import numpy as np
import pandas as pd
from scipy.cluster.vq import *
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from scipy.spatial.distance import cdist
from matplotlib.ticker import MultipleLocator
from matplotlib import style
from sklearn.model_selection import train_test_split
%matplotlib inline
from scipy import stats, integrate
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn中文乱码解决方案
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=20)
sns.set(font=myfont.get_name(), color_codes=True)
####
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import Binarizer
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.feature_selection import VarianceThreshold
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
from sklearn.tree import export_graphviz
# from sklearn.externals.six import StringIO #pip install six from six import StringIO
import pydotplus #conda install pydotplus
from IPython.core.display import Image
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectFromModel
from sklearn.feature_selection import RFE
#
# import graphviz
from sklearn.datasets import load_boston #准备导入数据集,若无法获取远程,则尽可能将数据存储在本地
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
lidf=pd.read_excel('lypdata.xlsx')
lidf.iloc[:,1:-1]

观察上面数据:森林覆盖率产业结构是百分比,与其他列数据的差别较大
一、归一化处理
#最后列保留 lypdata
#实现归一化 三个步骤
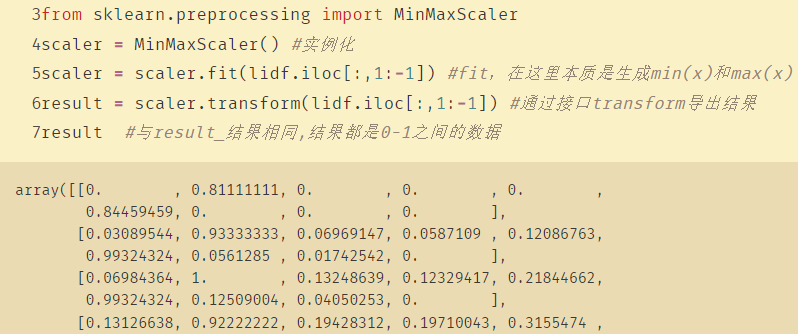
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(lidf.iloc[:,1:-1]) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(lidf.iloc[:,1:-1]) #通过接口transform导出结果
result #与result_结果相同,结果都是0-1之间的数据
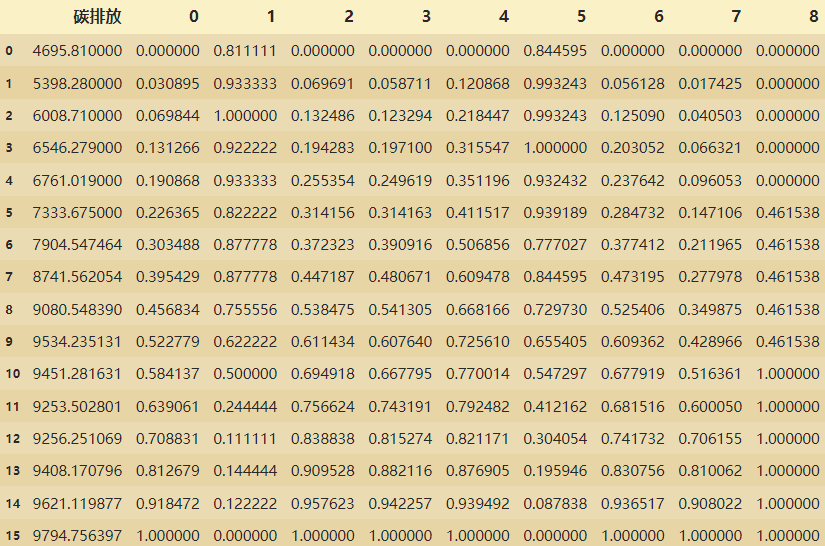
#与之前的数据进行合并
lidf22=pd.concat([lidf,pd.DataFrame(result)],axis=1)
lidf22.drop(['年份','经济水平','产业结构','人口规模','城市化水平','能源消费总量','能源结构','电力消费','交通发展水平','森林覆盖率'],axis=1,inplace=True)
lidf22
归一化之后的数据,:
lidf22.columns=(['碳排放','经济水平','产业结构','人口规模','城市化水平','能源消费总量','能源结构','电力消费','交通发展水平','森林覆盖率'])
lidf22
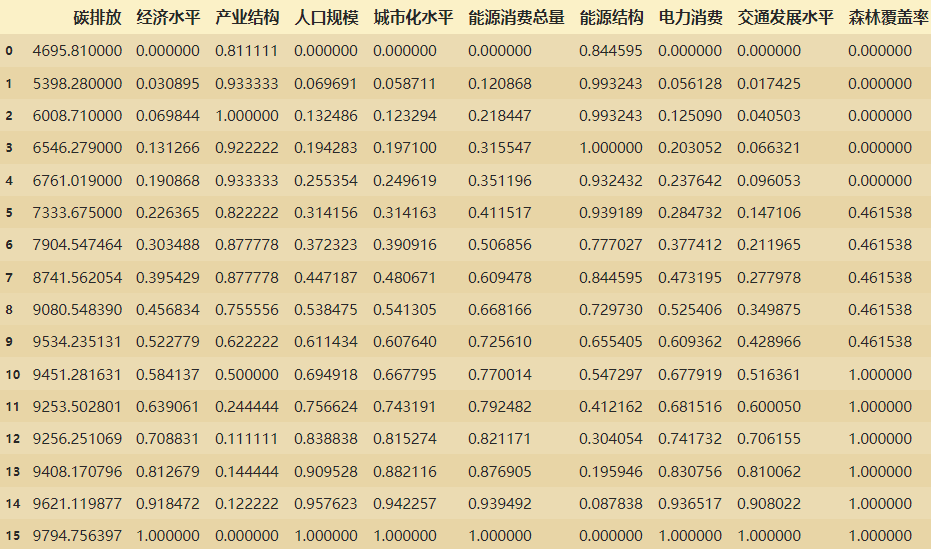
对lidf22数据的碳排放量进行分桶:分成三桶
import pandas as pd
label=[0,1,2]
k=3
lidftpf=lidf22['碳排放'].copy() #函数中一定要使用data!!!去改函数
pingjia=pd.cut(lidftpf,k,labels=label)
pingjia
pd.DataFrame(pingjia).rename(columns={'碳排放':'评价'})
#使用concate进行合并
lidf23=pd.concat([lidf22,pd.DataFrame(pingjia).rename(columns={'碳排放':'评价'})],axis=1)
# 取出碳排放列,使用评价列来表示
lidf23.drop(['碳排放'],axis=1,inplace=True)
lidf23
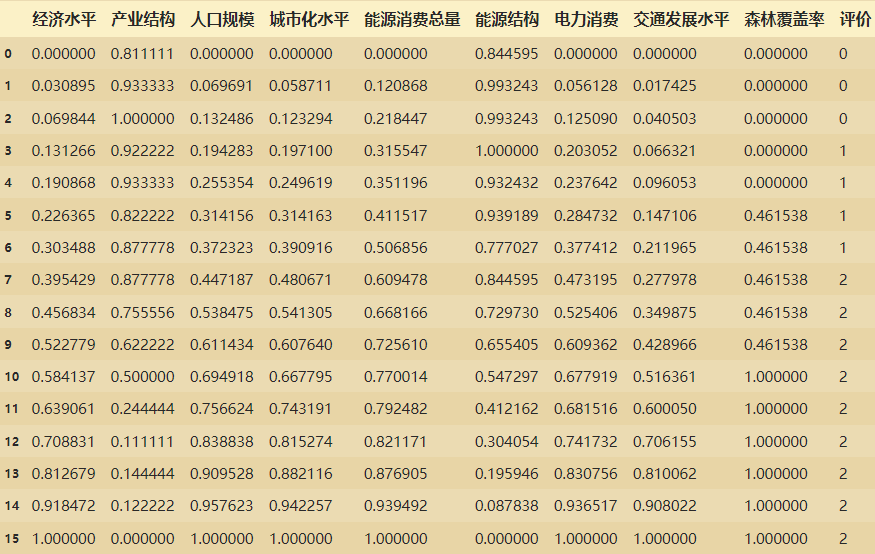
# seaborn中文乱码解决方案
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=20)
sns.set(font=myfont.get_name(), color_codes=True)
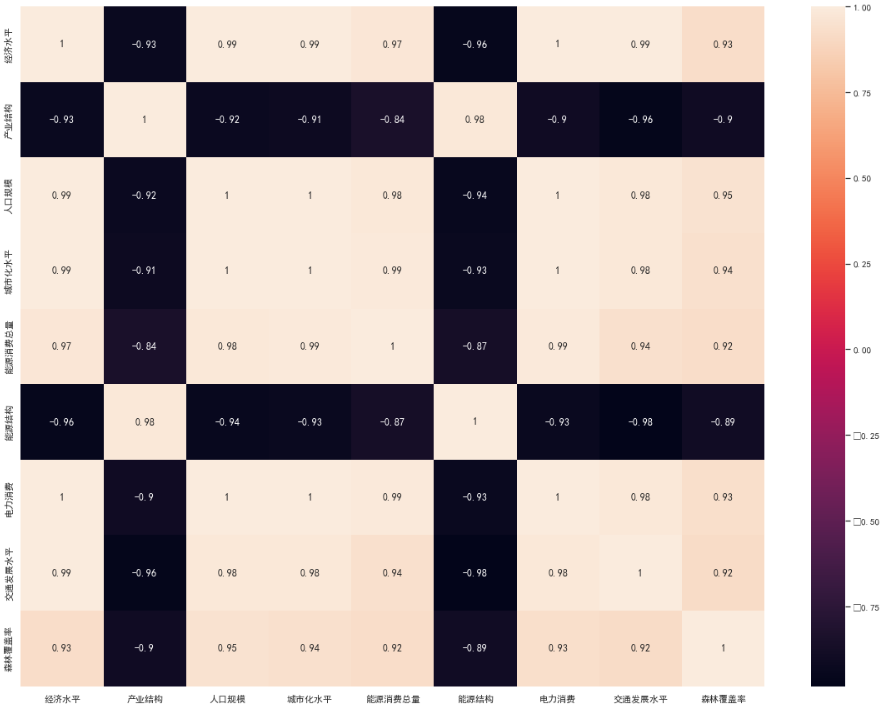
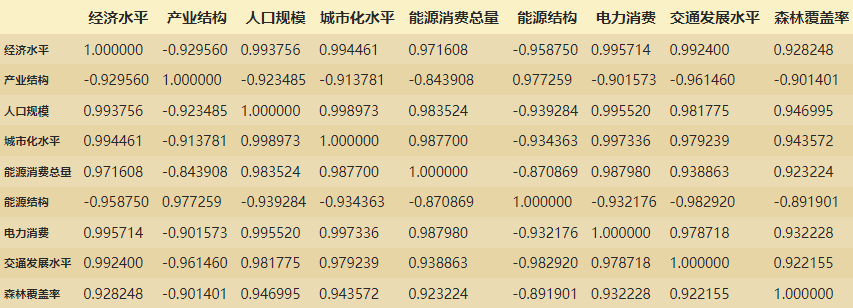
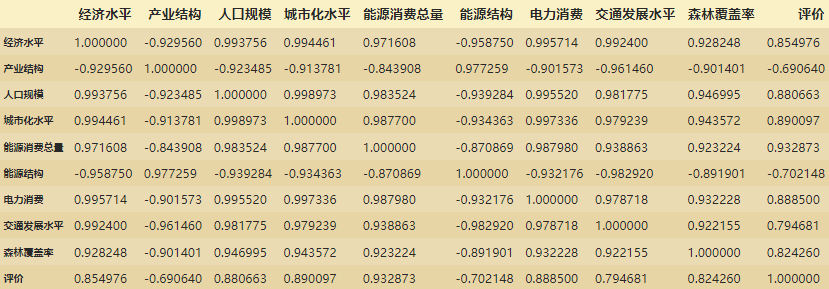
lidf_corr = lidf23.corr()#计算相关性系数
plt.figure(figsize=(20,15))#figsize可以规定热力图大小
fig=sns.heatmap(lidf_corr,annot=True,fmt='.2g')#annot为热力图上显示数据;fmt='.2g'为数据保留两位有效数字
fig
# fig.get_figure().savefig('lidf_corr.png')#保留图片
得到的图片如下,黑色的数据的数值是负数
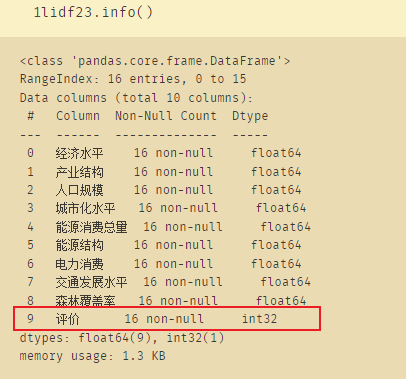
data=pd.read_csv("tanpaifang.csv")# 手写体数字特征提取
X=data.iloc[:,1:] # 前面的标签不要
只有16行样本数,特征只有9个
(1)过滤特征
首先使用方差过滤,将相关特征进行过滤:
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵
#也可以直接写成 X = VairanceThreshold().fit_transform(X)
X_var0.shape #去掉几个?

#中位值只取四个特征?
import numpy as np
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X) #取出一半特征,如果是TOP N呢?对X.var()进行排序,比方差阈值小的全部去掉
X.var().values
np.median(X.var().values)
X_fsvar.shape
中位数只取3个特征:

(2)使用KNN和随机森林考察方差过滤对模型的影响:
#01.02 使用KNN和随机森林考察方差过滤对模型的影响
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
import numpy as np
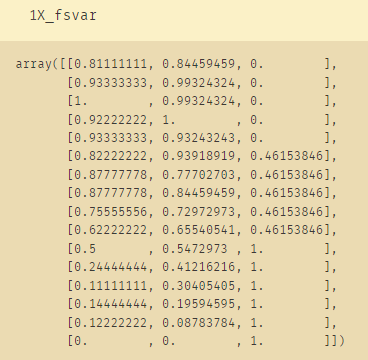
X=lidf23.iloc[:,:-1] # X是除了评价以外的其他列
y=lidf23.iloc[:,-1] # y是评价列
X_fsvar=VarianceThreshold(np.median(X.var().values)).fit_transform(X)
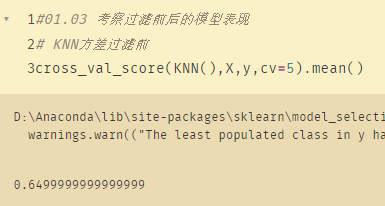
(3)考察过滤前后的模型表现
考察过滤前后的模型表现
# KNN方差过滤前
cross_val_score(KNN(),X,y,cv=5).mean()
# KNN方差过滤后
cross_val_score(KNN(),X_fsvar,y,cv=5).mean()
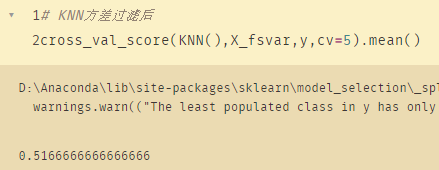
可以看到过滤之后的准确性下降了,连60%都不到。
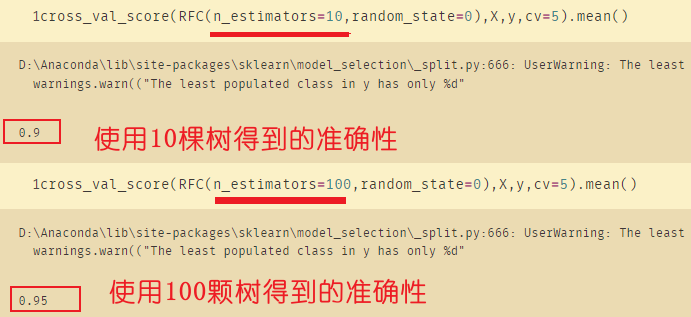
使用随机森林提升准确度:
cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
cross_val_score(RFC(n_estimators=100,random_state=0),X,y,cv=5).mean()
这里必须使用全部的数据,因为本身数据量就小,如果数据量十分大的话才需要使用过滤法过滤掉关系较小的数据。
二、相关性过滤
lidf23.corr(method="pearson") # 相关系数矩阵,即给出了任意两个变量之间的相关系数
# pearson:相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
发现上面的数据少了一列评价,原因在于评价的数据类型是category类型,因此先将评价转换为int类型:
lidf23=lidf23.astype({'评价':'int'})

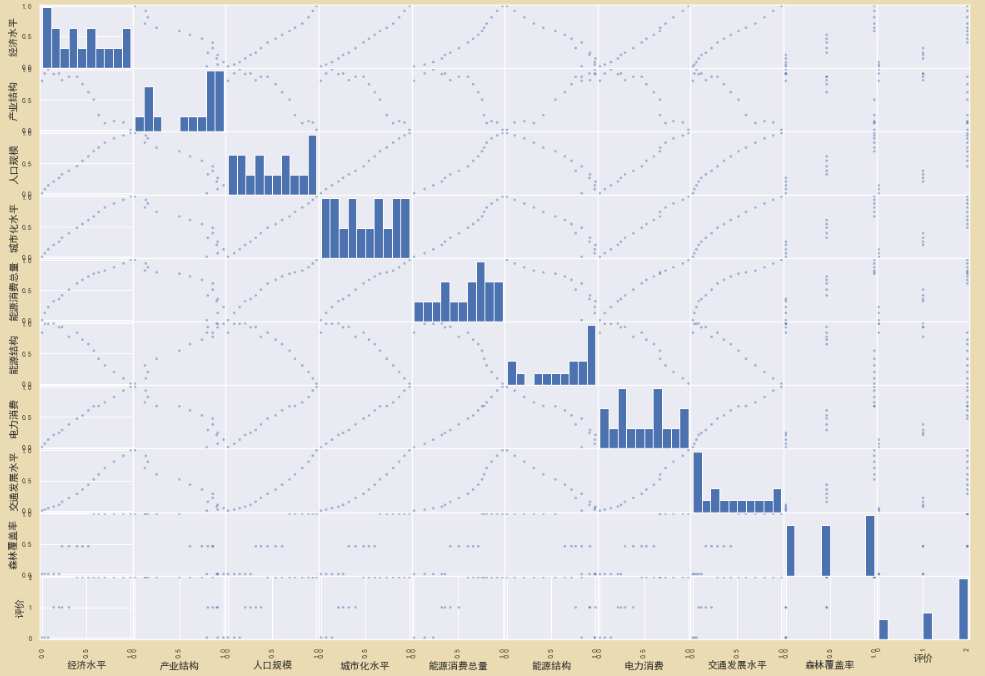
画出散点图,矩阵图:
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest #k个分数最高的
from sklearn.feature_selection import chi2
#取3个特征
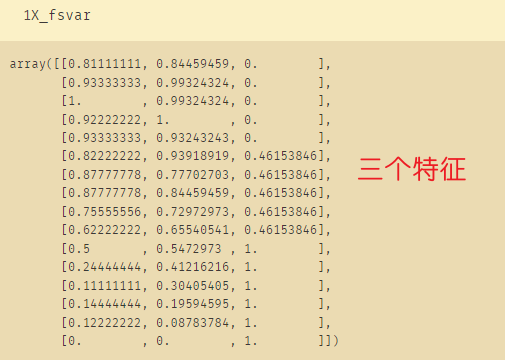
X_fschi = SelectKBest(chi2, k=3).fit_transform(X_fsvar, y)
#使用方差过滤后的数据X_fsvar # 这里K=3是根据X_fvar得来的
X_fschi.shape
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest #k个分数最高的
from sklearn.feature_selection import chi2
#取3个特征
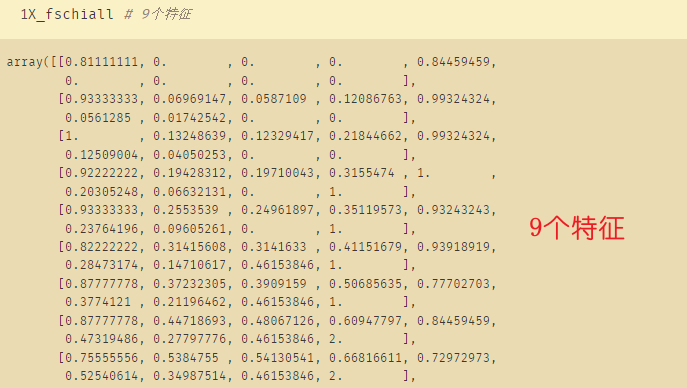
X_fschiall = SelectKBest(chi2, k=9).fit_transform(X, y) # 全集的话就可以K=9,取9个特征
#使用方差过滤后的数据X_fsvar # 这里K=3是根据X_fvar得来的
X_fschiall.shape
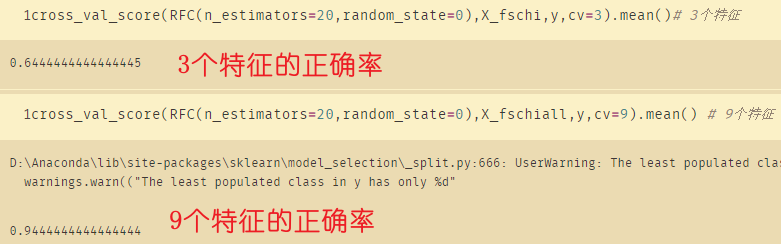
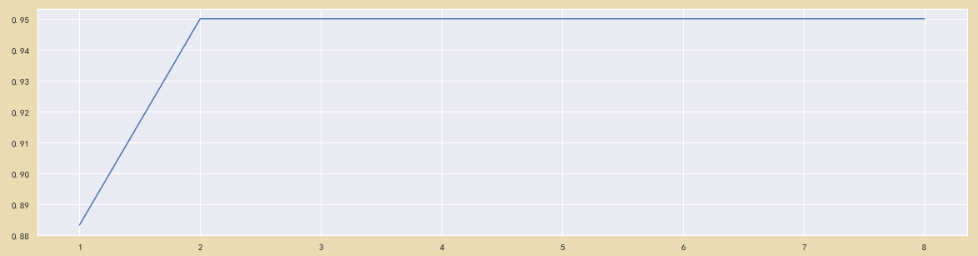
#通过学习曲线获取超参数 3个特征
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(3,0,-1):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar, y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=3).mean()
score.append(once)
plt.plot(range(3,0,-1),score)
plt.show()
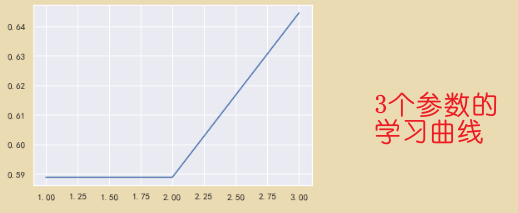
#通过学习曲线获取超参数 全部特征
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(9,0,-1):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X, y)
once = cross_val_score(RFC(n_estimators=100,random_state=0),X_fschiall,y,cv=8).mean()
score.append(once)
plt.plot(range(9,0,-1),score)
plt.show()
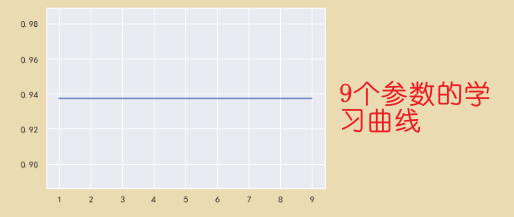
# 通过学习曲线获取超参数 全部特征,但是用的是X_fschi
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(9,0,-1):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X, y)
once = cross_val_score(RFC(n_estimators=100,random_state=0),X_fschi,y,cv=9).mean()
score.append(once)
plt.plot(range(9,0,-1),score)
plt.show()
# X_fschi:
'''
array([[0. ],
[0. ],
[0. ],
[0. ],
[0. ],
[0.46153846],
[0.46153846],
[0.46153846],
[0.46153846],
[0.46153846],
[1. ],
[1. ],
[1. ],
[1. ],
[1. ],
[1. ]])'''
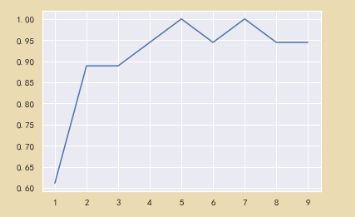
可以看到K取5或者7的时候正确率可以达到100%
三、卡方检验
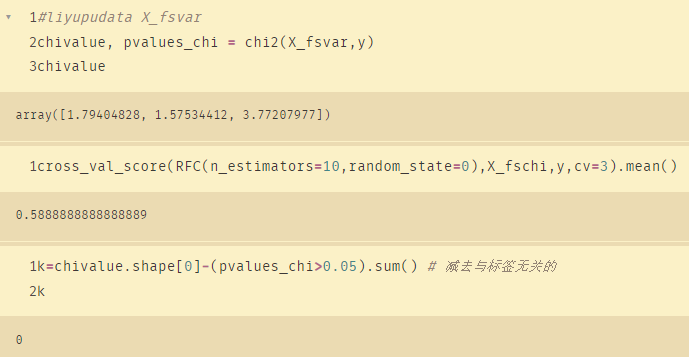
取三个特征的结果:
chivalue, pvalues_chi = chi2(X_fsvar,y)
chivalue
cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=3).mean()
k=chivalue.shape[0]-(pvalues_chi>0.05).sum() # 减去与标签无关的
k
取全部特征的结果:
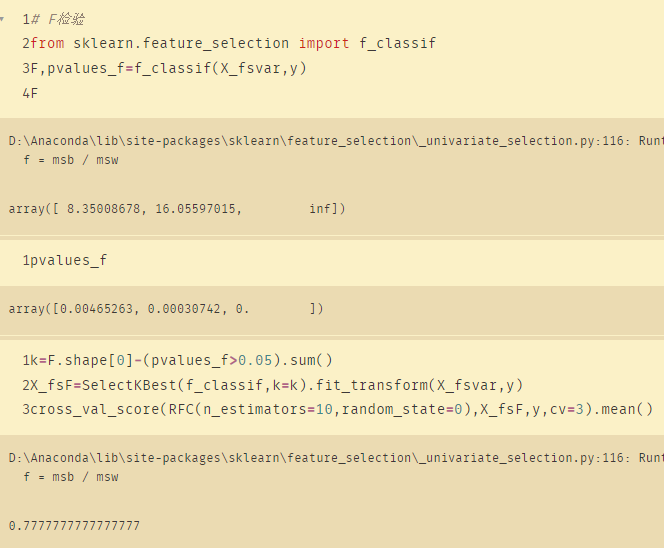
四、F检验
# F检验
from sklearn.feature_selection import f_classif
F,pvalues_f=f_classif(X_fsvar,y)
F
k=F.shape[0]-(pvalues_f>0.05).sum()
X_fsF=SelectKBest(f_classif,k=k).fit_transform(X_fsvar,y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsF,y,cv=3).mean()
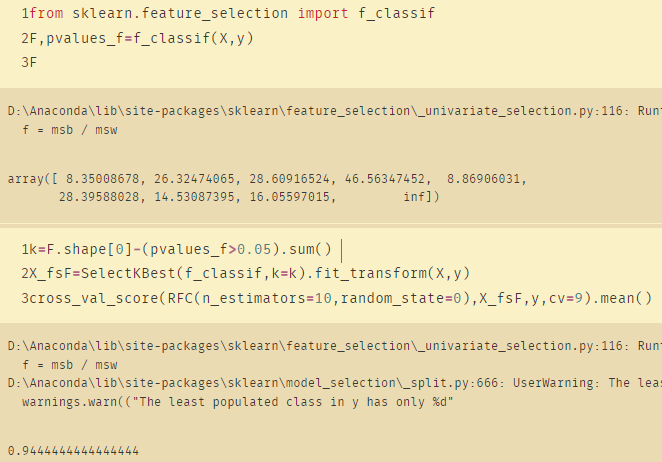
from sklearn.feature_selection import f_classif
F,pvalues_f=f_classif(X,y)
F
k=F.shape[0]-(pvalues_f>0.05).sum()
X_fsF=SelectKBest(f_classif,k=k).fit_transform(X,y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsF,y,cv=9).mean()
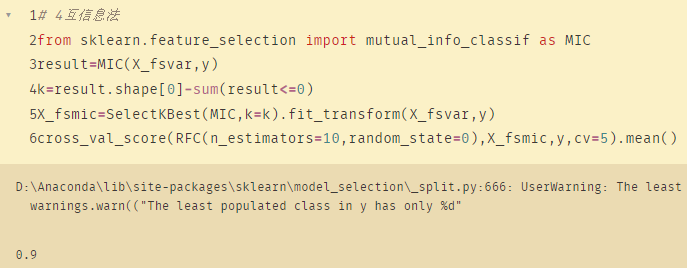
五、互信息法
# 4互信息法
from sklearn.feature_selection import mutual_info_classif as MIC
result=MIC(X_fsvar,y)
k=result.shape[0]-sum(result<=0)
X_fsmic=SelectKBest(MIC,k=k).fit_transform(X_fsvar,y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()
六、嵌入法
# 6 嵌入法
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_=RFC(n_estimators=10,random_state=0)
X_embedded=SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y)
X_embedded.shape # 结果:可以减去两个特征,剩下7个
#通过学习曲线获取阈值
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
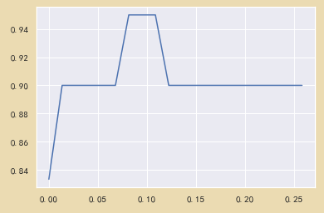
X_embedded=SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y)
X_embedded.shape
cross_val_score(RFC_,X_embedded,y,cv=5).mean()
将正确率高的学习曲线进行放大
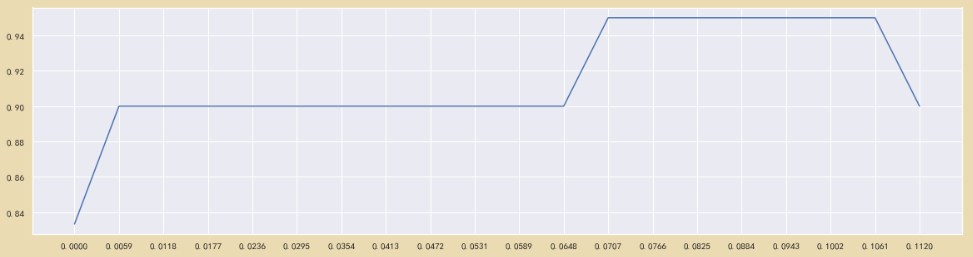
# 通过学习曲线选取
#liyupudata
score2 = []
for i in np.linspace(0,0.112,20):
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score2.append(once)
plt.figure(figsize=[20,5])
plt.plot(np.linspace(0,0.112,20),score2)
plt.xticks(np.linspace(0,0.112,20))
plt.show()
七、包装法
#liyupudata
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =100,random_state=0)
selector = RFE(RFC_, n_features_to_select=9, step=50).fit(X, y)
selector.support_.sum()
selector.ranking_
X_wrapper = selector.transform(X)
cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
# 通过学习曲线选取
#liyupudata
score = []
for i in range(1,9,1):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,9,1),score)
plt.xticks(range(1,9,1))
plt.show()