����
Ӣ����Ŀ:Cross-lingual Knowledge Graph Alignment viaGraph Convolutional Networks
������Ŀ:����GCN�Ŀ�����֪ʶͼ����
���ĵ�ַ:https://aclanthology.org/D18-1032.pdf
����:֪ʶͼ��,֪ʶ����
����ʱ��:2018
����:Zhichun Wang ����ʦ����ѧ
����:EMNLP
������:198
���������:https://github.com/1049451037/GCN-Align
�Ķ�ʱ��:2022.04.15
��������
��������:
- ��ϰ��֮ǰ�Ķ��뷽��
- ������ڽӾ���ļ����Լ����ԵĴ��뷽������
- GCNAlign��ͬ���ļ����,��������,�ٶȿ�,Ч����,����ΪĬ�Ϲ���
- ����ƫ����ʵ������,���ֹ�ϵ,�������,����ֵ��Ӧ�á�
����
- �������:��ͬ����֪ʶͼ�е�ʵ�����
- ���:ʹ�ñȽϼķ���,������õ���֮ǰ�ķ������Ƶ�Ч��
- ���ķ���:����GCN����㷽��,��ͬʱ�Խṹ�����Ա���
- �ѵ�:��
- ����������̶�:ֱ�Ӿ���
(������Ŀ��ժҪ�����ۡ�ͼ����С����)
����
ժҪ
���з�����Ҫ���ڽ��������֪ʶͼ��ʵ��������⡣�������GCNs(graph convolutional networks),����Ԥ����ʵ��,ͨ��ѵ��,��ʵ�����Ϊ��ά������ʵ��������ʵ���Ƕ��ľ�����㡣Ƕ����ڶ�ͼ�ṹ��ʵ�����Ե�ѧϰ,��϶��ߵõ�����ȷ�Ľ����
1. ����
�ܶ�ʱ��,��Ҫ֪ʶ�ڲ�ͬ�����о�����ͬ����,ƥ��,���ӡ��ֹ�����ʵ��,��˲���Ѱ���Զ�������
��ͳ���뷽����������������߶�������Ե���������������֮��Ĺ�ϵ�����,���û���Ƕ��ķ�������,����MTransE,JAPE�ȡ�����ͼ����һЩԤ�����ʵ��,����Ƕ��ķ���ͨ��ѵ����ʵ��ת������ά�ռ�,Ȼ����������ڵ�ά�ռ�ı�ʾ����ƥ��,JE��ITransEҲ���ڵ������е�֪ʶ�ںϺͿ����Ե�֪ʶ���롣��������������������������������̡�
Ȼ��,���������������Ż�����,���� JE, MTransE��ITransE��ʹ�ó�����������ʧ����,JAPEʹ��Ԥ�����ʵ�彫����ͼ�϶�Ϊһ,����������Ȩ��ʵ��Ƕ���Ҫ����ṹ��Ϣ,��Ҫ����ȼ۹�ϵ������,������ϢҲӦ�ñ����õ����á�MTransE��ITransEδ����������Ϣ,JAPEֻ�������������͡�
�����������ͼ�����ķ���GCNsֱ�Ӷ�ʵ��ĵȼ۹�ϵ��ģ�����������ȡͼ�ṹ,���ýڵ���ھӱ���:�����Ե�ʵ����ھ�Ҳ�����ǶԵȵ�ʵ�塣����,�������Խ����˼���Ч�����á�
����ģ����Ҫ��������:
- ʹ��ͼ�е�ʵ���ϵ����GCNs,ֻʹ��ʵ����ͼ�еĶԵȹ�ϵ(û��JAPEʹ�ô�Ƕ��),ģ���Ӷȵ͡�
- ֻ��ҪԤ������ʵ����Ϊѵ������,����ҪԤ����Ĺ�ϵ�����ԡ�
- ��Ϲ�ϵ�ṹ��������Ч�������˶���Ч����
2. ��ع���
2.1 ͼǶ��
ͼǶ��:��ͼ��ʵ���ϵӳ�䵽��ά�ռ䡣ѧϰͼǶ��һ��ͨ����С��ȫ����ʧ�����������ڹ�ϵԤ��,��Ϣ��ȡ������
TransE
- ����Ч�ķ���
- ʱ��:2013��
- ԭ��: h + r �� t h+r \approx t h+r��t ������ͷʵ��ӹ�ϵԼ��βʵ��
- ��ʧ����:��С��ѵ�����ϻ��ڲ�ֵ�������
- �����㷨:TransH,TransR,TransD,������ģ�������˸��Ӷ�,������Ч��
2.2 ����Ƕ���ʵ�����
JE
- ʱ��:2016��
- ������ͼӳ�䵽ͬһǶ��ռ�
- ͨ�����Ӷ�����ͼ
- ͼǶ��ʹ��TransE�Ľ��㷨
- ��ʧ����:TransE��ʧ+ȫ�ֶ�����ʧ
MTransE
- ʱ��:2017��
- ������ͼӳ�䵽��ͬǶ��ռ�
- �ṩת������ת������ռ�
- ͼǶ��ʹ��TransE�Ľ��㷨
- ��ʧ����:֪ʶͼģ��+����ģ��
- ѵ��ʱ,��Ҫ��ͼ�ж������Ԫ��
JAPE
- ʱ��:2017��
- ����˽ṹǶ�������Ƕ��
- �ṹǶ��ʹ��TransE
- ����Ƕ��ʹ��Skip-gramģ��,�����Ե������
- ��ҪԤ�ȶԹ�ϵ�����Զ���
ITransE
- ʱ��:2017��
- ��ʹ��TransEѧϰʵ��ͱߵ�Ƕ��
- ���ö�������ѧϰ��ͬ���Կ������Ͽռ��֪ʶͼӳ��
- ͨ��ʹ���·��ֵ�ʵ�����������ʵ�������Ƕ��,�Ӷ�ʵ�ֵ���ʵ�����
- Ҫ����KG֮�乲�����й�ϵ
��������ģ�Ͷ�ʹ�����ƿ��:��TransEѧϰʵ��Ƕ��,�ٶ������ʵ��Ƕ��֮��ı任�Ͷ��롣
��������ķ���ʹ���˲�ͬ���,��ʹ��GCNS��ʵ��Ƕ�뵽ͳһ�������ռ���,���ж����ʵ�屻���������ܽӽ�,����ֻѧϰʵ��Ƕ��,��ѧϰ��Ƕ��,�������Ҫ�ߵ��������֪ʶ��
3. ���ⶨ��
KGsʹ����Ԫ��,��Ԫ���ַ�Ϊ��ϵ��Ԫ�顴entity1,relation,entity2����������Ԫ�顴entity,attribute,value��,���з���ʹ�������֡�
KG ����Ϊ G =(E,R,A,TR,TA),����EΪʵ��,RΪ��ϵ,AΪ����,TRΪ��ϵ��Ԫ��,TAΪ������Ԫ��,�÷���V�������Եľ���ֵ��
��G1,G2�ֱ������ͬ���Ե�����ͼ ��
S
=
{
(
e
i
1
,
e
i
2
)
�O
e
i
1
��
E
1
,
e
i
2
��
E
2
}
i
=
1
m
S={\{(e_{i1},e_{i2})|e_{i1}\in E_1,e_{i2} \in E_2}\}^m_{i=1}
S={(ei1?,ei2?)�Oei1?��E1?,ei2?��E2?}i=1m?
S��G1��G2֮��m��Ԥ�ȶ����ʵ���,�����ӡ���������Ϊ���벻ͬ���Ե�֪ʶͼ,������֪�Ķ��������ҵ��µ�ʵ����롣����DBpedia��YAGO���������ݼ�,�������ö����Լ�����������Ԥ������ʵ��ԡ�������Ϊ��������е�ѵ�����ݡ�
4. ����
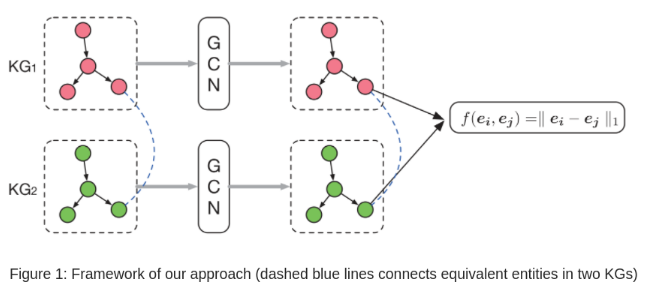
��ͼ-1��ʾ,KG1��KG2�ֱ��Dz�ͬ���Ե�����ͼ,��������Ķ�������S,����GCN��������ͼ�и����ʵ����롣����˼��������GCN����ͬ���Ե�ʵ��Ƕ�뵽ͬһ�������ռ�,��ȵ�ʵ���ڿռ��еľ���Խ��Խ�á��������ȶ���õľ��뺯����Ϊ���ȡ�
4.1 ����GCN��ʵ��Ƕ��
GCN��һ��ֱ�Ӳ���ͼ���ݵ�������ṹ,��ʹ�ö˵��˵�ѧϰ��Ԥ��,�������������С����״��ͼ,���������ǽڵ�ͽṹ����������,��Ŀ����ѧϰһ�ַ�������ʾ���������,�����ɽڵ㼶�������GCN���Խ��ھӽڵ����Ϣ�����ʵ�ʵ�ֵ,���������εķ���ع������ͼ�����������������������:(1)��Խڵ������������(2)��ͬ�ڵ���ھ���ͬ��GCNs�����������Ϣ�ͽṹ��Ϣ,���з���ʹ��GCN����Ϣת������ά�����ռ���,���ƵĽڵ��ڸÿռ��б���Ҳ���ơ�
һ��GCNģ�Ͱ��������,��l���������һ��nxd(l)����������,����n��ͼ�нڵ����,d(l)�ǵ�l�������������l��������ͨ��ͼ���ּ�����ľ���:
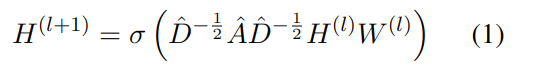
���� ���Ǽ����,A��nxn���ڽӾ���,��������ͼ����ͨ��,A=A+I,�������˵�λ����I,I�����˽ڵ���������ͨ��;D�ǶȾ���,����W(l)��d(l)xd(l+1)�IJ�������,���ڵ�l�������l+1��ת����
�ṹ������Ƕ��
���з�������ͬͼ�еĽڵ�ӳ�䵽ͬһ�����ռ�,Ϊ�����ýڵ�Ľṹ��������Ϣ,�������Ƕȶ�����������h��ÿһ���������������,�ṹ����hs(0)�������ʼ��,��ѵ�������и���;��������ha(0)Ҳ��ѵ�������и��¡�H�����������ı�ʾ��W��ѵ���õ��IJ�����
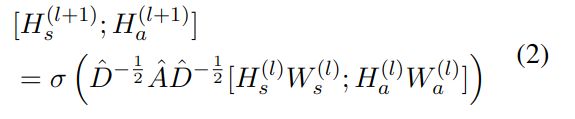
��ʽ�е�[ ; ] ��ʾconcat������������;�����ʹ��ReLU(.)=max(0,.)��
ģ������
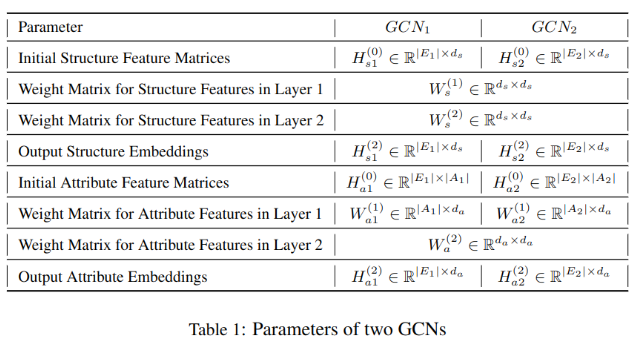
���з���ʹ��������GCN,ÿ�㴦��һ��ͼ��������ʵ��Ƕ��,������ͼ�ֱ�����GCN1��GCN2,����ʵ��Ľṹ������ʹ��ds��Ϊ��ά��,����ģ������������Ws������ʵ�����������,���������ά��Ϊda,��������ͼ������������ͬ,����ģ�͵���������������ͬ,ά��Ҳ��ͬ�����,��һ�㽫����ת����ͬһά��da(����W��ͬ),�ڶ�������GCN���Ϊͬһά��da��
��-1չʾ�˸����ݵ�ά��:
�����ڽӾ���
��GCNģ����,�ڽӾ���A�����ھ������㡣������ͼ��ͬ����,��ǰͼ�������ֹ�ϵ�����,���¶�����A:aij ��A,aij��ʵ��i������ʵ��j�ij̶�,ͨ����ͬ�Ĺ�ϵ���ӵ�ʵ��,�ȼ۵ĸ���Ҳ��ͬ(�����ϵ:��ĸ������)����˶�ÿ�ֹ�ϵ��������������:

���� #Triples_of_r �ǰ�����ϵr����Ԫ�����; #Head_Entities_of_r �� #Tail_Entities_of_r ��ͷ/βʵ���ϵrͬʱ���ڵĸ�����������������i��ʵ��Ե�j��ʵ���Ӱ��,�Լ����ڽӾ���:
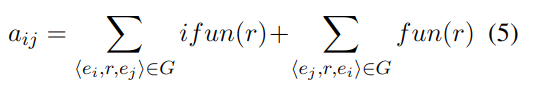
��ͬʱ��Ӧ������ͷ����ǿ�ȡ���������:
��һ:���ӹ�ϵ
��������:
f
u
n
=
1
4
i
f
u
n
=
1
4
a
i
j
=
1
4
+
1
4
=
0.5
\begin{aligned} & fun=\frac{1}{4} \\ & ifun=\frac{1}{4} \\ & a_{ij}=\frac{1}{4}+\frac{1}{4}=0.5 \end{aligned}
?fun=41?ifun=41?aij?=41?+41?=0.5?
�Ŵ�������:
f
u
n
=
3
4
i
f
u
n
=
1
4
a
i
j
=
3
4
+
1
4
=
1
\begin{aligned} & fun=\frac{3}{4} \\ & ifun=\frac{1}{4} \\ & a_{ij}=\frac{3}{4}+\frac{1}{4}=1 \end{aligned}
?fun=43?ifun=41?aij?=43?+41?=1?
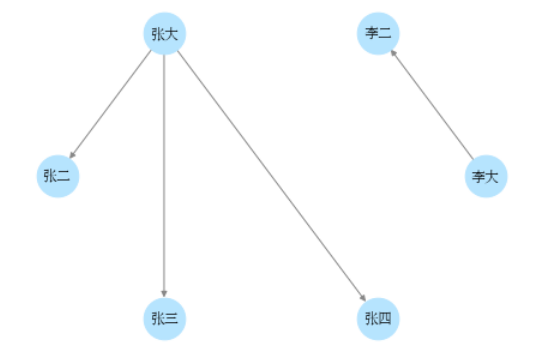
����:���ѹ�ϵ
(Ϊ�Ա�,�������ѹ�ϵ������ͼ,ʵ�ʲ�����)
f
u
n
=
2
12
i
f
u
n
=
1
12
a
i
j
=
2
12
+
1
12
=
0.25
\begin{aligned} & fun=\frac{2}{12} \\ & ifun=\frac{1}{12} \\ & a_{ij}=\frac{2}{12}+\frac{1}{12}=0.25 \end{aligned}
?fun=122?ifun=121?aij?=122?+121?=0.25?
��֮:ij�ֹ�ϵ����Խ��,���������ӵ�ʵ��Ӱ��Խ��(����TF/IDF)�����縸�ӹ�ϵ������Ӱ���,���ѹ�ϵ���ֶ�Ӱ��С��
4.2 ����Ԥ��
ʵ������������ͼGCN�������ľ��롣��ͼG1��ʵ��Ϊei,G2��ʵ��Ϊvj���������:

����f(x,y)��1����(����Ԫ�ؾ���ֵ֮��),hs��ha��ʵ��ĽṹǶ�������Ƕ��,ds��da�����ά��,�������ں����ṹ�����Եij�������
ʵ��Խ����,����Խ��������G1��ei��G2������ʵ��ľ���,��������ƶ���ߵ�ʵ����Ϊ����ĺ�ѡ�G2��G1����Ҳ��ͬ��(����ͬ�����ͬ)��
4.3 ģ��ѵ��
ʹ������S��ѵ��GCNģ��,��С�����ڱʵ�������ʧ����:
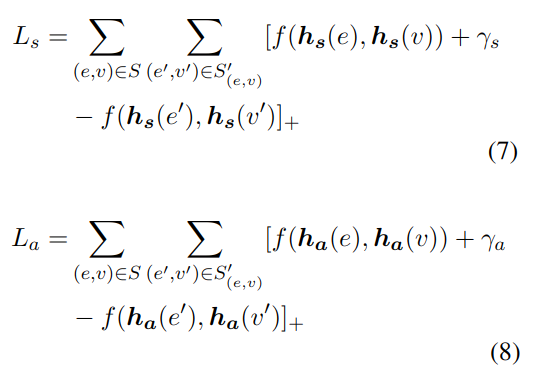
����[x]+=max{0,x},S������e��v����滻�õ��ĸ���,f���ڼ������,��s,��a > 0�dz�����,�������������Ч��,�����������������֮��ľ���(��������Ҫ�ȸ������,loss���ܵ���0)��
Ls��La�ֱ��ǽṹ�����Ե���ʧ����,���������,Ҳ�ֿ��Ż�,���巽��ʹ������ݶ��½���
5. ʵ��
5.1 ���ݼ�
DBP15K����Sun��2017�깹����,����DBpedia�Ķ����Զ������ݼ�,����:����,Ӣ��,����,���ġ�ÿ�����ݰ�����������15K��ʵ��Ķ���,����ѵ���Ͳ��ԡ�
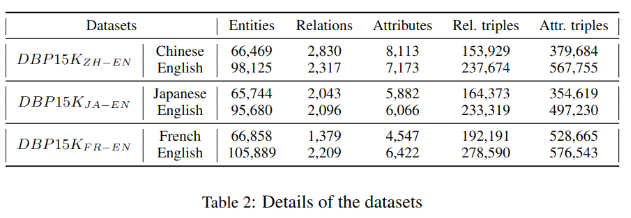
5.2 ʵ������
ʹ��JE,MTransE,JAPE,JAPE��(��Ԥ�����ϵ��ʵ��)��Ϊ�ԱȻ���,30%��Ϊѵ����,70%��Ϊ���Լ���
Hits@kָ������ȷ�����ʵ������ǰk����ѡʵ���еı�����
���������ó����ά��ds=1000,da=1000, ��s = ��a = 3, �������ʱ�� �� ��Ϊ����ֵ0.9(��ϵռ90%,����ռ��10%)��
5.3 ���

(ͼ̫��,����һ����)
���йؼ���:SE w/o neg�������Ľṹ��Ԫ��,SE�ǽṹ��Ԫ��,AE��������Ԫ�顣
GCN(SE)��GCN(SE+AE)
���Կ�������������Ԫ���,Ч��������Χ��1%-10%֮�䡣��˵��������Ҫ�����ṹ��Ϣ,��������ϢҲ������,���н�϶��ߵķ���Ҳ����Ч�ġ�
GCN(SE+AE) �����
����Ӣ�����������JAPE����������,GCN�����֮���������Ҫע�����JAPEʹ���˶������Ϣ(��Ƕ��),������ģ��δʹ����Щ����֪ʶ,JAPE����δʹ������֪ʶ�������Ч���Ͳ��˺ܶࡣ�����������ݼ���,����ģ��Ч�����á����JE��MTransEЧ������������
GCN��JAPEʹ�ò�ͬ����ѵ������
��Ԥ����ʵ����Ϊ����,ֱ����ѵ������Խ��,Ч��Ӧ��Խ�á�

ͼ��չʾ��ȡ10%-50%��Ϊѵ�����Ա�Hits@1,JAPE��GCNģ��Ч��,����ͼ-2(a)��Ӣ��ѵ��������40%�����,����GCN������JAPE��
�ܽ��δ������
GCN����ʹ���˽ṹ��������Ԫ��,�ڸ������ݼ��ϱ��ֶ��Ϻá�
δ����̽���������GCN�ķ���,���� Relational GCNs, Graph Attention Networks;�Լ������п���ϵ����ط����µ�ʵ����롣

