《Long-tailed Visual Recognition via Gaussian Clouded Logit
AdjustmentAdjustme》
设{x, y}∈T表示训练集T中的一个样本{x, y}, C类中有N个样本,且y∈{1,…, C}是ground truth标签。输入图像x的softmax损失函数为:
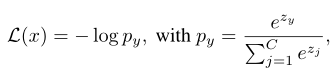
其中zj表示类j的预测logit。我们用下标y表示目标类,即zy表示目标logit, zj表示非目标logit, j≠ y表示非目标logit。
在反向传播中,zi上的梯度由:
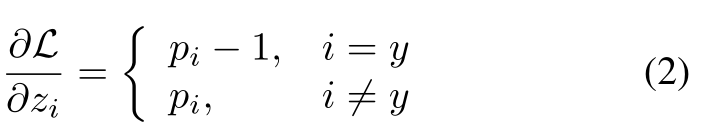
在不损失一般性的情况下,我们使用二进制分类来说明。假设x来自第1类,则z1上的梯度计算为:
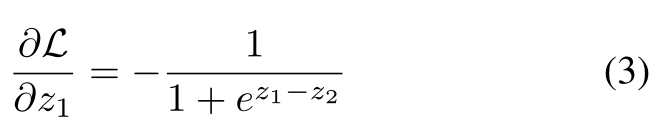
3.3 Classifier Re-balance
由式(2)导出的梯度表明,目标类y的样本惩罚非目标类j的分类器权值wj, j≠y w.r.t. pj。
头类比尾类有更多的训练实例。因此,在训练过程中,尾部类的分类器权重比正信号受到更多的惩罚。因此,分类器会对头部类产生偏倚,尾部类的预测对数会受到严重抑制,导致尾部类的分类精度较低。
一种简单的方法是使用重新采样的数据重新训练分类器。我们采用了Kang等人[10]和Wang等人[33]采用的分类器再训练(cRT)。由于GCL损失使得不同类别的样本参与训练的程度不同,因此不同类别样本的有效性是不同的。
类平衡抽样将导致尾类的重复训练。利用Cui等人[4]提出的有效数,我们提出了基于类的有效数(class-based effective number, CBEN)抽样,以避免尾部类的过度训练。
对于类j中的一个样本ρi的抽样概率由:
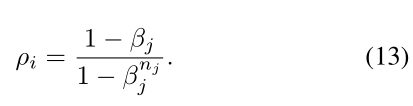
由于所有数据的抽样概率之和需要为1,我们需要将ρi归一化,
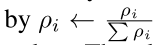
βj反映了不同类别样本的效度。云大小较大的类样本参与训练的次数较多。因此,βj与云大小δj呈正相关。设βj为:
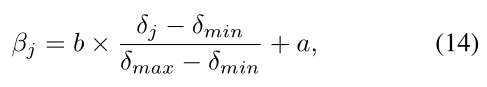
因此βj可以在区域[a, a + b]中,其中a和b是范围超参数。
算法1总结了该方法的整体训练过程。

