无监督的cluster_acc计算
首先实现是分为两种形式,一种sklearn低版本的,一种是sklearn高版本的
实现1
from sklearn.utils.linear_assignment_ import linear_assignment
import sklearn
print(sklearn.__version__)
import numpy as np
def acc(ypred, y):
"""
Calculating the clustering accuracy. The predicted result must have the same number of clusters as the ground truth.
ypred: 1-D numpy vector, predicted labels
y: 1-D numpy vector, ground truth
The problem of finding the best permutation to calculate the clustering accuracy is a linear assignment problem.
This function construct a N-by-N cost matrix, then pass it to scipy.optimize.linear_sum_assignment to solve the assignment problem.
"""
assert len(y) > 0
assert len(np.unique(ypred)) == len(np.unique(y))
s = np.unique(ypred)
t = np.unique(y)
N = len(np.unique(ypred))
C = np.zeros((N, N), dtype = np.int32)
for i in range(N):
for j in range(N):
idx = np.logical_and(ypred == s[i], y == t[j])
C[i][j] = np.count_nonzero(idx)
# convert the C matrix to the 'true' cost
Cmax = np.amax(C)
C = Cmax - C
#
indices = linear_assignment(C)
row = indices[:][:, 0]
col = indices[:][:, 1]
# calculating the accuracy according to the optimal assignment
count = 0
for i in range(N):
idx = np.logical_and(ypred == s[row[i]], y == t[col[i]] )
count += np.count_nonzero(idx)
return 1.0*count/len(y)
if __name__ == '__main__':
"""
Using accuracy to evaluate clustering is usually not a good idea, the following example shows that
even a completely wrong assignment yield accuracy of 0.5.
Consider use more standard metrics, such as NMI or ARI.
"""
s = np.array([1, 2, 2 ,3, 1, 3,2,2,1,2,1,1,1])
t = np.array([1, 1, 2, 2, 3, 3,1,1,2,2,2,2,2])
ac = acc(s, t)
print(ac)
结果如下

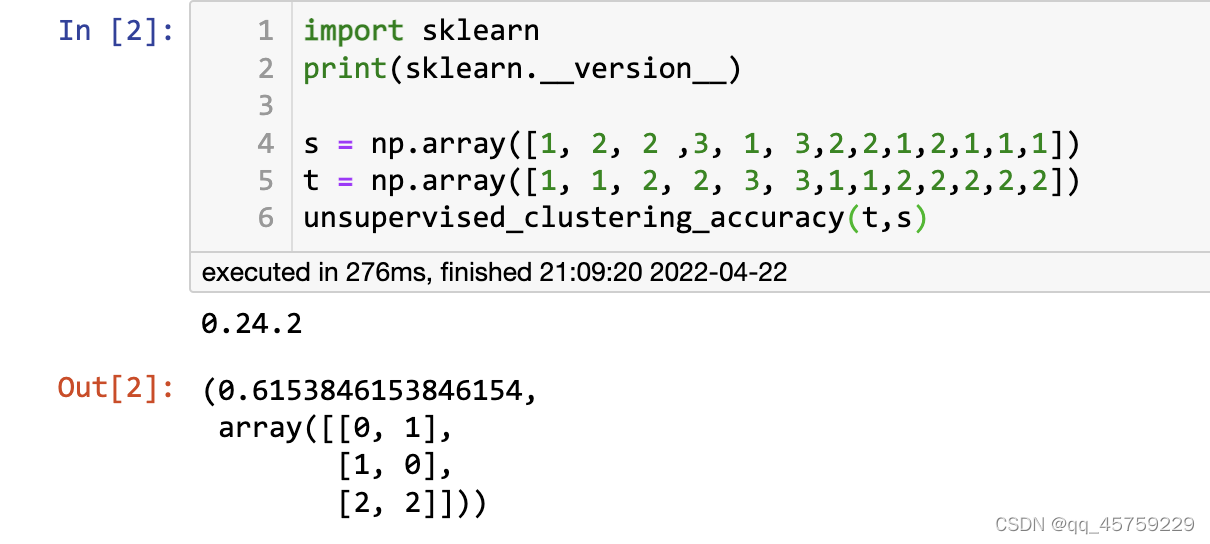
实现2
from typing import List, Optional, Union
import numpy as np
import torch
from scipy.optimize import linear_sum_assignment
def unsupervised_clustering_accuracy(
y: Union[np.ndarray, torch.Tensor], y_pred: Union[np.ndarray, torch.Tensor]
) -> tuple:
"""Unsupervised Clustering Accuracy
"""
assert len(y_pred) == len(y)
u = np.unique(np.concatenate((y, y_pred)))
n_clusters = len(u)
mapping = dict(zip(u, range(n_clusters)))
reward_matrix = np.zeros((n_clusters, n_clusters), dtype=np.int64)
for y_pred_, y_ in zip(y_pred, y):
if y_ in mapping:
reward_matrix[mapping[y_pred_], mapping[y_]] += 1
cost_matrix = reward_matrix.max() - reward_matrix
row_assign, col_assign = linear_sum_assignment(cost_matrix)
# Construct optimal assignments matrix
row_assign = row_assign.reshape((-1, 1)) # (n,) to (n, 1) reshape
col_assign = col_assign.reshape((-1, 1)) # (n,) to (n, 1) reshape
assignments = np.concatenate((row_assign, col_assign), axis=1)
optimal_reward = reward_matrix[row_assign, col_assign].sum() * 1.0
return optimal_reward / y_pred.size, assignments
结果如下