我们在前一篇文章《生成式摘要的四篇经典论文》中介绍了Seq2seq在生成式研究中的早期应用,以及针对摘要任务本质的讨论。
如今,以T5为首的预训练模型在生成任务上表现出超出前人的效果,这些早期应用也就逐渐地淡出了我们的视野。本文将介绍T5的多国语言版mT5及其变种T5-Pegasus,以及T5-Pegasus如何做到更好地适用于中文生成,并介绍它在中文摘要任务中的实践。
本文结构
mT5
T5模型出自Google团队的《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,是一个Encoder-Decoder结构的Transformer预训练语言模型,在各大NLP生成任务中表现优异,一举刷新了多个NLP任务的榜单。
mT5,即Multilingual T5,T5的多国语言版。mT5出自Google团队的《mT5: A massively multilingual pre-trained text-to-text transformer》,mT5的预训练语料涵盖了101种语言,其中包括了中文。
Text-to-Text 结构
以Text-to-Text为目标的mT5,采用完整的Transformer模型结构。对Transformer不了解的读者,可以看下我的博客《Transformer回顾与细节》。
这里只关注 mT5 与传统Transformer的不同之处。
细节1. 相对位置编码
mT5采用相对位置编码。具体地,我们先看常规self-Attention计算过程:
a
i
j
=
s
o
f
t
m
a
x
[
(
x
i
W
Q
)
(
x
j
W
K
)
T
d
k
]
z
i
=
∑
j
=
1
n
a
i
j
(
x
j
W
V
)
\begin{aligned} a_{ij} &= softmax[\frac{(x_i W^Q)(x_j W^K)^T}{\sqrt{d_k}}] \\ z_{i}&=\sum_{j=1}^n {a_{ij}(x_j W^V)} \end{aligned}
aij?zi??=softmax[dk??(xi?WQ)(xj?WK)T?]=j=1∑n?aij?(xj?WV)?
相对位置编码的开篇之作《Self-Attention with Relative Position Representations》的做法是,如下式,分别在
a
i
j
a_{ij}
aij?上加入可训练的
R
i
j
K
R_{ij}^K
RijK?,在
z
i
z_i
zi?上加入可训练的
R
i
j
V
R_{ij}^V
RijV?。此外,由于对较远位置的准确性要求较低,就将其截断
c
l
i
p
(
j
?
i
,
k
)
clip(j-i, k)
clip(j?i,k)。
a
i
j
=
s
o
f
t
m
a
x
[
(
x
i
W
Q
)
(
x
j
W
K
+
R
i
j
K
)
T
d
k
]
z
i
=
∑
j
=
1
n
a
i
j
(
x
j
W
V
+
R
i
j
V
)
\begin{aligned} a_{ij} &= softmax[\frac{(x_i W^Q)(x_j W^K+R_{ij}^K)^T}{\sqrt{d_k}}] \\ z_{i}&=\sum_{j=1}^n {a_{ij}(x_j W^V+R_{ij}^V)} \end{aligned}
aij?zi??=softmax[dk??(xi?WQ)(xj?WK+RijK?)T?]=j=1∑n?aij?(xj?WV+RijV?)?
mT5的相对位置编码的做法是,如下式,在
a
i
j
a_{ij}
aij?上加入可训练的
R
i
j
K
R_{ij}^K
RijK?,
z
i
z_i
zi?保持不变。
a
i
j
=
s
o
f
t
m
a
x
[
(
x
i
W
Q
)
(
x
j
W
K
)
T
+
R
i
j
K
d
k
]
z
i
=
∑
j
=
1
n
a
i
j
(
x
j
W
V
)
\begin{aligned} a_{ij} &= softmax[\frac{(x_i W^Q)(x_j W^K)^T+R_{ij}^K}{\sqrt{d_k}}] \\ z_{i}&=\sum_{j=1}^n {a_{ij}(x_j W^V)} \end{aligned}
aij?zi??=softmax[dk??(xi?WQ)(xj?WK)T+RijK??]=j=1∑n?aij?(xj?WV)?
所以,mT5第一个block的self-attention计算中,直接把relative_position_bias加在score上,代码如下。
# compute attention scores
scores = torch.matmul(query_states, key_states.transpose(3, 2))
position_bias = self.compute_bias(real_seq_length, key_length)
scores += position_bias # (batch_size, n_heads, seq_length, key_length)
position_bias是如何计算的呢?这个计算过程是比较特别的。在计算当前token和目标token的attention值时,记录两个token的距离的绝对值,我们不直接使用这个距离值,而是根据距离值的大小进行一定程度的缩小,距离值越大缩小倍数越大,距离值越小缩小倍数越小。具体实现时,采用一种bucket"分桶"的方法,即对于临近距离应分到不同的桶中,分别进行精细编码;对于稍远距离应分到同一个桶中,共用一个编码;对于更远距离则共用范围更大一些;对于超出限定距离则clip截断。
细节2. 无均值的归一化
mT5的layer norm计算不同于常规layer norm,省去了均值。我们先看常规的layer norm计算:
o
u
t
=
x
?
m
e
a
n
[
x
,
a
x
i
s
]
V
a
r
[
x
,
a
x
i
s
]
+
?
×
γ
+
β
out=\frac{x-mean[x, axis]}{\sqrt{Var[x, axis]}+\epsilon} \times \gamma+\beta
out=Var[x,axis]?+?x?mean[x,axis]?×γ+β
mT5的layer norm省去了"减均值"这一步,计算如下:
o
u
t
=
x
V
a
r
[
x
,
a
x
i
s
]
+
?
×
γ
out=\frac{x}{\sqrt{Var[x, axis]+\epsilon}} \times \gamma
out=Var[x,axis]+??x?×γ
细节3. 无dk的注意力得分
此外mT5有一个细节,计算self-Attention score时,省去了"除以 d k d_k dk?"这一步。我们先看常规的self-Attention score计算:
a i j = s o f t m a x ( Q K T d k ) a_{ij} = softmax(\frac{QK^T}{\sqrt{d_k}}) aij?=softmax(dk??QKT?)
而mT5的self-Attention score计算如下:
a
i
j
=
s
o
f
t
m
a
x
(
Q
K
T
)
a_{ij} = softmax(QK^T)
aij?=softmax(QKT)
细节4. Dropout策略
mT5在预训练阶段,完全不使用Dropout;在微调阶段,才使用Dropout。
细节5. 无bias且采用GLU的全连接层
mT5的FFN层的激活函数采用“门控线性单元GLU”,并且没有bias项。我们先来看常规的以ReLU为激活函数的FFN层:
F F N ( x ) = R e L U ( x W 1 + b 1 ) W 2 + b 2 FFN(x)=ReLU(xW_1+b_1)W_2+b_2 FFN(x)=ReLU(xW1?+b1?)W2?+b2?
mT5的FFN层则改为:
F F N ( x ) = ( G e L U ( x W 1 ) ? x W 2 ) W 3 FFN(x)=(GeLU(xW_1)\otimes xW_2)W_3 FFN(x)=(GeLU(xW1?)?xW2?)W3?
FFN层增加了50%参数,从论文实验看效果明显增加。
细节6. Softmax层与Embedding层不共享参数
mT5的Embedding层参数共享,即Encoder与Decoder共享同一个Embedding矩阵。但是mT5的Softmax层与Embedding不共享参数,即Softmax层采用独立的Embedding矩阵。这样一来,参数量大大增加,但从实验结果来看效果更好。
有监督/无监督预训练任务
mT5的预训练任务很多,有无监督预训练,也有有监督预训练。它们的共性是,完全采用生成式。下面分别介绍:
(1) 无监督预训练
mT5最有效的无监督任务是采用BERT的MLM任务,也就是补齐句子中被mask的词。不过,mT5把语料构造为Seq2seq生成式的形式。
输入:明月几时有,[M0]问青天,不知[M1],今夕是何年?
输出:[M0]把酒[M1]天上宫阙

(2) 有监督预训练
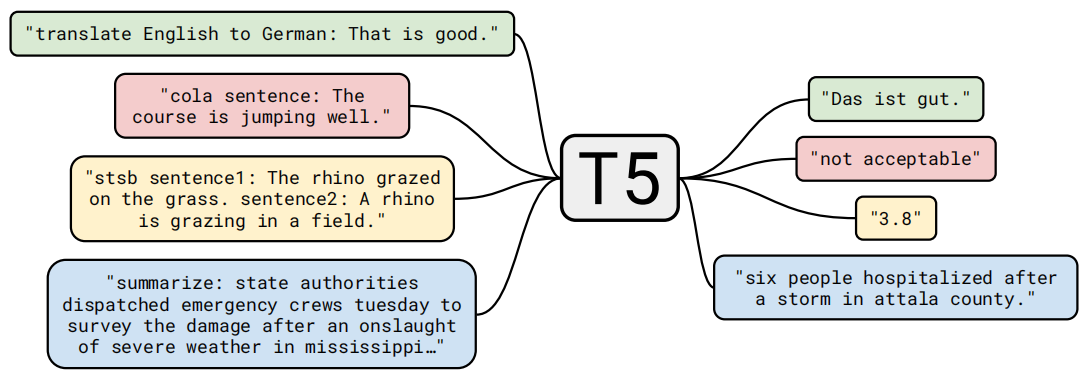
mT5采用多种NLP任务语料,以Seq2seq的形式,构造了多个有监督预训练任务,例如下图中的机器翻译、语言可接受度、相似度匹配、自动摘要,还有阅读理解、情感分类、主题分类、完形填空等等。
样本以任务描述文字开头,也就是提示(Prompt),然后才是样本内容,例如下图中的"translate English to German:",告知模型把这段英文文本翻译成德语文本。
mT5尝试在预训练阶段只做无监督任务,去掉有监督任务,从实验结果来看效果依然出色。
此外,要注意的是,由于架构差异,使用mT5 finetuen时,学习率应比BERT大10倍,即5e-4,BERT的学习率通常为5e-5。
T5-Pegasus
接下来,介绍T5-Pegasus。
以mT5为基础架构和初始权重,结合中文的特点对Tokenizer作了修改,在中文语料上使用PEGASUS式的伪摘要预训练任务,最终训练得到新的T5模型,即T5-Pegasus。
新的Tokenizer与更小的词表
mT5使用的Tokenizer是sentencepiece,支持词粒度。虽然中文词不多,但是相比字粒度有提升。
sentencepiece是一个C++编写的分词库,高效轻便,但对中文并不友好,例如,将全角字符强制转换为半角字符。
为此,T5-Pegasus的Tokenizer换为了BERT的Tokenizer,并与jieba分词相结合,实现分词功能。具体地,先用jieba分词,如果当前词在词表vocab.txt中,就用jieba分词的结果;如果当前词不在词表vocab.txt中,再改用BERT的Tokenizer。
mT5的词表大小为25w,涵盖101种语言,其中大量词是无用的(对中文任务而言)。并且由于mT5的Softmax层与Embedding层不共享参数,mT5 small的参数量为3亿,其中Embedding相关的就占了2.5亿,占用了高额显存。
为此,T5-Pegasus的两个Embedding矩阵中,只保留了中文任务的常用token。具体地,从jieba词表的前20w个高频词中,选取了在预训练语料中出现频次最高的5w个词,并将其作为词表vocab.txt。
伪摘要式预训练任务
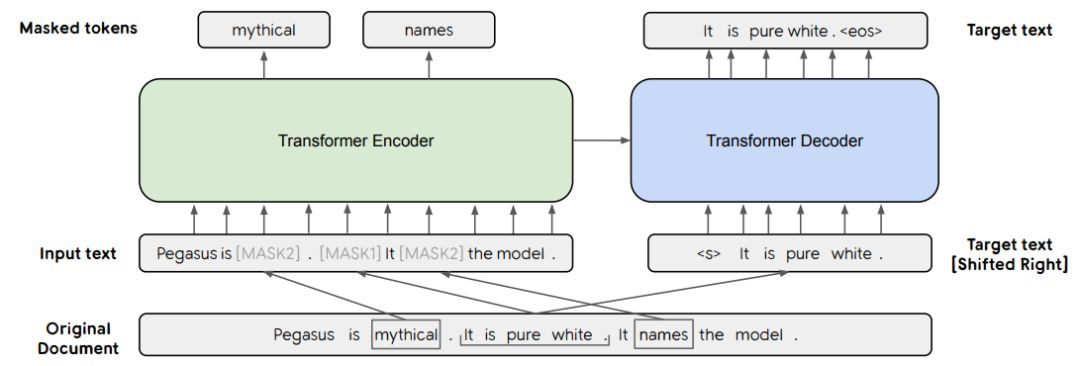
伪摘要式预训练任务来自Pegasus一文《PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization》,即选取正文ci中与其他句子重合率最高(最长公共子序列)的m个句子,作为摘要,从而构建可用于训练的摘要语料。

详细地,如下图伪代码所示,初始状态下的标题/标签ti为空,从正文与标题/标签的差集si=ci - ti中选一个句子,这个句子使得差集si和此刻的标题/标签ti的Rouge-F1得分最高,将其并入候选标题/标签ti中,并重复上述步骤m次,得到包含m个句子的标题/标签ti。

中文摘要生成实践
为了深入理解T5模型的底层逻辑,笔者阅读了Transformers的T5模型源代码,将其撰写为博文《MT5ForConditionalGeneration生成模型的推理细节,源码阅读》,欢迎各位读者阅读和提问,并留下宝贵意见。
笔者将T5-Pegasus的finetune与推理代码(Pytorch版)上传至Github库链接,欢迎start和Issue。
此外,笔者在此基础上,实现了T5-Pegasus的模型量化、模型剪裁、模型蒸馏,将在后续文章中详细介绍,并在Github中开源代码,欢迎关注。
Reference:
- [1] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- [2] mT5: A massively multilingual pre-trained text-to-text transformer
- [3] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
- [4] 那个屠榜的T5模型,现在可以在中文上玩玩了
- [5] T5 PEGASUS:开源一个中文生成式预训练模型
- [6] Self-Attention with Relative Position Representations

