使用自己的数据/图片创造数据集
如果你拥有自己的数据集,那首先要考虑的就是如何将你的数据集输入到PyTorch当中去。如果你的数据是来自于网络(比如说,从Kaggle下载,从论文作者处获得,从某个数据集官方的网站进行下载),那你遇见的原始数据格式可能是各种情况,最常见的是各类压缩文件、pt文件、数据库格式文件或者png/jpg/webp等原始图像。如果你的数据是来自于实验室、公司数据库、甚至是领导/导师给的数据,那你的数据大概率都是csv/txt/mat等结构的二维数据表。无论我们的原始数据集是呈现什么样的格式,我们必须将其转换为四维的张量,数据才可以被卷积神经网络处理。对于任意压缩文件,先解压查看内部是什么内容,对于其他格式文件,你可以根据你的需要查看本节中相应的小节。
2.1 从图像png/jpg到四维tensor
ImageFolder
当你拥有的数据是一系列图像,并且每个标签对应的图像是存放在单独的文件夹中,那你几乎遇见了最简单的情况。在torchvision中存在直接将文件夹中的图片打包成tensor的类ImageFolder,它的参数和torchvision.datasets中其他数据导入类的参数非常相似,其中root是你的原始图像所在的根目录,transform是你希望对图像执行的具体操作。
train_dataset = torchvision.datasets.ImageFolder(root="XXXX"
,transform=torchvision.transforms.ToTensor()
)
这个类可以接受.jpg、.jpeg、.png、.ppm、.bmp、.pgm、.tif、.tiff、.webp这9种不同的图片格式作为输入,并且还能够通过文件夹的分类自动识别标签。举例说明,如果你的图片是被打包成如下所示的特定格式,那你的数据就适用于ImageFolder这个类:
在你的根目录下,每个类别需要有一个单独的文件夹。如上图所示,cat和dog就是该数据集的两种类别,而类别文件夹中可以存在多个子文件夹,或直接存放图片。图片的格式不需要统一,只要在ImageFolder可接受的9种格式中即可。让我们以celebA数据集中随机提取出的子集为例来实验一下ImageFolder代码。我的根目录如下,其中训练集和测试集是分开的两个文件夹,train和test文件夹中分别有两个类别female和male。
#训练集
train_dataset = torchvision.datasets.ImageFolder(root="/Users/zhucan/Desktop/datasets4/picturestotensor/Train",
transform=torchvision.transforms.ToTensor()
)
train_dataset
#Dataset ImageFolder
# Number of datapoints: 60
# Root location: /Users/zhucan/Desktop/datasets4/picturestotensor/Train
# StandardTransform
#Transform: ToTensor()
for x,y in train_dataset:
print(x.shape,y)
break
#torch.Size([3, 687, 409]) 0
train_dataset[0]
#(tensor([[[0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],
# [0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],
# [0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],
# ...,
# [0.9922, 0.9922, 0.9922, ..., 0.9529, 0.9176, 0.9373],
# [0.9922, 0.9922, 0.9922, ..., 0.9843, 0.9294, 0.9333],
# [0.9922, 0.9922, 0.9922, ..., 1.0000, 0.9490, 0.9373]],
#
# [[0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],
# [0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],
# [0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],
# ...,
# [0.8549, 0.8549, 0.8549, ..., 0.6784, 0.6667, 0.6980],
# [0.8549, 0.8549, 0.8549, ..., 0.7059, 0.6824, 0.6980],
# [0.8549, 0.8549, 0.8549, ..., 0.7216, 0.6941, 0.7020]],
#
# [[0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],
# [0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],
# [0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],
# ...,
# [0.6902, 0.6902, 0.6902, ..., 0.4784, 0.4784, 0.5137],
# [0.6902, 0.6902, 0.6902, ..., 0.4941, 0.4824, 0.5020],
# [0.6902, 0.6902, 0.6902, ..., 0.5020, 0.4824, 0.4980]]]),
# 0)
train_dataset[58][1]
#1
#几种可以调用的属性
train_dataset.classes
#['female', 'male']
np.unique(train_dataset.targets)
#array([0, 1])
#查看具体的图像地址
train_dataset.imgs
#[('F:\\datasets4\\picturestotensor\\Train\\female\\000001.jpg', 0),
# ('F:\\datasets4\\picturestotensor\\Train\\female\\000002.jpg', 0),
# ('F:\\datasets4\\picturestotensor\\Train\\female\\000004.jpg', 0),
#
# ('F:\\datasets4\\picturestotensor\\Train\\male\\000052.jpg', 1),
# ('F:\\datasets4\\picturestotensor\\Train\\male\\000053.jpg', 1),
# ('F:\\datasets4\\picturestotensor\\Train\\male\\000055.jpg', 1),
# ('F:\\datasets4\\picturestotensor\\Train\\male\\Pet-Peacock.png', 1)]
#随机查看5张图像
plotsample(train_dataset)

#测试集 - 注意更换根目录
test_dataset = torchvision.datasets.ImageFolder(root="/Users/zhucan/Desktop/datasets4/picturestotensor/Test",
transform=torchvision.transforms.ToTensor()
)
test_dataset
#Dataset ImageFolder
# Number of datapoints: 62
# Root location: /Users/zhucan/Desktop/datasets4/picturestotensor/Test
# StandardTransform
#Transform: ToTensor()
plotsample(test_dataset)

注意,ImageFolder只能够读取根目录的子文件夹中的图片,并且一定会将子文件夹的名称作为类别。当根目录中只有一个子文件夹时,则对所有的图片标签都标注为0。当根目录中没有文件夹,而是直接存放图片时,则会直接报错。
毫无疑问,ImageFolder是一个省时省力的方式,但是简单也意味着它不够灵活(在编程的世界里总是如此),因此会让人非常怀疑它在现实数据集前能有多少作用。当图像相关的标签类别数量很少,我们能够很容易地将图像按照他们所在的标签类别进行打包,当数据的标签类别比较多,或者样本量比较大时,要将同一标签类别的样本分到不同类别的文件夹中就变得不再“省时省力”了。但幸运的是,在图像的世界里,许多数据集、尤其是巨大数据集是提前按照标签“分好”的,比如我们之前看过的LSUN数据集。
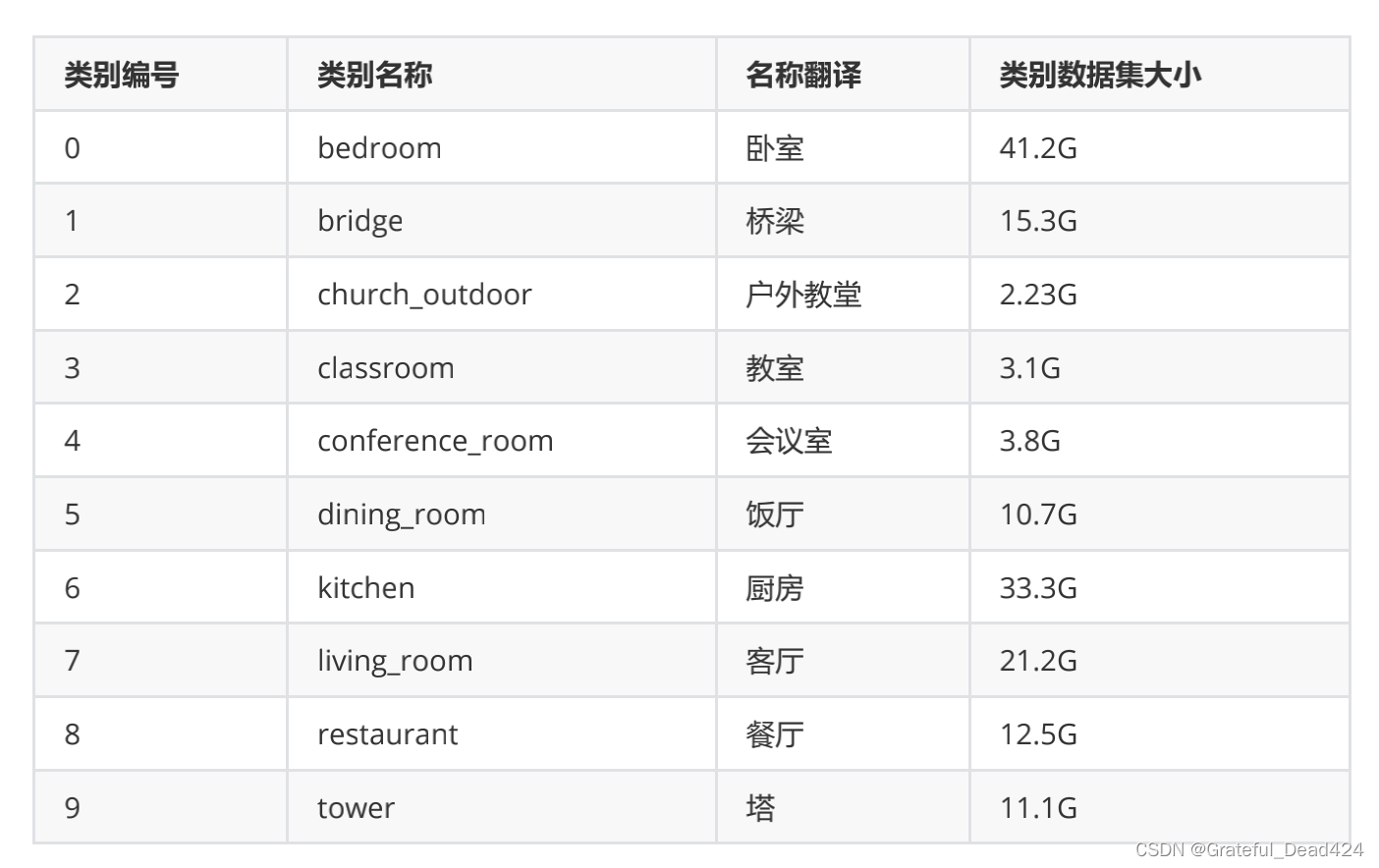
对类似于LSUN的数据集,我们会按照标签类别分别对数据进行下载,如果下载后获得的数据是这个类别下的图片文件,那毫无疑问这些文件是可以按照类别被储存在单独的文件夹里的。此时我们就可以使用ImageFolder来对数据进行读取。当然了,如果你的数据不是按照标签类别进行下载,或你的标签类别是单独储存在excel或txt文件当中,我们就需要别的操作来读取数据了。
使用ImageFolder读取后的数据是无法轻易更改标签的,这是因为ImageFolder继承自pytorch中的visiondataset类,标签在这个父类中生成,并与特征图一起被固定为一个元组(用来表示从特征到标签的映射)。我们可以通过ImageFolder的各种属性、或索引等方式调用出这个元组的一份复制来进行展示,却无法直接触及到元组中的数据本身,因此我们无法通过ImageFolder的读取出的标签进行改变。虽然我们可以先从ImageFolder的结果中复制出特征图,再使用TensorDatasets重新对特征图和标签进行拼接,但Python并不支持对元组的批量操作,如果需要复制每个特征图,就必须对每个元组进行循环。但当数据量很大时,从ImageFolder的结果中提取全部样本就会需要很多时间和算力。因此,当数据不能按照类别进行下载时,大部分深度学习研究者都不会使用ImageFolder对数据进行读取,而会选择更加灵活的方式:自己写一个读取数据用的类。
CLASS torch.utils.data.Dataset
在PyTorch中存在一个专门帮助我们构筑数据集的类Dataset,这个类在torch.utils.data模块下,属于PyTorch中数据处理的经典父类之一(另一个我们总是使用的经典父类是nn.Module)。在PyTorch中,许多torchvision.datasets中读数据的类,以及TensorDataset这些合并张量来生成数据的类,都继承自Dataset。如果一个读取数据的类继承自Dataset,那它读取出的数据一定是可以通过索引的方式进行调用和查看的,而继承自其他父类的、读取数据集的功能却不一定能使用索引进行查看,这种性质让Dataset子类的构成也与其他类不同。
Dataset中规定,如果一个子类要继承Dataset,则必须在子类中定义 getitem() 方法。从这个方法的名字(get item,获取对象)也可以看出,它是帮助我们“获取对象”的方法。这个方法中的代码必须满足三个功能:
- 1)读取单个图片并转化为张量
- 2)读取该图片对应的标签
- 3)将该图片的张量与对应标签打包成一个样本并输出
该样本的形式是一个元组,元组中的第一个对象是图像张量,第二个对象是该图像对应的标签。
Dataset类中包含自动循环 getitem() 并拼接其输出结果的功能。也就是说,对于任意继承自Dataset的子类,只要我们恰当地定义了 getitem() ,该子类的输出就一定是打包好的整个数据集。我们可以根据数据的实际情况定义 getitem() ,可以说是实现了最大程度上的灵活性。
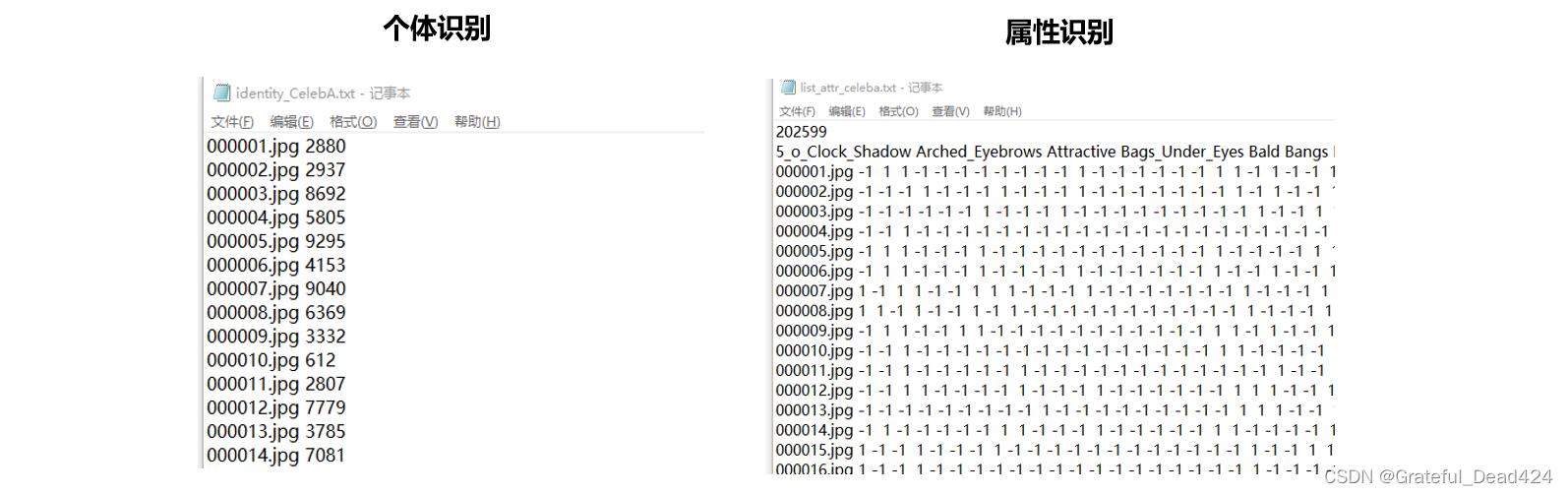
现在,我们使用celebA数据集举个例子。完整的celebA数据集中包含图片20万+张(图像大小20G),其中个体识别的标签为“人名”,类别有10,177个,属性识别的标签有40个,每个标签下是二分类,两种标签类别在txt中的格式不同。如果你感兴趣源文件,你可以在课程数据集的dataset3中找到它。将压缩文件解压后,即可获得具体的图像。
在课程中,我准备包含1000张图片的celebA的子集,在dataset4\picturetotensor\celebAsubset文件夹中。
这个文件夹中的目录层次与dataset3中的celebA的原始数据集完全一致,只不过这个文件夹的图像和标签都只有前一千个样本。该子集仅作为读取数据用的例图,并不能被用于建模,如果需要建模请使用原始的20G大小的完整数据集。
在例图上,我们将展示如何使用继承自Dataset的类读取不同的图片和标签类别,你可以自由将数据更换为你的数据进行相同的操作。以下是我的根目录、个体识别的标签txt以及属性识别的标签txt:
在写具体的类之前,我们可以先定义 getitem() 方法中要求的内容,试着读取一张图片并生成样本的元组。在CV课程最开始的时候,我们使opencv中的cv.imread函数进行过图像的读取。事实上,有大量的库中都包含能够将图像转化为像素值的函数,原则上我们可以使用任何自己熟悉的函数。在本节课中我们pytorch官方推荐的scikit-learn图像处理库scikit-image来进行处理,只要你的环境中安装有sklearn,你应该都已经有scikit-image库。我们可以通过下面的代码进行检查:
import skimage
如果你导入失败,则需要执行以下代码进行安装。执行该代码时注意关闭VPN,若在cmd中执行则需要去掉开头的感叹号。
!pip install scikit-image -i http://pypi.douban.com/simple --trusted-host
pypi.douban.com
有了skimage,我们来试着读取一张图片及其标签,并处理成样本元组。
from skimage import io
import pandas as pd
import torch
import os
#读取一张图片
io.imread("/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba/000001.jpg")
#array([[[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# [[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# [[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# ...,
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [243, 173, 122],
# [234, 170, 122],
# [239, 178, 131]],
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [251, 180, 126],
# [237, 174, 123],
# [238, 178, 128]],
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [255, 184, 128],
# [242, 177, 123],
# [239, 179, 127]]], dtype=uint8)
#读取我们的标签 - identity个体识别标签
identity = pd.read_csv("/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt"
,sep = " "
,header = None)
identity.head()
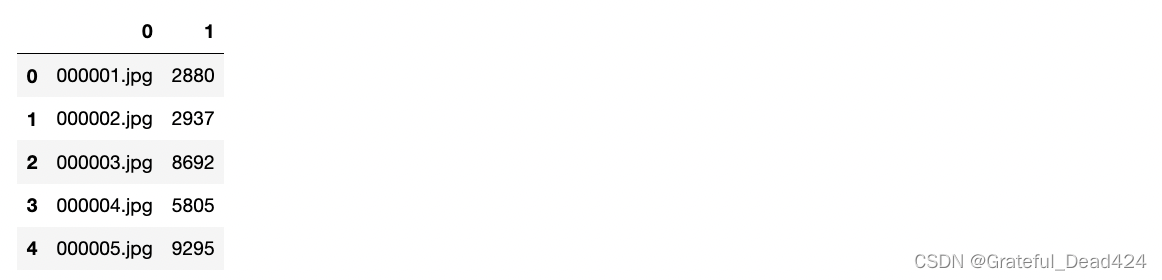
identity.iloc[0,0]
#'000001.jpg'
imgpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba"
csvpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt"
imgdic = os.path.join(imgpath,identity.iloc[0,0])
imgdic
#'/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba/000001.jpg'
identity.iloc[0,1]
#2880
io.imread(imgdic)
#array([[[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# [[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# [[253, 231, 192],
# [253, 231, 192],
# [253, 231, 192],
# ...,
# [254, 244, 219],
# [254, 244, 219],
# [254, 244, 219]],
#
# ...,
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [243, 173, 122],
# [234, 170, 122],
# [239, 178, 131]],
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [251, 180, 126],
# [237, 174, 123],
# [238, 178, 128]],
#
# [[253, 218, 176],
# [253, 218, 176],
# [253, 218, 176],
# ...,
# [255, 184, 128],
# [242, 177, 123],
# [239, 179, 127]]], dtype=uint8)
idx = 20
imgpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba"
csvpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt"
imgdic = os.path.join(imgpath,identity.iloc[idx,0]) #图像目录
image = io.imread(imgdic) #提取出的,索引为idx的图像的像素值矩阵
label = identity.iloc[idx,1]
sample = (torch.tensor(image),int(label))
sample
#(tensor([[[150, 122, 111],
# [149, 121, 110],
# [147, 119, 108],
# ...,
# [125, 150, 170],
# [123, 149, 172],
# [118, 146, 170]],
#
# [[148, 120, 109],
# [147, 119, 108],
# [145, 117, 106],
# ...,
# [114, 137, 155],
# [114, 139, 161],
# [111, 137, 160]],
#
# [[145, 117, 106],
# [145, 117, 106],
# [143, 115, 104],
# ...,
# [ 99, 120, 137],
# [102, 125, 143],
# [100, 125, 145]],
#
# ...,
#
# [[ 32, 25, 41],
# [ 43, 32, 48],
# [ 44, 30, 43],
# ...,
# [ 39, 28, 34],
# [ 42, 31, 35],
# [ 46, 35, 39]],
#
# [[ 31, 24, 40],
# [ 43, 32, 48],
# [ 46, 32, 45],
# ...,
# [ 38, 27, 33],
# [ 40, 29, 33],
# [ 46, 35, 39]],
#
# [[ 26, 19, 35],
# [ 40, 29, 45],
# [ 45, 31, 44],
# ...,
# [ 36, 25, 31],
# [ 39, 28, 32],
# [ 46, 35, 39]]], dtype=torch.uint8),
# 181)
plt.imshow(image)

这种方式要求txt中所写的文件名必须与图像的文件名一致,当图像的名称与txt中所写的内容不一致时,就需要更改代码。比如,celebA数据集中,提供了原始图像和预处理过的图像。原始图像为jpg格式,预处理过的图像为png格式。当我们需要读取png,而标签中的图片名称都是.jpg格式,我们就需要对identity进行二次处理。
#更换文件拓展名
#identity是个体识别的标签
identity2 = identity.copy()
identity2["2"] = [x[:-3] + "png" for x in identity2.iloc[:,0]]
identity2.head()
imgpath =
csvpath =
imgdic = os.path.join(imgpath,identity2.iloc[idx,2])
image = torch.tensor(io.imread(imgdic))
sample = (image,int(identity.iloc[idx,1]))
image.shape
sample
plt.imshow(image)
不难发现,无论是特征图发生变化,还是标签发生变化,我们都需要对代码进行具体的调整。在实际数据中,我们可能遇见已经分好训练集、测试集,并且两个数据集的索引用txt标注的情况,也可能会遇见完全没有区分训练集测试集,因此需要自己进行分割的情况。还可能会遇见,需要读取各种各样格式的数据、需要对数据进行各种各样操作的情况。但无论我们如何调整代码,只要将代码包装到Dataset子类的 getitem() 方法中即可。现在以jpg格式下、个体识别为例,我们来定义子类:
from torch.utils.data import Dataset
import numpy as np
import pandas as pd
from skimage import io
import torch, torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
import random
class CustomDataset(Dataset):
"""
自定义数据集,用于读取celebA数据集中的个体识别(identity recognition)数据的标签和图像
图像格式为jpg
"""
def __init__(self,csv_file, root_dir, transform = None):
"""
参数说明:
csv_file (字符串): 标签csv/txt的具体地址
root_dir (string): 所有图片所在的根目录
transform (callable, optional): 选填,需要对样本进行的预处理
"""
super().__init__()
self.identity = pd.read_csv(csv_file,sep=" ",header=None)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
#展示数据中总共有多少个样本
return len(self.identity)
def __info__(self):
print("CustomData")
print("\t Number of samples: {}".format(len(self.identity)))
print("\t Number of classes: {}".format(len(np.unique(self.identity.iloc[:,1]))))
print("\t root_dir: {}".format(self.root_dir))
def __getitem__(self,idx): #读图片和标签,形成元组 #实现可以索引的功能
#保证idx不是一个tensor
if torch.is_tensor(idx):
idx = idx.tolist()
imgdic = os.path.join(self.root_dir,self.identity.iloc[idx,0]) #图像目录
image = io.imread(imgdic) #提取出的,索引为idx的图像的像素值矩阵
label = self.identity.iloc[idx,1]
if self.transform != None:
image = self.transform(image)
sample = (image,label)
return sample
imgpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba"
csvpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt"
data = CustomDataset(csvpath,imgpath)
data[20]
#(array([[[150, 122, 111],
# [149, 121, 110],
# [147, 119, 108],
# ...,
# [125, 150, 170],
# [123, 149, 172],
# [118, 146, 170]],
#
# [[148, 120, 109],
# [147, 119, 108],
# [145, 117, 106],
# ...,
# [114, 137, 155],
# [114, 139, 161],
# [111, 137, 160]],
#
# [[145, 117, 106],
# [145, 117, 106],
# [143, 115, 104],
# ...,
# [ 99, 120, 137],
# [102, 125, 143],
# [100, 125, 145]],
#
# ...,
#
# [[ 32, 25, 41],
# [ 43, 32, 48],
# [ 44, 30, 43],
# ...,
# [ 39, 28, 34],
# [ 42, 31, 35],
# [ 46, 35, 39]],
#
# [[ 31, 24, 40],
# [ 43, 32, 48],
# [ 46, 32, 45],
# ...,
# [ 38, 27, 33],
# [ 40, 29, 33],
# [ 46, 35, 39]],
#
# [[ 26, 19, 35],
# [ 40, 29, 45],
# [ 45, 31, 44],
# ...,
# [ 36, 25, 31],
# [ 39, 28, 32],
# [ 46, 35, 39]]], dtype=uint8),
# 181)
data.__len__()
#1000
data.__info__()
#CustomData
# Number of samples: 1000
# Number of classes: 922
# root_dir: F:\datasets4\picturestotensor\celebAsubset\Img\Img_celeba.7z\img_celeba
for x,y in data:
print(x.shape)
print(y)
break
#(687, 409, 3)
#2880
读取属性识别的标签
imgpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba"
csvpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/list_attr_celeba_1000.txt"
attr_ = pd.read_csv(csvpath,header=None)
attr_.head()
len(attr_.iloc[0,0].split()) #默认帮我按空格进行分类,它会把多个空格也当成一个空格
#41
attr_ = pd.DataFrame(attr_.iloc[1:,0].str.split().tolist(),
columns = attr_.iloc[0,0].split())
attr_.head()

attr_.loc[:,"Attractive"]
#0 1
#1 -1
#2 -1
#3 1
#4 1
# ..
#995 -1
#996 1
#997 1
#998 -1
#999 1
#Name: Attractive, Length: 1000, dtype: object
class CustomDataset_attr(Dataset):
"""
自定义数据集,用于读取celebA数据集中的属性识别(attribute recognition)数据的标签和图像
图像格式为jpg
"""
def __init__(self,csv_file, root_dir, labelname, transform = None):
"""
参数说明:
csv_file (字符串): 标签csv/txt的具体地址
root_dir (string): 所有图片所在的根目录
transform (callable, optional): 选填,需要对样本进行的预处理
"""
super().__init__()
self.attr_ = pd.read_csv(csvpath,header=None)
self.root_dir = root_dir
self.labelname = labelname
self.transform = transform
def __len__(self):
#展示数据中总共有多少个样本
return len(self.attr_)
def __info__(self):
print("CustomData")
print("\t Number of samples: {}".format(len(self.attr_)-1))
print("\t root_dir: {}".format(self.root_dir))
def __getitem__(self,idx):
#保证idx不是一个tensor
if torch.is_tensor(idx):
idx = idx.tolist()
self.attr_ = pd.DataFrame(self.attr_.iloc[1:,0].str.split().tolist(),
columns = self.attr_.iloc[0,0].split())
imgdic = os.path.join(self.root_dir,self.attr_.iloc[idx,0]) #图像目录
image = io.imread(imgdic) #提取出的,索引为idx的图像的像素值矩阵
label = int(self.attr_.loc[idx,self.labelname])
if self.transform != None:
image = self.transform(image)
sample = (image,label)
return sample
imgpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba"
csvpath = "/Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Anno/list_attr_celeba_1000.txt"
labelname = "Attractive"
data = CustomDataset_attr(csvpath,imgpath,labelname)
data
#<__main__.CustomDataset_attr at 0x7ff4892a9e20>
data.__info__()
#CustomData
# Number of samples: 1000
# root_dir: /Users/zhucan/Desktop/datasets4/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba
data[500]
# (array([[[ 56, 44, 32],
# [ 56, 44, 32],
# [ 56, 44, 32],
# ...,
# [ 46, 38, 19],
# [ 46, 38, 19],
# [ 46, 38, 19]],
# [[ 56, 44, 32],
# [ 56, 44, 32],
# [ 56, 44, 32],
# ...,
# [ 46, 38, 19],
# [ 46, 38, 19],
# [ 46, 38, 19]],
# [[ 56, 44, 32],
# [ 56, 44, 32],
# [ 56, 44, 32],
# ...,
# [ 46, 38, 19],
# [ 46, 38, 19],
# [ 46, 38, 19]],
# ...,
# [[ 54, 52, 37],
# [ 53, 51, 36],
# [ 53, 51, 36],
# ...,
# [196, 210, 211],
# [197, 211, 212],
# [198, 212, 213]],
# [[ 56, 54, 39],
# [ 55, 53, 38],
# [ 55, 53, 38],
# ...,
# [197, 211, 212],
# [198, 212, 213],
# [199, 213, 214]],
# [[ 57, 55, 40],
# [ 57, 55, 40],
# [ 56, 54, 39],
# ...,
# [199, 213, 214],
# [200, 214, 215],
# [201, 215, 216]]], dtype=uint8),
# 1)
如此,我们就实现了自定义数据集的调用,你现在已经可以使用上面的方式自由调用celebA数据,并且可以自由换分数据集。根据具体的标签和图像情况,你可以修改上述代码,并将上述的类用于任何你希望读取的数据。
值得讨论的一点是,当数据量很小的时候,我们使用Customdataset可以很轻松地将数据读取进来,但当数据大小为20个G,数据量超过20万时,我们还能够如此轻松地读取数据吗?答案是肯定的。我们在课程中使用子集,并不是因为数据量过大无法被读取,而是因为数据量过大很难被下载。事实上,PyTorch和skimage在读取图片数据集时,并不会将所有的图片提取出来放入缓存,而是对每一张图片进行读取后,只储存它的PIL格式或像素表示,因此20G的数据集也可以被很轻松地读入一台普通个人电脑的jupyter或pycharm。相对的,如果一个csv文件有好几个G,那读取就会比较痛苦了。当然了,20万张图片的张量表示也并不是一个很小的文件,但是肯定是远远小于20个G的。因此,在做出正确的调整后,CustomDataset也可以读取150G的数据ImageNet,如果你下载了完整的数据集,你可以尝试看看。

