� ) f(s,a;\theta) f(s,a;��)Ϊ����������,��õ�����������: �� ( s ; �� �� ) �� ̬ �� �� �� �� ֵ �� ( s ; �� �� ) �� ̬ �� �� �� �� �� �� �� f ( s , a ; �� ) �� �� �� �� �� �� �� �� ѵ �� �� �� �� �� �� �� \mu(s;\theta^\mu)\quad ��̬�ֲ��ľ�ֵ\\\rho(s;\theta^\rho)\quad��̬�ֲ��Ķ�������\\f(s,a;\theta)\quad ��������������ѵ������������ ��(s;����)��̬��������ֵ��(s;����)��̬��������������f(s,a;��)����������������ѵ��������������
- ��������ݶ�Ϊ: g ( a ) = ? l o g ( �� ( a �O s ; �� ) ) ? �� ? Q �� ( s , a ) f ( s , a ; �� ) = l o g ( �� ( a �O s ; �� ) ) + c o n s t g ( a ) = ? f ( s , a ; �� ) ? �� ? Q �� ( s , a ) g(a )= \frac{\partial log(\pi(a|s;\theta))}{\partial \theta}\cdot Q_\pi(s,a)\\ f(s,a;\theta)=log(\pi(a|s;\theta))+const\\g(a )=\frac{\partial f(s,a;\theta)}{\partial \theta}\cdot Q_\pi(s,a) g(a)=?��?log(��(a�Os;��))??Q��?(s,a)f(s,a;��)=log(��(a�Os;��))+constg(a)=?��?f(s,a;��)??Q��?(s,a)
3.2.6 ״̬��ֵ�����Ľ���
- ʹ��reinforce�㷨: u t = r t + �� ? r t + 1 + . . . �� �� �� + �� ? ? f ( s , a ; �� ) ? �� ? u t u_t = r_t+\gamma\cdot r_{t+1}+...\\\theta\gets\theta+\beta\cdot\frac{\partial f(s,a;\theta)}{\partial \theta}\cdot u_t ut?=rt?+��?rt+1?+...������+��??��?f(s,a;��)??ut?
- ʹ�� A-C�㷨: Q �� �� q ( s , a ; W ) �� �� �� + �� ? ? f ( s , a ; �� ) ? �� ? q ( s , a ; W ) Q_\pi\sim q(s,a;W)\\\theta\gets\theta+\beta\cdot\frac{\partial f(s,a;\theta)}{\partial \theta}\cdot q(s,a;W) Q��?��q(s,a;W)������+��??��?f(s,a;��)??q(s,a;W)
4 �ܽ�
- ���������ռ���������ֶ�������
- �����������:
- ��ɢ�����ռ�,ʹ�ñ�DQN���߲����������ѧϰ,������������ά������
- ʹ��ȷ�������������ѧϰ(��û�������)
- �漴��������( �� �� �� 2 \mu��\sigma^2 ������2)
- ѵ�����̵ļ���:
- ���츨�������� f ( s , a ; �� ) f(s,a;\theta) f(s,a;��)��������ݶ�
- �����ݶȽ����㷨����:reinforce��Actor-Critic�㷨
- ���ԸĽ�reinforce�㷨,ʹ�ô���baseline��reinforce�㷨
- ���ԸĽ�Actor-Critic�㷨,ʹ��A2C�㷨
��������Ϊ�ο�Bվѧϰ��Ƶ��д�ıʼ�!
ʱ������
͵��һ��
��������������(����)��������
by CyrusMay 2022 04 13

