СДНг
ВЙГф
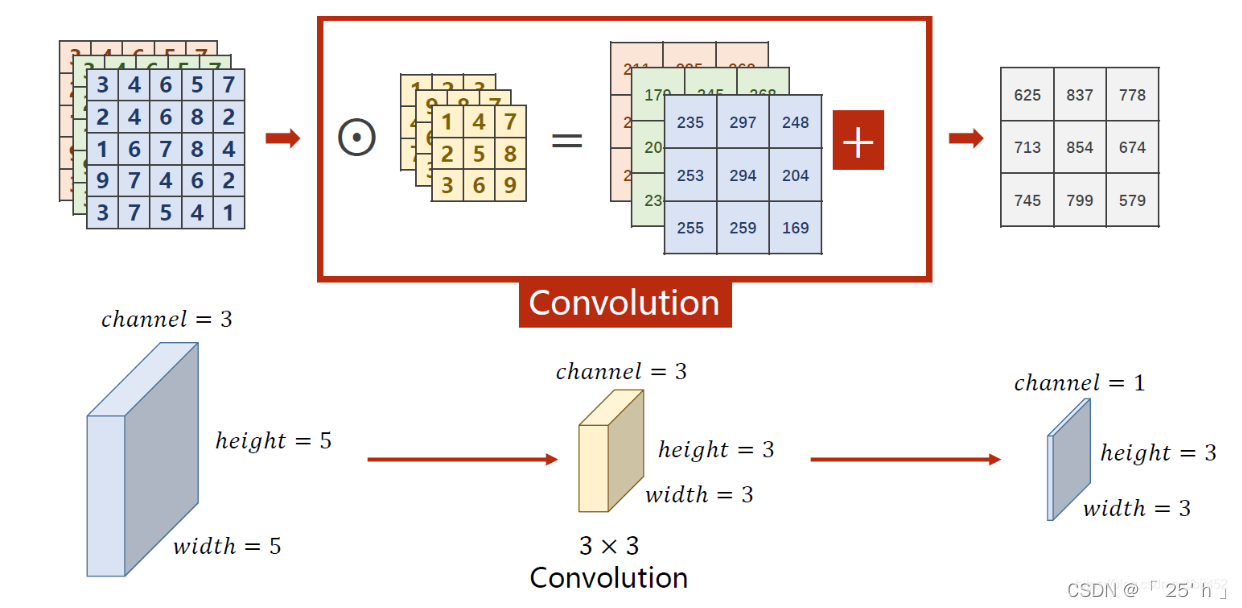
ОэЛ§conv2d

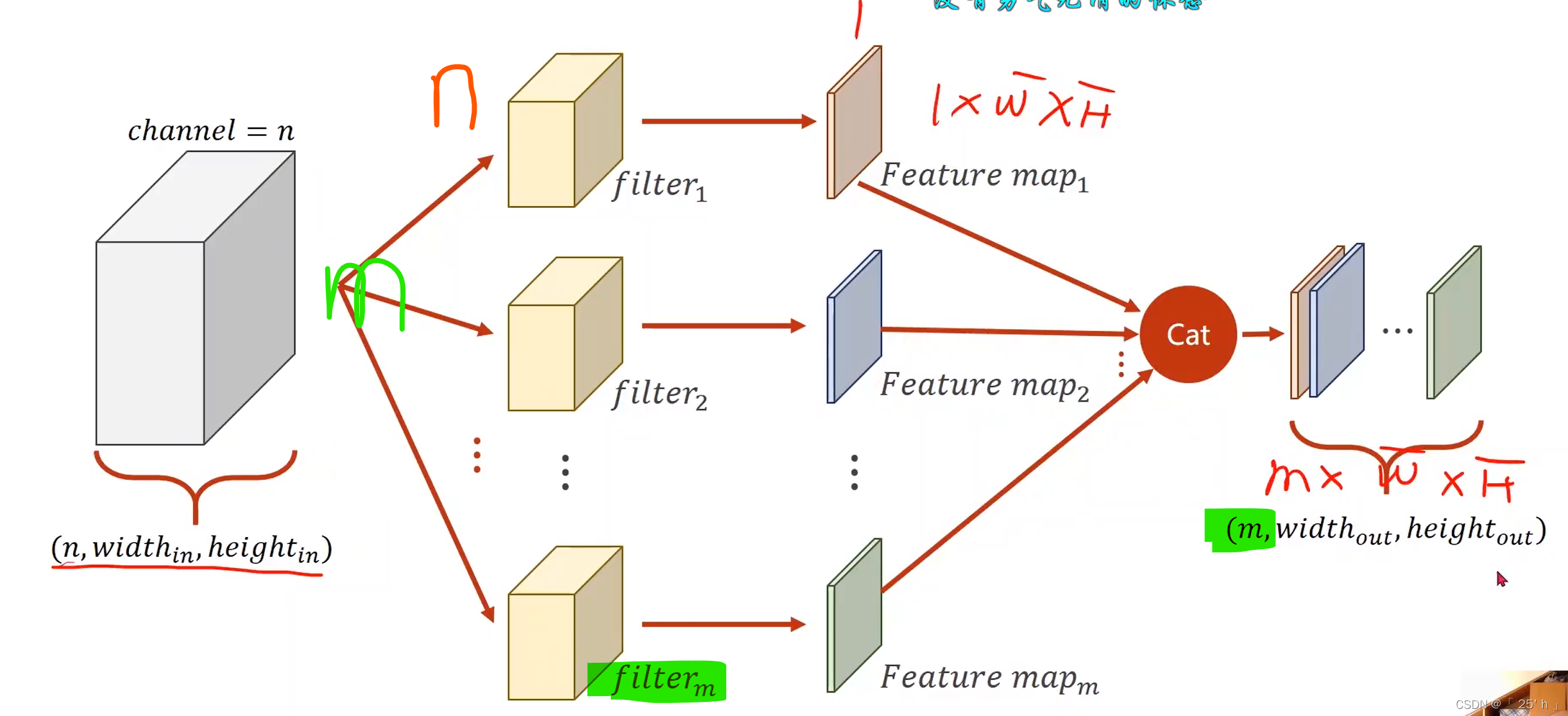
- convolutionжаЕФОэЛ§КЫЪ§СПNКЭЪфШыChannelsЯрЭЌ,УПNИіОэЛ§КЫМЦЫузщГЩвЛИіЪфГіЪ§Онoutput,УПNИіОэЛ§КЫзїЮЊвЛИіfilters,MИіfiltersзщГЩMЮЌoutputs
-
вЛЙВашвЊ M ( Ъф Гі C h a n n e l s ) ? N ( Ъф Шы C h a n n e l s ) M(ЪфГіChannels)*N(ЪфШыChannels) M(ЪфГіChannels)?N(ЪфШыChannels)ИіОэЛ§КЫ

-
вЛДЮОэЛ§КѓЪфГіЕФУПИіChannelsЕФЪ§ОнДѓаЁЛсБфГЩ ( i n p u t s w i d t h ? k e r n e l s i z e + 1 ) ? ( i n p u t s h e i g h t ? k e r n e l s i z e + 1 ) (inputs_{width}-kernel_{size}+1)*(inputs_{height}-kernel_{size}+1) (inputswidth??kernelsize?+1)?(inputsheight??kernelsize?+1)
-
ПЩвдгУpaddingВЮЪ§ЪЙУПИіChannelsЪ§ОнДѓаЁБЃГжВЛБф,padding = 1 БэЪОдіМгвЛШІ,ОЭЪЧБпдЕЕФСНааСНСаЁЃ
-
ОэЛ§(convolution)Кѓ,C(Channels)ПЩБфПЩВЛБф(вЛАуЖМБф),W(width)КЭH(Height)ПЩБфПЩВЛБф,ШЁОігкЪЧЗёpaddingКЭkernelЕФДѓаЁЁЃ
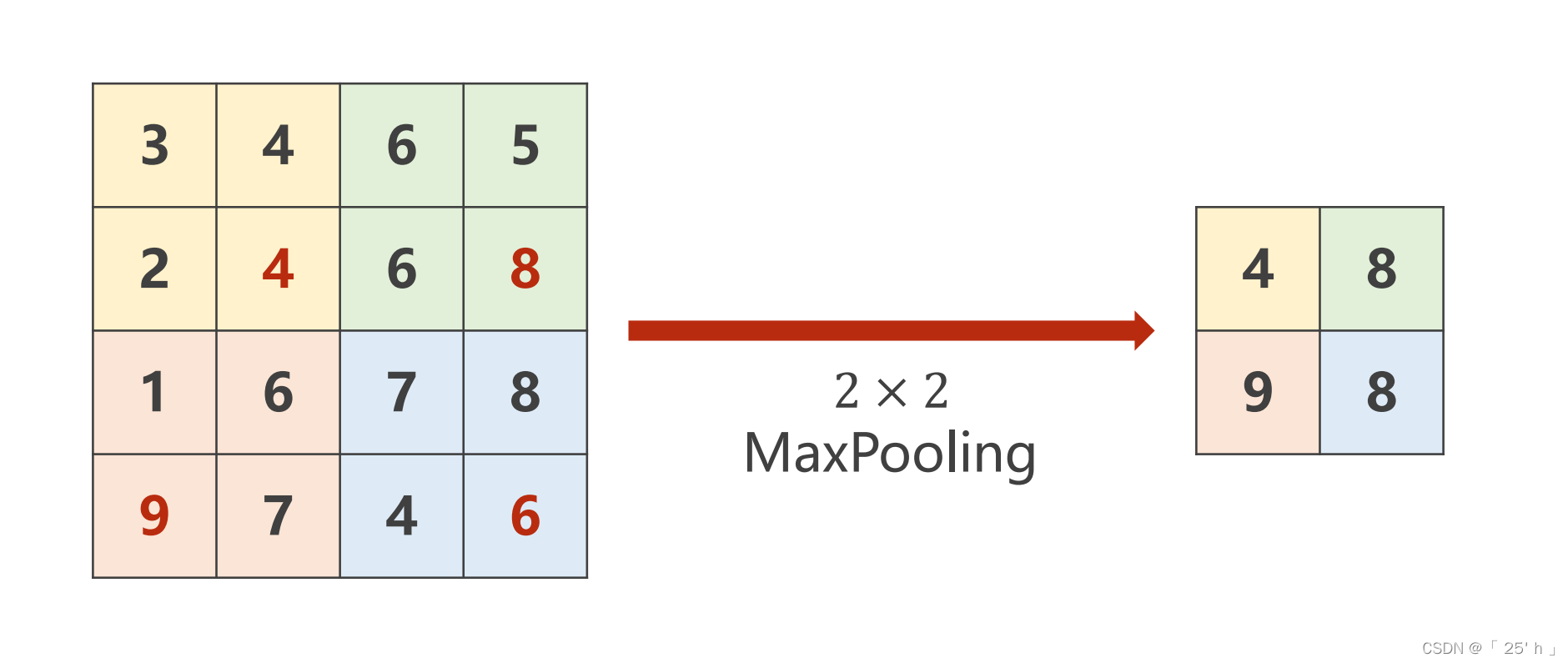
ГиЛЏMaxPool2d
torch.nn.MaxPool2d(2)
- subsampling(Лђpooling)Кѓ,ChannelsВЛБф,WКЭHБф
ећЬхСїГЬ
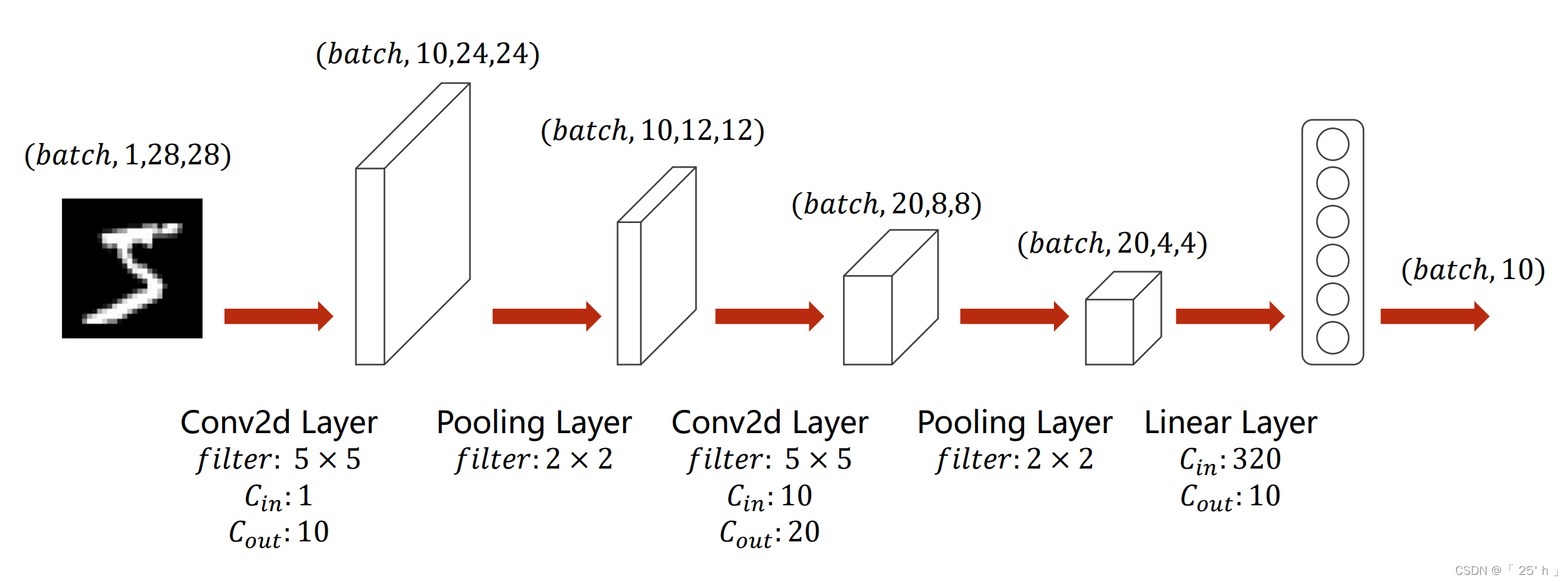
ДњТыЪЕЯж
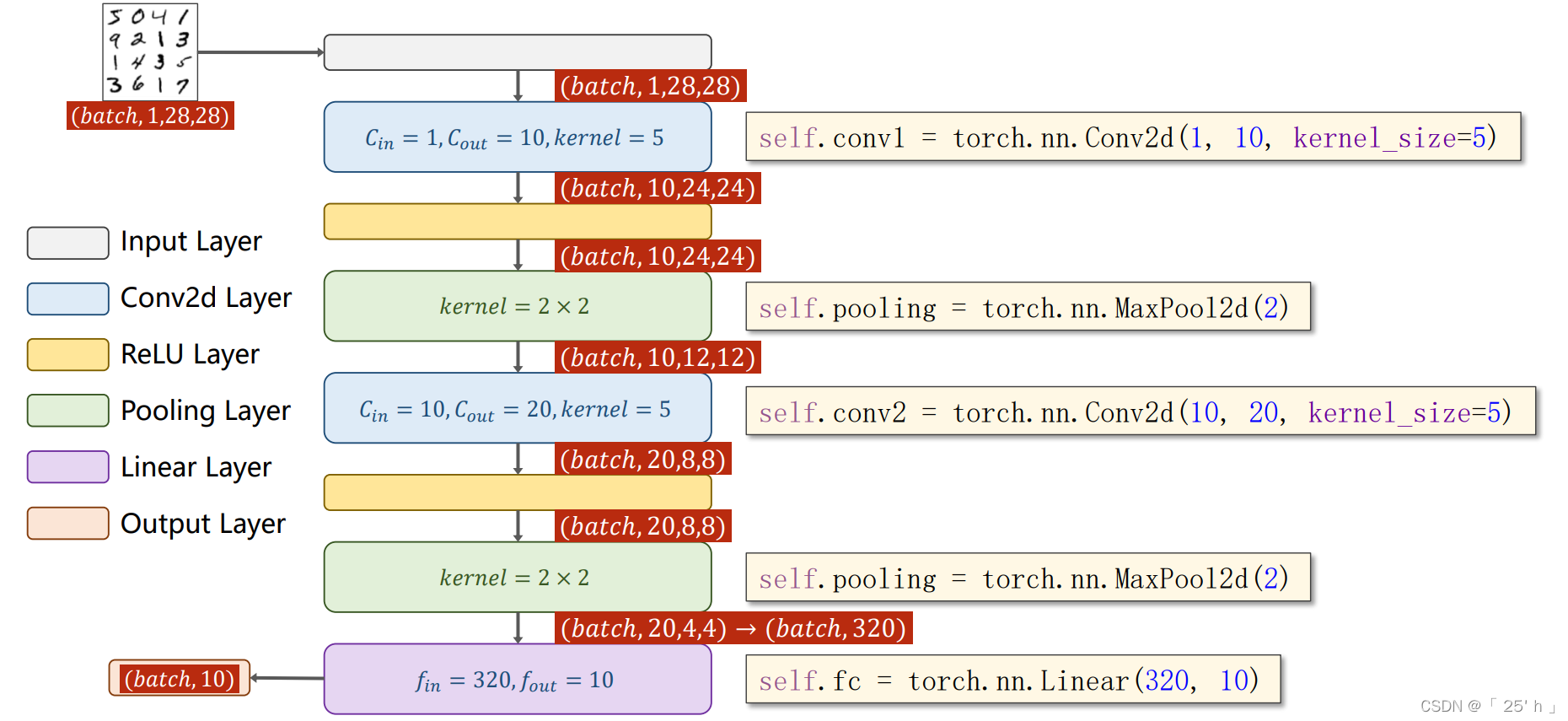

ДњТы
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# РЯбљзгзМБИЪ§Он
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root=r'D:\code_management\pythonProject\dataset/mnist/', train=True, download=False,
transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root=r'D:\code_management\pythonProject\dataset/dataset/mnist/', train=False,
download=False, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# ЩшМЦЩёОЭјТч
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2) # жЛЪЧгУГиЛЏstrideЮЊ2ЕФГиЛЏВу
self.fc = torch.nn.Linear(320, 10)
# ЮЊ320ЕФМЦЫуЙ§ГЬ(ИљОнforwardжаЕФжЕНјаа)
# ЖдгкЕЅИіЭМЯё
# 1*28*28 ---> 10*24*24 ---> 10*12*12 ---> 20*8*8 ---> 20*4*4 = 320
# ШЋСЌНг : 320 ---> 10
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
# ЪжаДЪ§ОнМЏжЛгавЛИіchannels,nЮЊ batch_size
batch_size = x.size(0) # ШЁГіbatch_size
x = F.relu(self.pooling(self.conv1(x))) # ЯШОэЛ§КѓГиЛЏ
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # ЮЊНјааШЋСЌНгзізМБИ,ЯШДгШ§ЮЌеЙГЩЖўЮЌОиеѓ, -1 ДЫДІздЖЏЫуГіЕФЪЧ320
x = self.fc(x) # ШЋСЌНгЕН10ЮЌЖШ,вЛЙВ10жж
return x
model = Net()
# ЪЙгУGPUЛЙЪЧCPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Ы№ЪЇгыгХЛЏЗНЗЈ
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# бЕСЗЗНЗЈ
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs) # бЕСЗ
loss = criterion(outputs, target) # ЫуЫ№ЪЇ
optimizer.zero_grad() # ЬнЖШЧхСу
loss.backward() # ЗДЯђДЋВЅ
optimizer.step() # ИќаТгХЛЏ
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
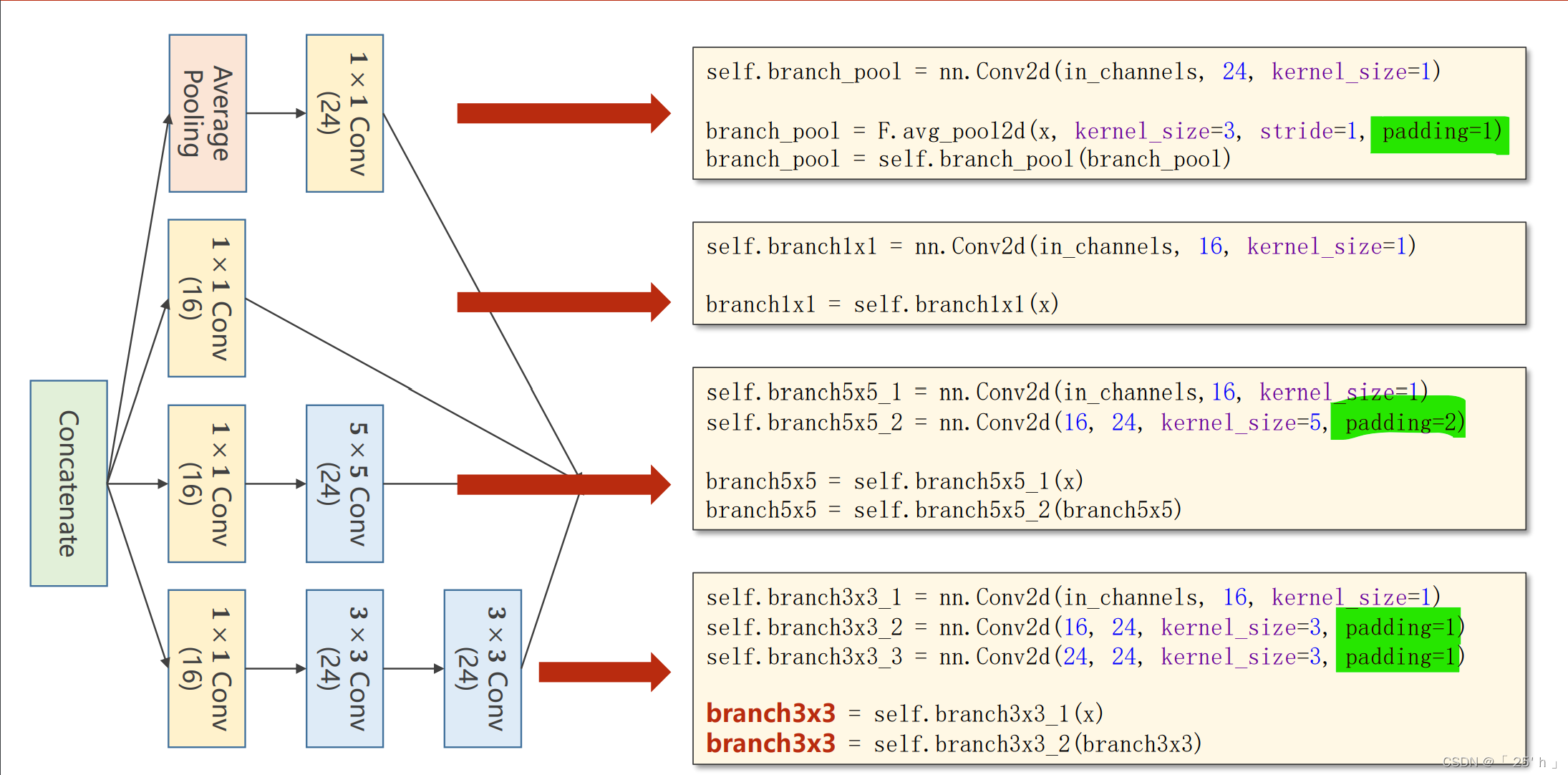
GoogleNet
ОэЛ§КЫДѓаЁЮЊ1ЕФВйзїФмЭЈЙ§МѕаЁЮЌЖШНЯЩйМЦЫуСП,ЕЋЪЧгааХЯЂЫ№ЪЇЁЃ
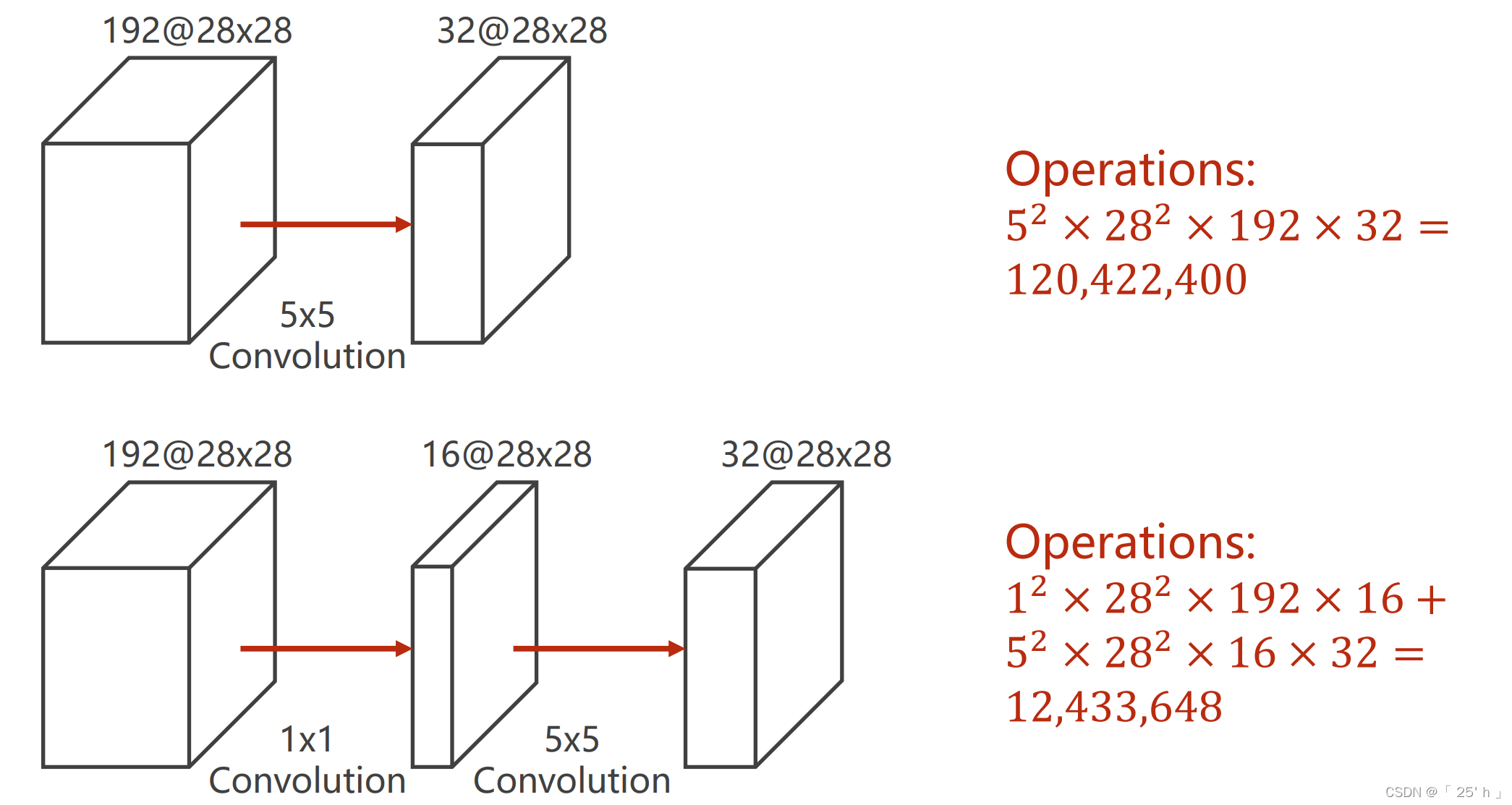
- 16,24БэЪОChannels,зЂвтвЊБЃГжЪфГіДѓаЁwidth,heightБЃГжВЛБф,ЭЈЙ§paddingКЭkernelsizeДѓаЁРДБЃГжЁЃ