文章目录
论文: 《SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks》
github: https://github.com/shunsukesaito/SCANimate
创新点
SCANimate是一个端到端的可训练框架,它对穿着衣服的人进行原始 3D 扫描并将它们变成可动画的化身。
现有方法依赖于模板mesh配准和基于物理的模拟,这限制了服装化身建模的可扩展性(例如,服装类型、真实变形)。
作者贡献如下:
1、第一个端到端的可训练框架,用于从原始扫描构建高质量的参数服装人体模型,无需服装特定模板或mesh配准;
2、一种新的具有几何循环一致性的弱监督公式,它可以在不需要真值训练数据的情况下将关节变形与局部姿态校正解耦;
3、一种局部姿势敏感的隐式表面表示,它建模姿势相关的服装变形并泛化到未见过的姿势;
算法
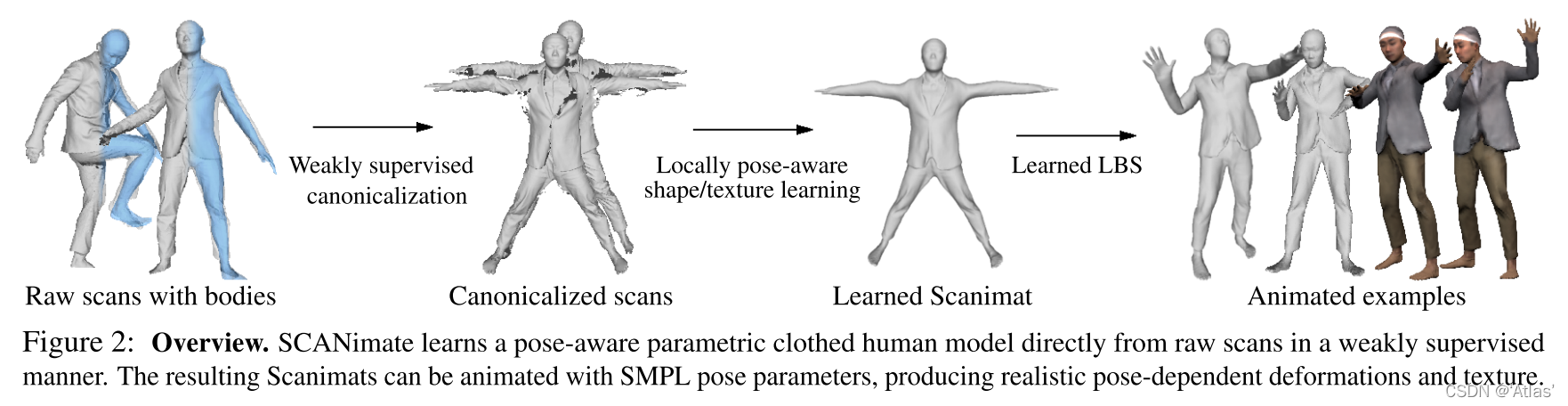
SCANimate流程如图2,输入为穿衣人体的3D sacn及拟合的未穿衣的身体模型;流程如下:
1、给定输入,通过预测蒙皮权重
w
w
w实现姿态空间与标准空间之间双向变换,其为基于空间坐标的函数;为解决缺少对应真值数据问题,使用循环一致性损失。
2、我们进一步学习关注局部姿态的符号距离函数,其由神经网络参数化,使用隐式几何正则化从规范化scan中进一步学习。
Canonicalization(规范化)
作者训练了一个模型,该模型将空间中的任何点作为输入并输出其蒙皮权重向量
w
∈
R
J
,
J
w\in R^J,J
w∈RJ,J为关键点数量,如图3所示;
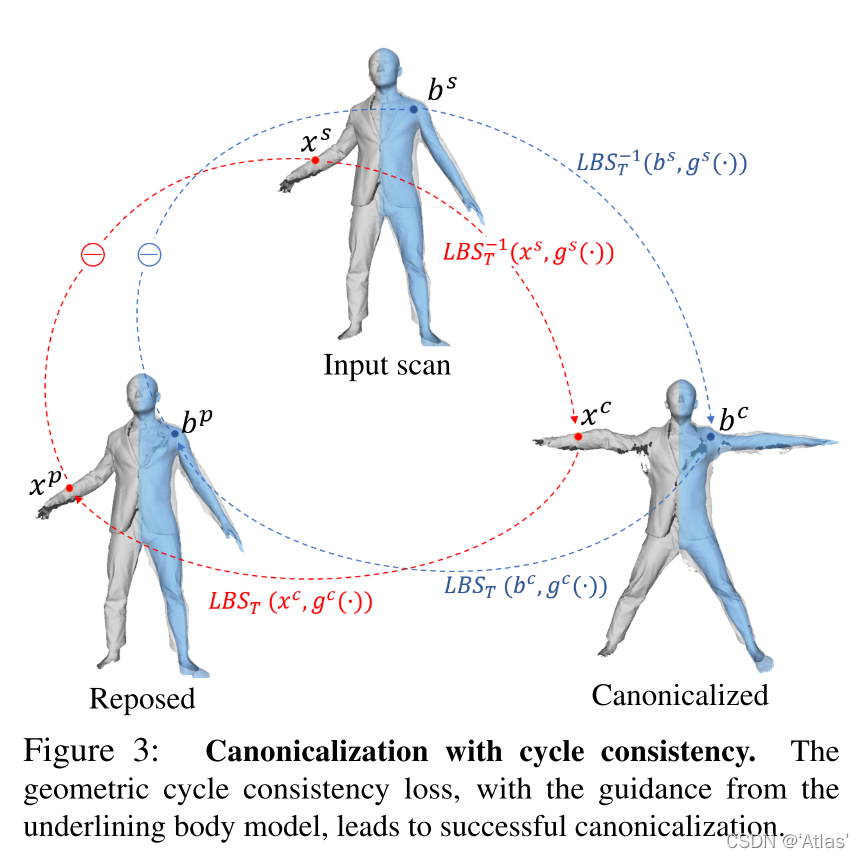
X
X
X为衣服表面,
B
B
B为身体表面,
X
i
s
=
{
x
s
∈
R
3
}
X^s_i=\{x^s\in R^3 \}
Xis?={xs∈R3}为姿态空间原始scan的顶点,
X
i
c
=
{
x
c
∈
R
3
}
X^c_i=\{x^c\in R^3 \}
Xic?={xc∈R3}为标准空间无姿势scan的顶点,
X
i
p
=
{
x
p
∈
R
3
}
X^p_i=\{x^p\in R^3 \}
Xip?={xp∈R3}为重新姿势化scan的顶点,理论上与
X
i
s
X^s_i
Xis?一致。
虽然映射函数可以任意定义,但我们观察到这可以表示为身体关节的已知刚性变换
T
i
=
{
T
j
i
∈
S
E
(
3
)
,
j
=
1...
J
}
T^i=\{T^i_j\in SE(3),j=1...J \}
Ti={Tji?∈SE(3),j=1...J}的组合,这些刚性变换来自拟合的 SMPL 模型。具体来说,给出蒙皮权重
w
w
w,定义线性混合蒙皮
L
B
S
LBS
LBS及其逆变换
L
B
S
?
1
LBS^{-1}
LBS?1,如式1,实现姿态空间与标注空间之间变换,

使用前向及反向MLP神经网络
g
Θ
1
c
g^c_{\Theta_1}
gΘ1?c?及
g
Θ
2
s
g^s_{\Theta_2}
gΘ2?s?,预测蒙皮权重
w
w
w,如式2,

其中
Θ
1
,
Θ
2
\Theta_1,\Theta_2
Θ1?,Θ2?为可学习参数,
z
i
s
z^s_i
zis?为自编码隐向量。
结合式1与式2完成姿态空间转换,如式3,

学习蒙皮权重
作者发现:
1、靠近人体模型的区域与其最近的身体部位高度相关;
2、姿态空间点进映射到标准空间后经过LBS可映射回同一点;
根据1,作者使用SMPL身体模型的LBS蒙皮权重在标准空间及姿势空间进行引导;具体来说,scan上的
g
s
g^s
gs和
g
c
g^c
gc由身体模型和其蒙皮权重引导;
根据2,作者引入弱监督学习,即循环一致性限制。
蒙皮权重优化函数如式4,

其中,
E
B
E_B
EB?如式5,确保
g
c
g^c
gc和
g
p
g^p
gp预测的SMPL蒙皮权重在身体表面,其中
w
′
w'
w′为SMPL的LBS权重
E
S
E_S
ES?表示在scan点预测权重与其对应最邻近的身体表面点对应LBS权重一致,如式6,

E
C
E_C
EC?为循环一致性损失,包括:
E
C
′
E_{C'}
EC′?约束姿态空间与标准空间蒙皮权重一致性;
E
C
′
′
E_{C''}
EC′′?表示原始姿态空间与标准空间迁移到姿态空间顶点一致性,如式7、8、9;
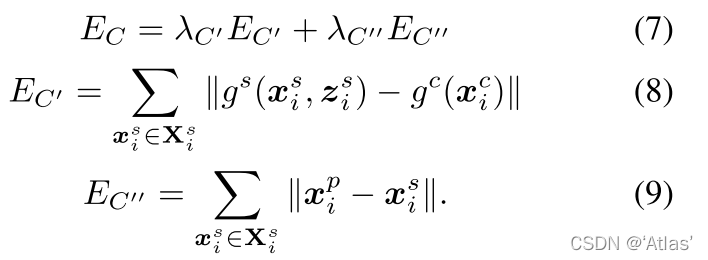
E
R
E_R
ER?为正则项,包括稀疏约束
E
S
p
E_{Sp}
ESp?、平滑约束
E
S
m
E_{Sm}
ESm?、隐编码约束
E
Z
E_Z
EZ?;
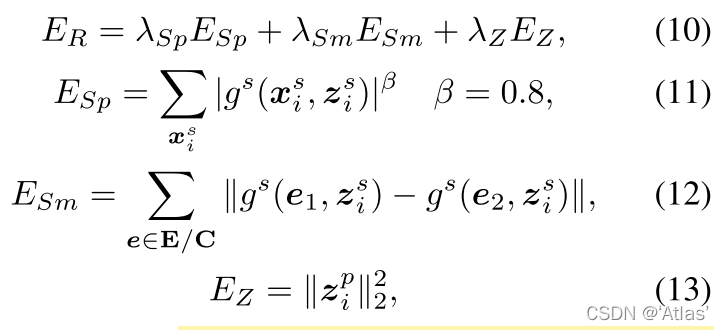
综上,我们将scan中所有顶点通过反向LBS变换,得到标准空间scan,用于学习关注姿态的穿衣人体模型;
Locally Pose-aware Implicit Shape Learning Given(局部姿态感知隐式形状学习)
给出标准空间scan及其可学习蒙皮权重,我们学习一个具有姿势感知变形的参数化穿衣人体模型。
问题:真实scan存在孔洞,导致这部分无法获取真实标签,为了支持部分scan作为输入,学习有符号距离(SDF)函数
f
Φ
(
x
)
f_{\Phi}(x)
fΦ?(x),其基于多层感知机,使用IGR优化以下目标函数,如式14-17,
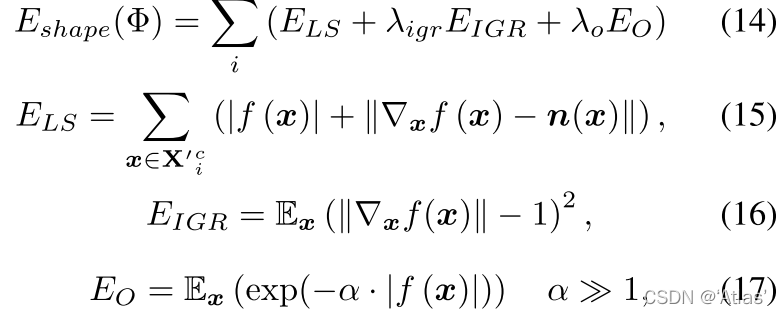
E
L
S
E_{LS}
ELS?确保预测的SDF趋近于0,并且其表面normal与其输入scan,
n
(
x
)
n(x)
n(x)对齐;
E
I
G
R
E_{IGR}
EIGR?为Eikonal正则项;
E
O
E_O
EO?正则化非表面点SDF值,使其不接近表面;
为了学习服装的姿势相关变形,我们可以使用姿势特征
θ
∈
R
J
×
4
\theta \in R^{J\times4}
θ∈RJ×4来调节函数
f
f
f;
训练集中有限的姿态变化及关节点之间虚假相关性,使得姿态特征与坐标直接concat会过拟合;因此需要一种注意力机制,将空间位置仅与相关姿态特征相关联,更改
f
f
f如式18,
W
W
W为映射权重,将蒙皮权重映射为姿态注意力权重,通过减少虚假相关性,减少过拟合,增加泛化性。

实验
评估方法
D
s
2
m
D_{s2m}
Ds2m?表示scan到mesh距离;
D
n
D_n
Dn?表示表面normal一致性;
P
i
P_i
Pi?表示基于图像的感知得分;
P
v
P_v
Pv?表示基于视频的感知得分;
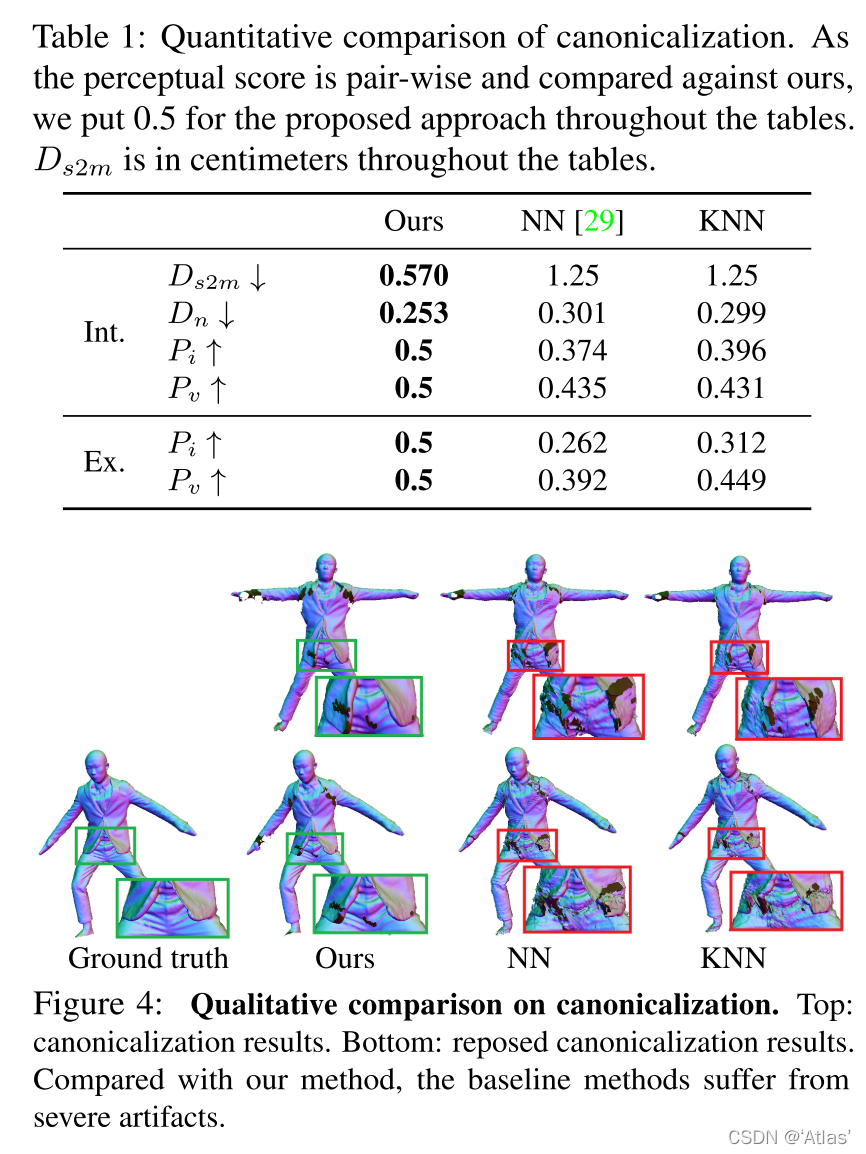
规范化
NN表示使用最邻近身体顶点蒙皮权重复制到穿衣蒙皮权重;
KNN表示选取身体表面最邻近的K的顶点蒙皮权重进行插值;
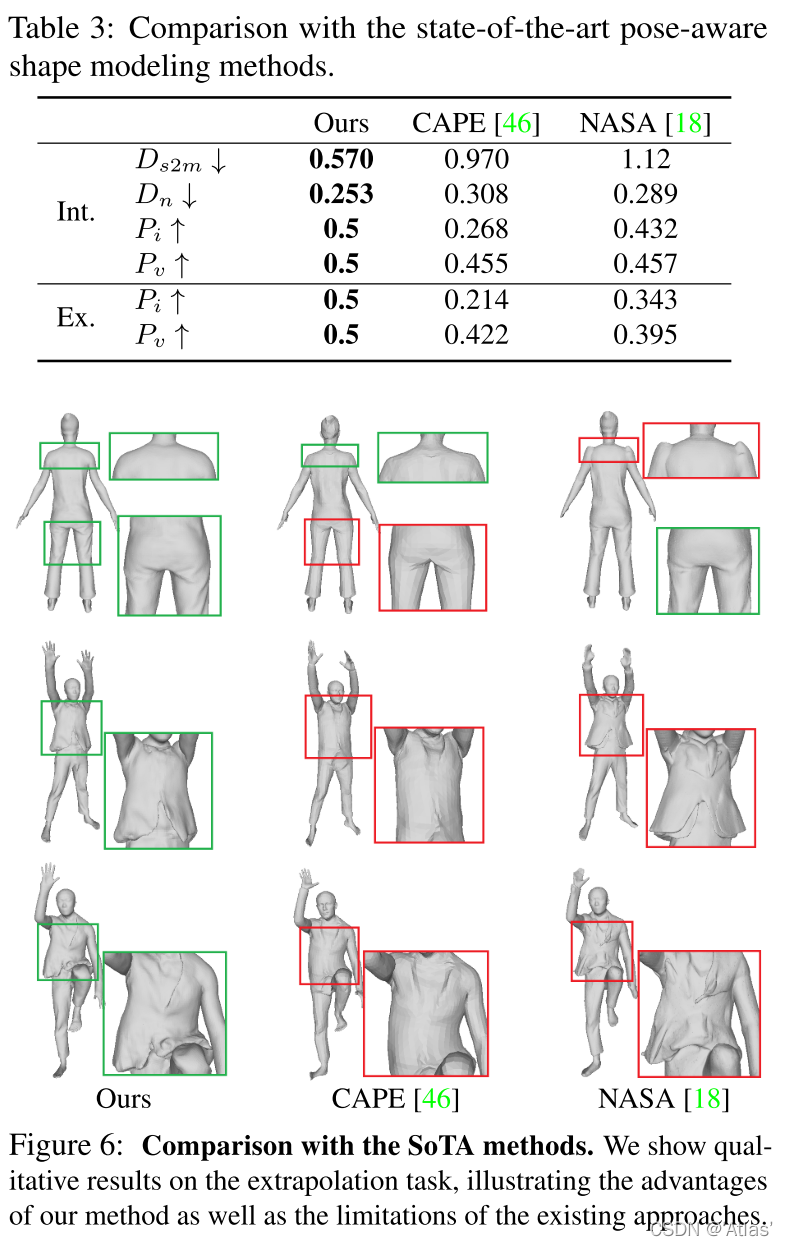
比较结果如表1,
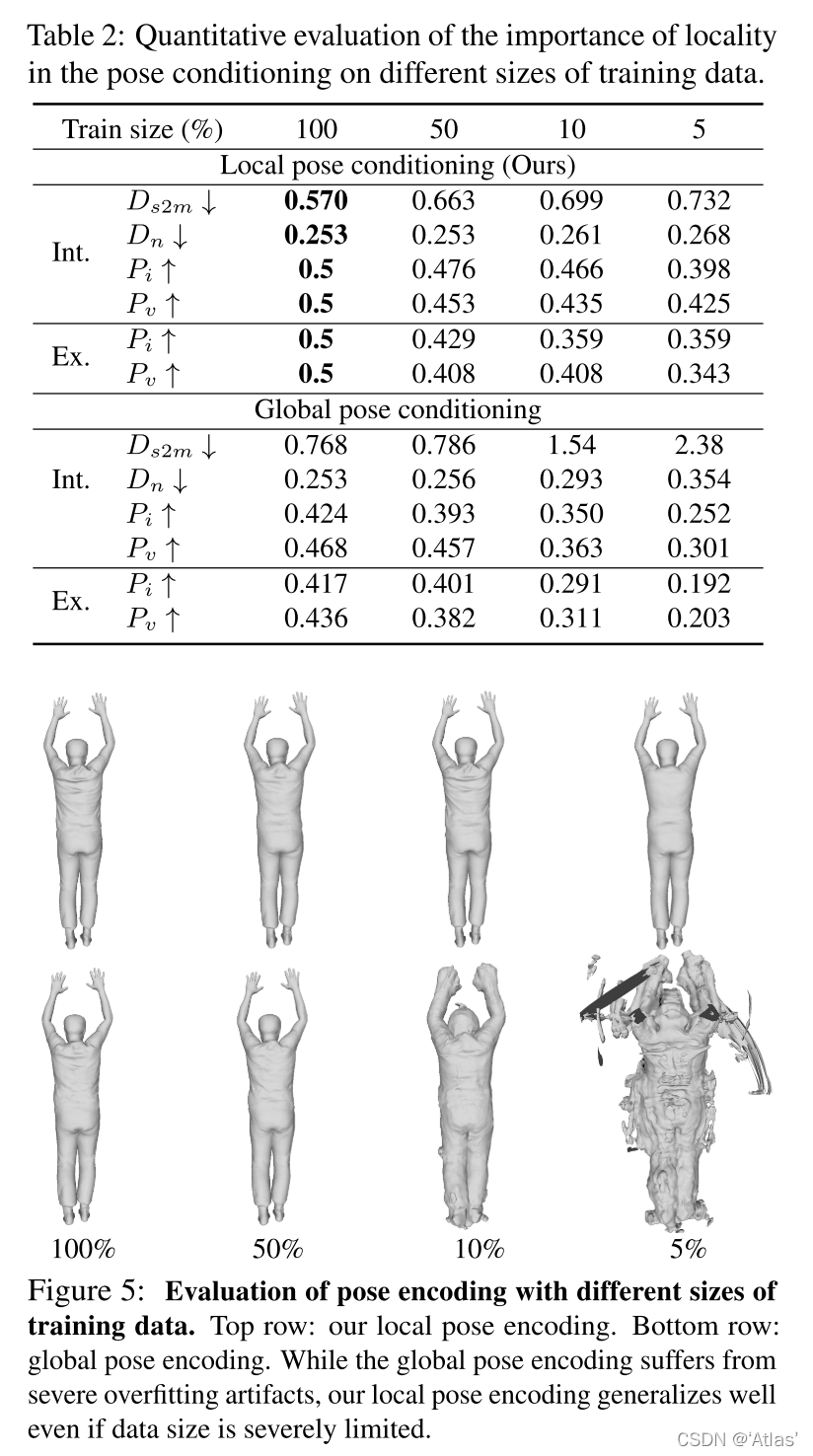
局部姿态与全局姿态比较
SOTA方法比较
结论
SCANimate是一个自动生成高质量虚拟化身(逼真的衣服变形)的框架,其由姿态参数驱动,直接从原始3D扫描中学习。
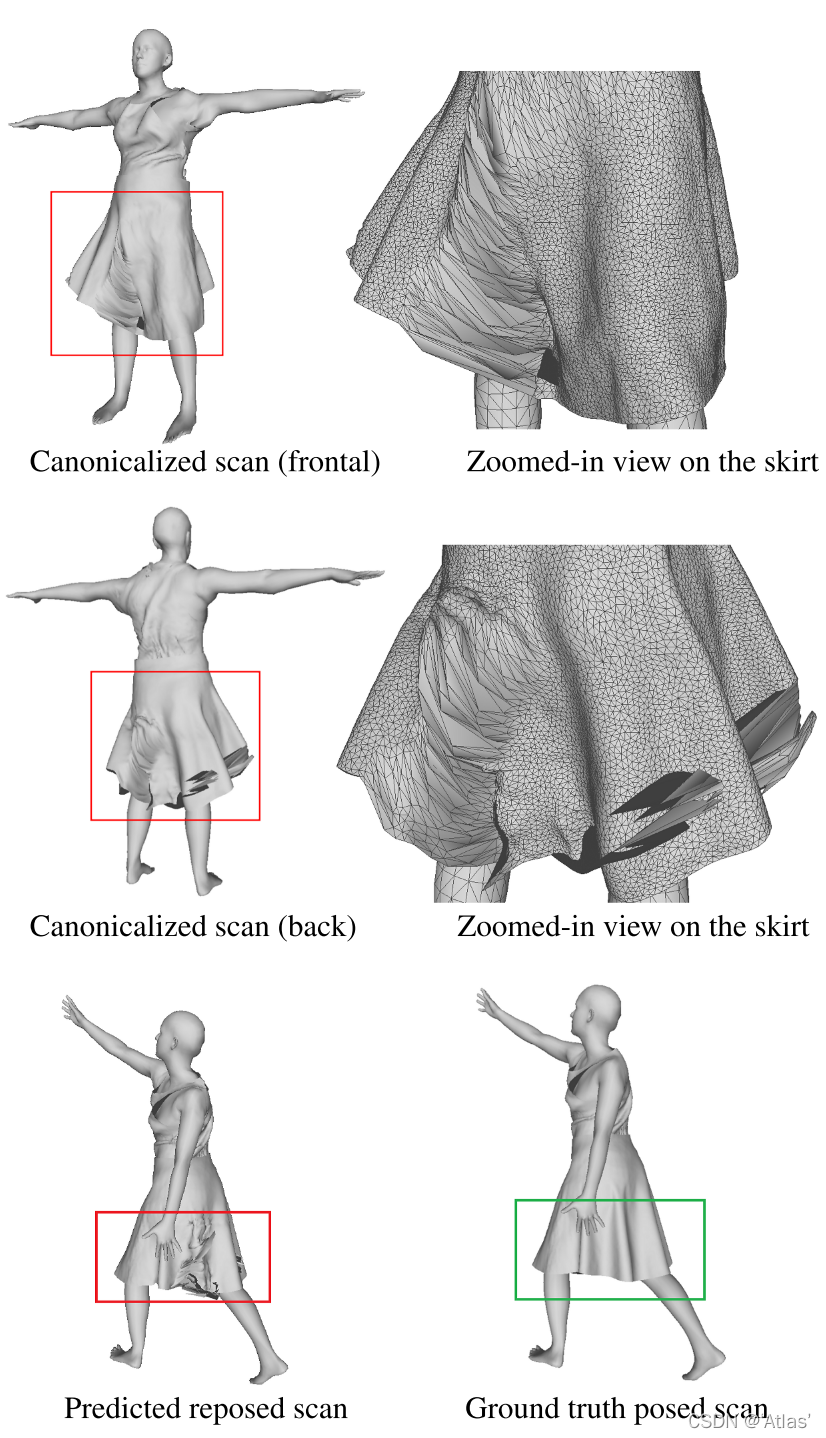
问题:
SCANimate在与身体紧贴的衣服上表现比较好,可能不适用于显着偏离身体的衣服,如图。未来应该讲反光率、形状、关照纳入表面纹理因素;