目录
贝叶斯算法概述
贝叶斯要解决的"逆概"问题
正向概率:
设袋子里有M个白球N个黑球,求摸出黑球的概率之类的概率叫正向概率。
逆向概率:(也就是贝叶斯解决的问题)
如果我们事先不知道袋子里黑球和白球的比例,然后闭着眼摸球出来,根据摸出的球的颜色,就此对袋子里黑白球的比例做出一定的推测。
为什么使用贝叶斯?
现实世界本身就是不确定的,并且人的观察能力是有局限性的。
我们日常生活中观察到的只是事物的表面,因此需要提供一些猜测。

?贝叶斯推导实例



化简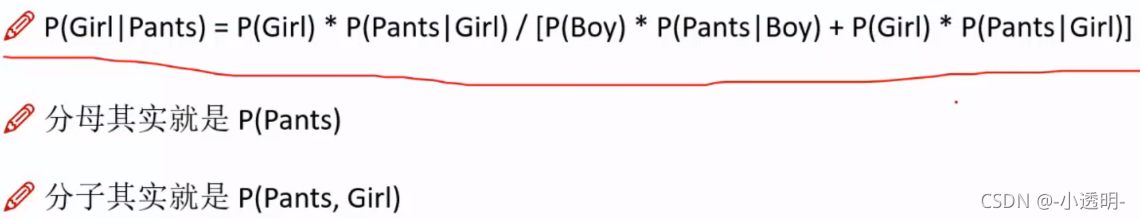
?贝叶斯公式
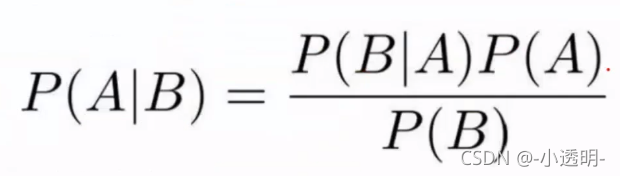
贝叶斯--"拼写纠正"实例


?先验概率
是指根据以往经验和分析得到的概率。与实际情况相挂钩。
对上面的例子来说,p(h)为先验概率(即每个词在字典中出现的概率<即词频>)
 ∝表示正比于
∝表示正比于
可能性大小由编辑距离:即两个单词不同的字母的数量等或者其他指标

?"垃圾邮件过滤"实例
模型比较理论
最大似然估计
最符合观测数据的(差一个的比差两个的更优)(即P(D|h)最大的)最有优势
奥卡姆剃刀
P(h)较大的模型有较大的优势


?奥卡姆剃刀:越高阶的多项式越不常见。(高阶容易有过拟合现象)
垃圾邮件过滤实例



?贝叶斯实现拼写检查器




# 把语料中的单词抽取出来,转成小写,并且去除单词中间的特殊符号
import re,collections
def words(text):
return re.findall('[a-z]+',text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)# 所有词统计过后最少出现1次
for f in features:
model[f] += 1
return model
NWORDS=train(words(open('E:/data/my_data/spelling_correct.txt').read()))
# print(NWORDS)
alphabet='abcdefghijklmnopqrstuvwxyz'
# 编辑距离
# 返回所有与word编辑距离为 1 的集合
def edits1(word):
n=len(word)
return set([word[0:i]+word[i+1:] for i in range(n)]+ #delete(删除次数)
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)]+ #transposition(交换次数)
[word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet]+ # alteration(替换次数)
[word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) #insertion(插入次数)
# 返回编辑距离为2 的单词
def edists2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1))
# 返回那些正确的词作为候选词
def known(words):
return set(w for w in words if w in NWORDS)
# 检查器:先判断是不是正确的拼写形式,如果不是则选出编辑距离为1的单词……
def correct(word):
# 如果known(set)非空,candidate就会选取这个集合,而不继续计算后面的
candidates=known([word])or known(edits1(word)) or known(edists2(word)) or [word]
# 返回概率最大的内个词
return max(candidates,key=lambda w:NWORDS[w])
# 效果展示
# mach-->much
print(correct('mach'))
# appl-->apply
print(correct('appl'))
# appla-->apply
print(correct('appla'))
# learw-->learn
print(correct('learw'))
# tess-->test(输出less:有点不准确,可能是因为语料中less出现的频率高一些)
print(correct('tess'))
# morw-->more
print(correct('morw'))much apply apply learn less more
文本分析与关键词提取
文本数据(字符串组成)
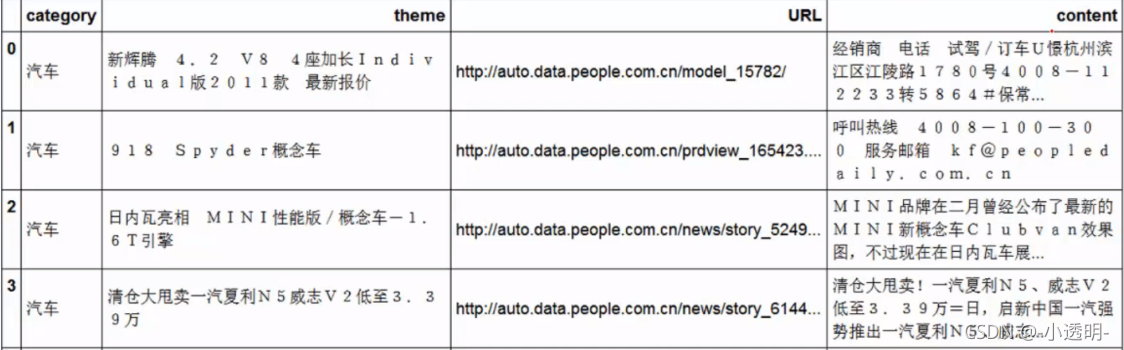
?停用词
语料中大量出现但没啥大用(对文本的内容主题没什么影响)的词(截取一部分如下图)

?Tf(词频)-idf(逆文档频率):关键词提取



?相似度计算

语料清洗(去停用词、筛选重复句子等)-->分词(jieba库)-->构造语料库-->词频向量(机器认识)
?余弦相似度(即两个向量夹角余弦值)
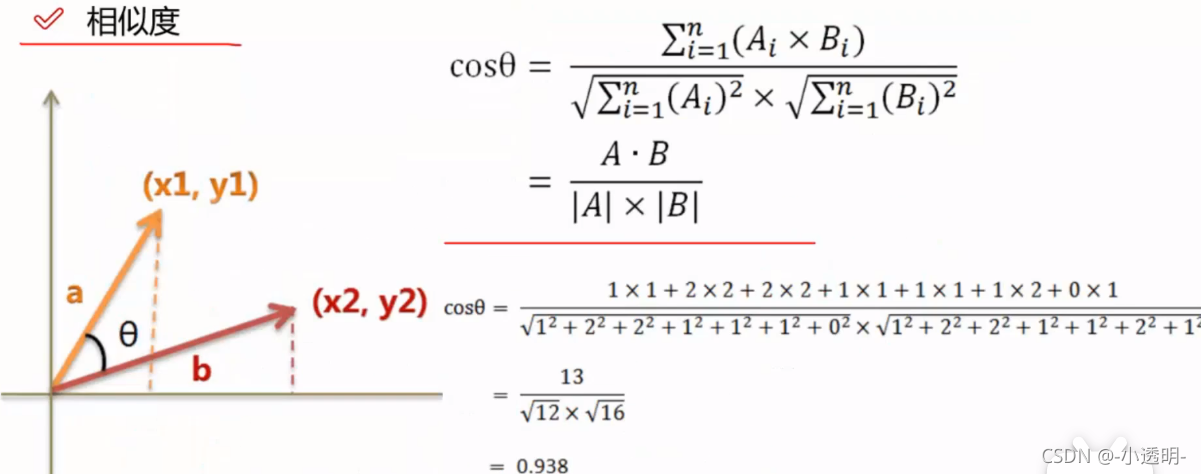
?案例:新闻数据分类
过程:
#数据源:搜狗实验室-->新闻数据
import pandas as pd
import jieba
df_news = pd.read_table('',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna() #去掉缺失值
df_news.head()
# notebook分段运行
df_news.shape
# notebook分段运行
#分词:使用jieba分词器
content = df_news.content.values.tolist()# 将内容转化为列表(jieba分词器要求)
print(content[1000])
content_s = []
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment)>1 and current_segment != '\r\n': #换行符
content_s.append(current_segment)
content_s[1000]
# notebook分段运行
df_content=pd.DataFrame({'conten_s':content_s})
df_content.head()
# notebook分段运行
# stopwords.txt:停用词表
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'],encoding='utf-8')
stopwords.head(20)
# notebook分段运行
# 去除停用词
def drop_stopwords(contents,stopwords):
contents_clean=[]
all_words=[]
for line in contents:
line_clean=[]
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))#为做词云准备
contents_clean.append(line_clean)
return contents_clean.all_words
# print(contents_clean)
content = df_content.content_s.value.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean.all_words=drop_stopwords(contents,stopwords)
# notebook分段运行
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head()
# notebook分段运行
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()
# notebook分段运行
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({'count':numpy.size})
words_count=words_count.reaet_index().sort_values(by=["count"],ascending=False)
words_count.head()
# notebook分段运行
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize']=(10.0,5.0)
wordcloud=WordCloud(font_path="",background_color="white",max_font_size=80)
word_frequence={x[0]:x[1] for x in words_count.head(100).values}
woldcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
# notebook分段运行
#TF-IDF关键词提取
import jieba.analyse
index=1000
print(df_news['content'][index])
content_s_str="".join(content_s[index])
print(" ".join(jieba.analyse.extract_tags(contents_s_str,topK=5,withWeight=False)))
# notebook分段运行
#LDA:主题模型
#格式要求:list of list 形式,分词好的整个语料
from gensim import corpora, models, similarities
import gensim
#做映射,相当于词袋
dictionary=corpora.Dictionary(contents_clean)
corpus=[dictionary.doc2bow(sentence) for sentence in contents_clean]
#类似Kmeans自己指定K值 num_topics=20:想得到20个主题,可自己指定
lda=gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
# notebook分段运行
#1号分类结果
print(lda.print_topic(1,topn=5))
# notebook分段运行
for topic in lda.print_topics(num_topics=20,num_words=5):
print(topic[1])
# notebook分段运行
# 贝叶斯分类器分类
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
df_train.head()
df_train.label..unique()# label不重复的值
# notebook分段运行
label_mapping={"汽车":1,"":2,"":3,"":4,"":5,"":6,"":7,"":8,"":9,"":10}
df_train['label']=df_train['label'].map(label_mapping)
df_train.head()
# notebook分段运行
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(df_train['contents_clean'].values,df_train['label'].value,random_state=1)
x_train[0][1]
# notebook分段运行
words=[]
for line_index in range(len(x_train)):
try:
words.append(' '.join(x_train[line_index]))
except:
print(line_index,word_index)
print(words[0])
print(len(words))
# notebook分段运行
from sklearn.feature_extraction.text import CountVectorizer
texts=['dog cat fish','dog cat cat','fish bird','bird']
cv=CountVectorizer() #向量构造器
cv_fit=cv.fit_transform(texts)
print(cv.get_features_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
# notebook分段运行
from sklearn.feature_extraction.text import CountVectorizer
texts=['dog cat fish','dog cat cat','fish bird','bird']
cv=CountVectorizer(ngram_range=(1,4)) #向量构造器(加上参数)
cv_fit=cv.fit_transform(texts)
print(cv.get_features_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
# notebook分段运行
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer(analyze='word',max_features=4000, lowercase=False)
vec.fit(words)
# notebook分段运行
from sklearn.naive_bayes import MultinomialNB
classifier=MultinomalNB() #贝叶斯分类器
classifier.fit(vec.transform(words),y_train)
# notebook分段运行
test_words=[]
for line_index in range(len(x_test)):
try:
test_words.append(' '.join(x_test[line_index]))
except:
print(line_index,word_index)
print(test_words[0])
# notebook分段运行
classifier.score(vec.transform(test_words),y_test) #基本贝叶斯精度
# notebook分段运行
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word',max_features=4000,lowercase=False)
vectorizer.fit(words)
from sklearn.naive_bayes import MultinomialNB
classifier=MultinomalNB() #贝叶斯分类器
classifier.fit(vec.transform(words),y_train)
# notebook分段运行
classifier.score(vec.transform(test_words),y_test) #构造向量方式不同,结果不同

