1,REINFORCE
在车杆环境中进行 REINFORCE 算法的实验:
import gym import torch import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt from tqdm import tqdm import rl_utils首先定义策略网络?
PolicyNet,其输入是某个状态,输出则是该状态下的动作概率分布,这里采用在离散动作空间上的?softmax()函数来实现一个可学习的多项分布。class PolicyNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim, action_dim): super(PolicyNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, action_dim) def forward(self, x): x = F.relu(self.fc1(x)) return F.softmax(self.fc2(x), dim=1)再定义我们的 REINFORCE 算法。在函数
take_action()函数中,我们通过动作概率分布对离散的动作进行采样。在更新过程中,我们按照算法将损失函数写为策略回报的负数,即,对求导后就可以通过梯度下降来更新策略。class REINFORCE: def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device): self.policy_net = PolicyNet(state_dim, hidden_dim,action_dim).to(device) self.optimizer = torch.optim.Adam(self.policy_net.parameters(),lr=learning_rate) # 使用Adam优化器 self.gamma = gamma # 折扣因子 self.device = device def take_action(self, state): # 根据动作概率分布随机采样 state = torch.tensor([state], dtype=torch.float).to(self.device) probs = self.policy_net(state) action_dist = torch.distributions.Categorical(probs) action = action_dist.sample() return action.item() def update(self, transition_dict): reward_list = transition_dict['rewards'] state_list = transition_dict['states'] action_list = transition_dict['actions'] G = 0 self.optimizer.zero_grad() for i in reversed(range(len(reward_list))): # 从最后一步算起 reward = reward_list[i] state = torch.tensor([state_list[i]],dtype=torch.float).to(self.device) action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device) log_prob = torch.log(self.policy_net(state).gather(1, action)) G = self.gamma * G + reward loss = -log_prob * G # 每一步的损失函数 loss.backward() # 反向传播计算梯度 self.optimizer.step() # 梯度下降learning_rate = 1e-3 num_episodes = 1000 hidden_dim = 128 gamma = 0.98 device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") env_name = "CartPole-v0" env = gym.make(env_name) env.seed(0) torch.manual_seed(0) state_dim = env.observation_space.shape[0] action_dim = env.action_space.n agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma,device) return_list = [] for i in range(10): with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar: for i_episode in range(int(num_episodes / 10)): episode_return = 0 transition_dict = { 'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': [] } state = env.reset() env.render() done = False while not done: action = agent.take_action(state) next_state, reward, done, _ = env.step(action) transition_dict['states'].append(state) transition_dict['actions'].append(action) transition_dict['next_states'].append(next_state) transition_dict['rewards'].append(reward) transition_dict['dones'].append(done) state = next_state episode_return += reward return_list.append(episode_return) agent.update(transition_dict) if (i_episode + 1) % 10 == 0: pbar.set_postfix({ 'episode': '%d' % (num_episodes / 10 * i + i_episode + 1), 'return': '%.3f' % np.mean(return_list[-10:]) }) pbar.update(1)在 CartPole-v0 环境中,满分就是 200 分,我们发现 REINFORCE 算法效果很好,可以达到 200 分。接下来我们绘制训练过程中每一条轨迹的回报变化图。由于回报抖动比较大,往往会进行平滑处理。
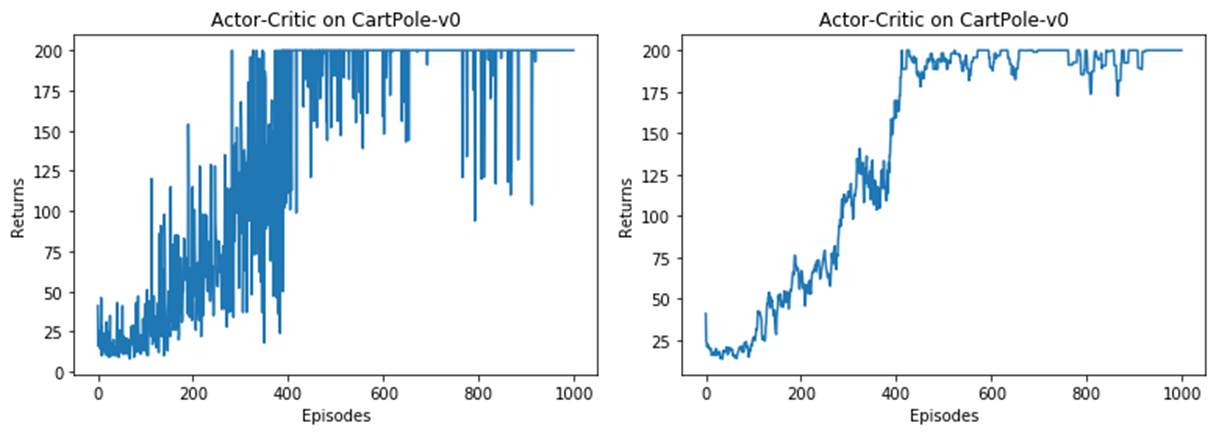
episodes_list = list(range(len(return_list))) plt.plot(episodes_list, return_list) plt.xlabel('Episodes') plt.ylabel('Returns') plt.title('REINFORCE on {}'.format(env_name)) plt.show() mv_return = rl_utils.moving_average(return_list, 9) plt.plot(episodes_list, mv_return) plt.xlabel('Episodes') plt.ylabel('Returns') plt.title('REINFORCE on {}'.format(env_name)) plt.show()可以看到,随着收集到的轨迹越来越多,REINFORCE 算法有效地学习到了最优策略。不过,相比于前面的 DQN 算法,REINFORCE 算法使用了更多的序列,这是因为 REINFORCE 算法是一个在线策略算法,之前收集到的轨迹数据不会被再次利用。此外,REINFORCE 算法的性能也有一定程度的波动,这主要是因为每条采样轨迹的回报值波动比较大,这也是 REINFORCE 算法主要的不足。
2,Actor-Critic算法
仍然在 Cartpole 环境上进行 Actor-Critic 算法的实验。
import gym import torch import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt import rl_utils定义我们的策略网络 PolicyNet,与 REINFORCE 算法中一样。
class PolicyNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim, action_dim): super(PolicyNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, action_dim) def forward(self, x): x = F.relu(self.fc1(x)) return F.softmax(self.fc2(x),dim=1)Actor-Critic 算法中额外引入一个价值网络,接下来的代码定义我们的价值网络 ValueNet,输入是状态,输出状态的价值。
class ValueNet(torch.nn.Module): def __init__(self, state_dim, hidden_dim): super(ValueNet, self).__init__() self.fc1 = torch.nn.Linear(state_dim, hidden_dim) self.fc2 = torch.nn.Linear(hidden_dim, 1) def forward(self, x): x = F.relu(self.fc1(x)) return self.fc2(x)再定义我们的 ActorCritic 算法。主要包含采取动作和更新网络参数两个函数。
class ActorCritic: def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device): self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device) self.critic = ValueNet(state_dim, hidden_dim).to(device) # 价值网络 self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr) self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr) # 价值网络优化器 self.gamma = gamma def take_action(self, state): state = torch.tensor([state], dtype=torch.float) probs = self.actor(state) action_dist = torch.distributions.Categorical(probs) action = action_dist.sample() return action.item() def update(self, transition_dict): states = torch.tensor(transition_dict['states'], dtype=torch.float) actions = torch.tensor(transition_dict['actions']).view(-1, 1) rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1) next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float) dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1) td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones) # 时序差分目标 td_delta = td_target - self.critic(states) # 时序差分误差 log_probs = torch.log(self.actor(states).gather(1, actions)) actor_loss = torch.mean(-log_probs * td_delta.detach()) critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach())) # 均方误差损失函数 self.actor_optimizer.zero_grad() self.critic_optimizer.zero_grad() actor_loss.backward() # 计算策略网络的梯度 critic_loss.backward() # 计算价值网络的梯度 self.actor_optimizer.step() # 更新策略网络参数 self.critic_optimizer.step() # 更新价值网络参数
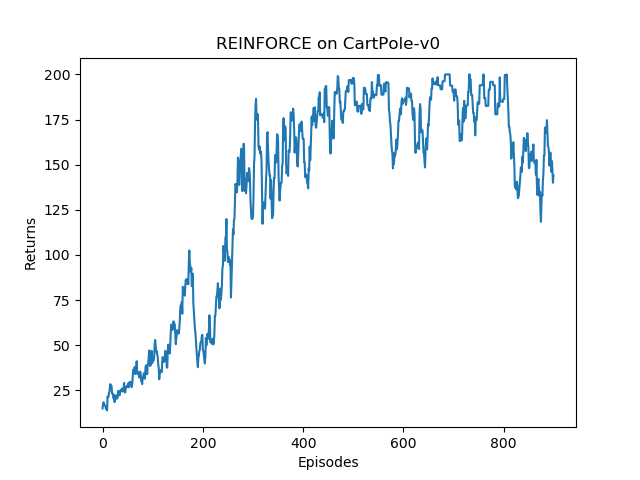
根据实验结果我们发现,Actor-Critic 算法很快便能收敛到最优策略,并且训练过程非常稳定,抖动情况相比 REINFORCE 算法有了明显的改进,这多亏了价值函数的引入减小了方差。