attention机制最早运用于自然语言处理(NLP);


SE-net模型是在通道上加入注意力机制:


第一个操作:Squeeze(Fsq),通过全局池化(global pooling),将每个通道的二维特征(H x W)压缩为1个实数,论文是通过平均值池化的方式实现。这属于空间维度的一种特征压缩,因为这个实数是根据二维特征所有值算出来的,所以在某种程度上具有全局的感受野,通道数保持不变,所以通过squeeze操作后变为1x1xC。
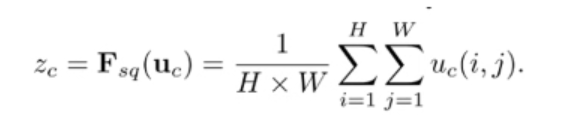
第二个操作:excitation(Fex),通过参数来为每个特征通道生成一个权重值,这个权重值是如何生成就很关键了,论文是通过两个全连接层组成一个Bottleneck结构去建模通道间的相关性,并输出和输入特征同样数目的权重值。
第三个操作:Scale(Fscale),将前面得到的归一化权重加权到每个通道的特征上。论文中的方法是用乘法,逐通道乘以权重系数,完成在通道维度上引入attention机制。
CNN中植入注意力模块SE-Net

ResNet中植入注意力模块SE-Net

上面两图说明了这个SE block是如何嵌入到主流网络(Inception和Resnet)中的,Global pooling就是squeeze操作,FC+ReLU+FC+Sigmoid就是excitation操作,具体过程是:①通过一个全连接层(FC)将特征维度降低到原来的1/r;②经过ReLU函数激活后再通过一个全连接层(FC)返回到原来的特征维度C,然后通过sigmoid函数转化为一个0~1的归一化权重。


(2)论文认为再excitation操作中用两个全连接层比直接用一个全连接层的好处在于:1)具有更多的非线性;2)可以更好地你和通道间地复杂度。
B站视频链接:https://www.bilibili.com/video/BV1SA41147uA/?spm_id_from=333.788.recommend_more_video.17

