背景
SequenceToSequence模型执行翻译任务与模型讲解。
SequenceToSequence 翻译执行流程
步骤:
- 英文有26个字母,中文有好多字,可以依据这个来对字进行编号,然后将英文字母和汉字转换为对应的数字。
- 可以依据索引值来构造字典
- 中文按照字来区分,英文按照字母来进行区分
- 当中文句子和英文句子转为对应的数字时,然后进行one-hot编码。使用one-hot编码的目的是为了使特征表达更加合理。
- 编码,解码
SequenceToSequence中有注意力机制的存在,依据代码是可以看到的。Encoder和Decoder中的的输入是不一样的, Encoder输入源语言,Decoder输入的是目标语言。
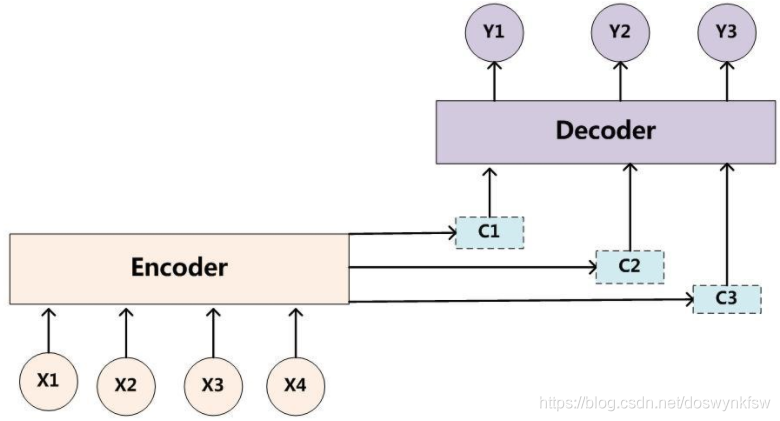
encoder的最后一个时间步的状态输出作为decoder模型的初始状态输入,这样才能保证序列信息的传递。这就说明了LSTM学习得到的是序列信息。LSTM中有遗忘门,输入门,输出门,GRU有重置门和更新门。decoder最后输出的是中文,所以直接做一个Dense变为中文。我们只需要得到编码器的状态就可以,在LSTM中的输出是有三个的。
- 预测 -> 预测模型中的encoder和训练中的一样,都是输入序列,输出几个状态。而decoder和训练中稍有不同,因为训练过程中的decoder端的输入是可以确定的,因此状态只需要初始化一次,而预测过程中,需要多次初始化状态,因此将状态也作为模型输入。
在预测时,我们也需要同时使用encoder的信息和decoder的信息,编码器首先输入预测的信息(即要翻译的句子),然后得到要翻译句子的序列信息,然后将这个序列信息传递给解码器,解码器最终会有一个句子的输出,然后第一次得到一个最可能的词,然后依据这个词,改变解码器的输入,初始状态是不变的,只有输入在变,然后不断的去生成这个序列。
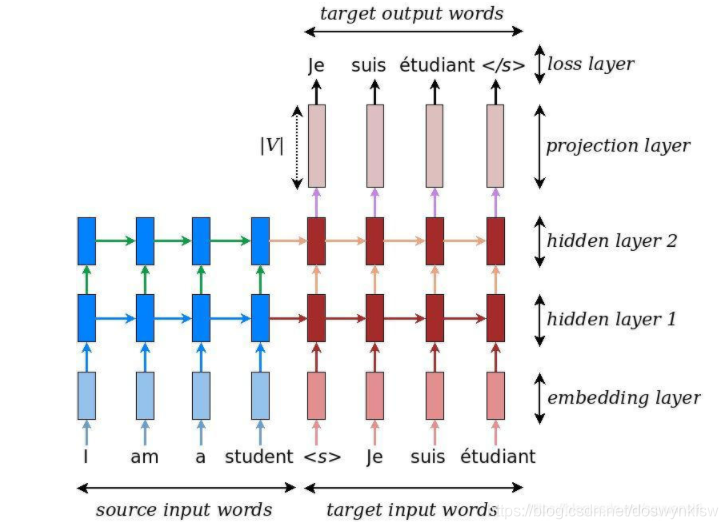
seq2seq代码模型流程图
损失函数
多分类的交叉熵损失函数,没个字或者词对应一个类别。
参考资料
这里面对编码和解码有了一个详细的说明
https://blog.csdn.net/weixin_43718675/article/details/88925451

