Pytorch ОЕфОэЛ§ЩёОЭјТч LeNet
0. ЛЗОГНщЩм
ЛЗОГЪЙгУ Kaggle РяУтЗбНЈСЂЕФ Notebook
НЬГЬЪЙгУРюухРЯЪІЕФ ЖЏЪжбЇЩюЖШбЇЯА ЭјеОКЭ ЪгЦЕНВНт
аЁММЧЩ:ЕБгіЕНКЏЪ§ПДВЛЖЎЕФЪБКђПЩвдАД Shift+Tab ВщПДКЏЪ§ЯъНтЁЃ
1. LeNet
1.0 МђНщ
LeNet ЪЧзюдчЗЂВМЕФОэЛ§ЩёОЭјТчжЎвЛ,вђЦфдкМЦЫуЛњЪгОѕШЮЮёжаЕФИпаЇадФмЖјЪмЕНЙуЗКЙизЂЁЃ етИіФЃаЭЪЧгЩ AT&T БДЖћЪЕбщЪвЕФбаОПдБ Yann LeCun дк 1989 ФъЬсГіЕФ(ВЂвдЦфУќУћ),ФПЕФЪЧЪЖБ№ЭМЯё [LeCun et al., 1998] жаЕФЪжаДЪ§зжЁЃ ЕБЪБ,Yann LeCun ЗЂБэСЫЕквЛЦЊЭЈЙ§ЗДЯђДЋВЅГЩЙІбЕСЗОэЛ§ЩёОЭјТчЕФбаОП,етЯюЙЄзїДњБэСЫЪЎЖрФъРДЩёОЭјТчбаОППЊЗЂЕФГЩЙћЁЃ
ЕБЪБ,LeNetШЁЕУСЫгыжЇГжЯђСПЛњ(support vector machines)адФмЯрцЧУРЕФГЩЙћ,ГЩЮЊМрЖНбЇЯАЕФжїСїЗНЗЈЁЃ LeNet БЛЙуЗКгУгкздЖЏШЁПюЛњ(ATM)Лњжа,АяжњЪЖБ№ДІРэжЇЦБЕФЪ§зжЁЃ ЪБжСНёШе,вЛаЉздЖЏШЁПюЛњШддкдЫаа Yann LeCun КЭЫћЕФЭЌЪТ Leon Bottou дкЩЯЪРМЭ 90 ФъДњаДЕФДњТыЁЃ
ТлЮФЕижЗ:https://axon.cs.byu.edu/~martinez/classes/678/Papers/Convolution_nets.pdf
ЦфжаЕФЪжаДЪ§зж MNIST Ъ§ОнМЏ:
- 50 , 000 50,000 50,000 ИібЕСЗЪ§Он
- 10 , 000 10,000 10,000 ИіВтЪдЪ§Он
- ЭМЯёДѓаЁ 28 ЁС 28 28 \times 28 28ЁС28
- 10 10 10 Рр ( 0 Ёњ 9 ) (0 \to 9) (0Ёњ9)
1.2 LeNet НсЙЙ
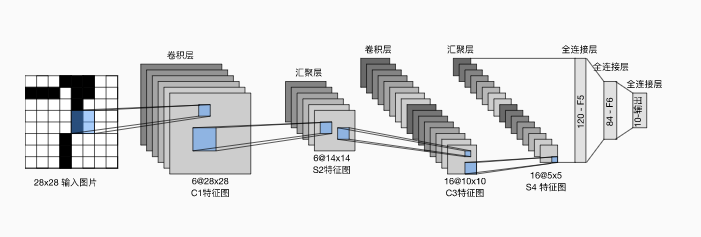
УПИіОэЛ§ПщжаЕФЛљБОЕЅдЊЪЧвЛИіОэЛ§ВуЁЂвЛИі sigmoid МЄЛюКЏЪ§КЭЦНОљГиЛЏВуЁЃ
зЂ:ЫфШЛ ReLU МЄЛюКЏЪ§КЭзюДѓГиЛЏВуИќгааЇ,ЕЋЫќУЧдк20ЪРМЭ90ФъДњЛЙУЛгаГіЯжЁЃ
УПИіОэЛ§ВуЪЙгУ 5 ЁС 5 5\times 5 5ЁС5 ОэЛ§КЫКЭвЛИі sigmoid МЄЛюКЏЪ§ЁЃетаЉВуНЋЪфШыгГЩфЕНЖрИіЖўЮЌЬиеїЪфГі,ЭЈГЃЭЌЪБдіМгЭЈЕРЕФЪ§СПЁЃЕквЛОэЛ§Вуга 6 6 6 ИіЪфГіЭЈЕР,ЖјЕкЖўИіОэЛ§Вуга 16 16 16 ИіЪфГіЭЈЕРЁЃЪЙгУ 2 ЁС 2 2\times 2 2ЁС2 ЕФЦНОљГиЛЏДАПкЭЈЙ§ПеМфЯТВЩбљНЋЮЌЪ§МѕЩй4БЖЁЃ
ЯШЪЙгУОэЛ§ВуРДбЇЯАЭМЦЌПеМфаХЯЂ,ШЛКѓЪЙгУШЋСЌНгВуРДзЊЛЛЕНРрБ№ПеМфЁЃ
2. ДњТыЪЕЯж
2.1 ЭјТчНсЙЙ
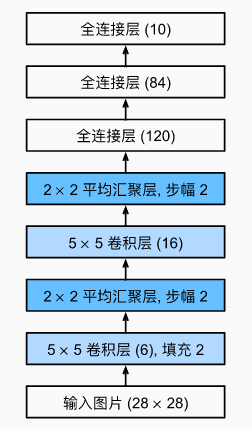
ЖддЪМФЃаЭзіСЫвЛЕуаЁИФЖЏ,ШЅЕєСЫзюКѓвЛВуЕФИпЫЙМЄЛюЁЃГ§ДЫжЎЭт,етИіЭјТчгызюГѕЕФ LeNet-5 вЛжТЁЃ
!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)

дкећИіОэЛ§Пщжа,гыЩЯвЛВуЯрБШ,УПвЛВуЬиеїЕФИпЖШКЭПэЖШЖММѕаЁСЫЁЃ ЕквЛИіОэЛ§ВуЪЙгУ
2
2
2 ИіЯёЫиЕФЬюГф,РДВЙГЅОэЛ§КЫЕМжТЕФЬиеїМѕЩйЁЃ ЕкЖўИіОэЛ§ВуУЛгаЬюГф,вђДЫИпЖШКЭПэЖШЖММѕЩйСЫ
4
4
4 ИіЯёЫиЁЃ ЫцзХВуЕўЕФЩЯЩ§,ЭЈЕРЕФЪ§СПДгЪфШыЪБЕФ
1
1
1 Иі,діМгЕНЕквЛИіОэЛ§ВужЎКѓЕФ
6
6
6 Иі,дйЕНЕкЖўИіОэЛ§ВужЎКѓЕФ
16
16
16 ИіЁЃ ЭЌЪБ,УПИіЦНОљГиЛЏВуЕФИпЖШКЭПэЖШЖММѕАыЁЃзюКѓ,УПИіШЋСЌНгВуМѕЩйЮЌЪ§,зюжеЪфГівЛИіЮЌЪ§гыНсЙћЗжРрЪ§ЯрЦЅХфЕФЪфГіЁЃ
2.2 Мгди Fashion-MNIST Ъ§ОнМЏ
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
2.3 ЦРМлКЏЪ§
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""ЪЙгУGPUМЦЫуФЃаЭдкЪ§ОнМЏЩЯЕФОЋЖШ"""
if isinstance(net, nn.Module):
net.eval() # ЩшжУЮЊЦРЙРФЃЪН
if not device:
device = next(iter(net.parameters())).device
# е§ШЗдЄВтЕФЪ§СП,змдЄВтЕФЪ§СП
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERTЮЂЕїЫљашЕФ(жЎКѓНЋНщЩм)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
2.4 бЕСЗКЏЪ§
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""гУGPUбЕСЗФЃаЭ(дкЕкСљеТЖЈвх)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
# ЪЙгУ xavier ШЈжиГѕЪМЛЏ
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# бЕСЗЫ№ЪЇжЎКЭ,бЕСЗзМШЗТЪжЎКЭ,бљБОЪ§
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
2.5 гУ CPU бЕСЗ
дк kaggle жа Accelerator ЩшжУЮЊ NoneЁЃ
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
УПУыБщРњ
5612.2
5612.2
5612.2 ИібљБОЁЃ
2.6 гУ GPU бЕСЗ
дк kaggle жаЪЙгУ GPU:
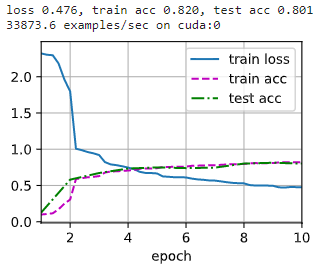
УПУыБщРњ
33873.6
33873.6
33873.6 ИібљБО,ПЩвдЗЂЯжБШ CPU бЕСЗПьСЫВЛЩйЁЃ
бЕСЗМЏОЋЖШ
0.820
0.820
0.820,ВтЪдМЏОЋЖШ
0.801
0.801
0.801ЁЃ
2.7 ГЂЪдИќЛЛМЄЛюКЏЪ§ЮЊ ReLU вдМАГиЛЏВуЛЛГЩзюДѓГиЛЏ,ЕїећбЇЯАТЪ
net2 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.ReLU(),
nn.Linear(120, 84), nn.ReLU(),
nn.Linear(84, 10))
# бЇЯАТЪ 0.9 ЕФЪБКђЛсВЛЪеСВ,ЫљвдЕїећЮЊ 0.1
lr, num_epochs = 0.1, 10
train_ch6(net2, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
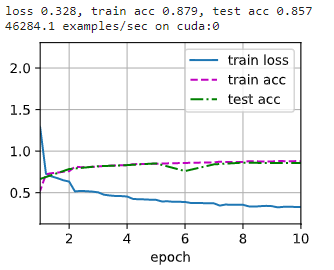
бЕСЗМЏОЋЖШ 0.879 0.879 0.879,ВтЪдМЏОЋЖШ 0.857 0.857 0.857,ЯрЖдгкжЎЧАЕФФЃаЭШЗЪЕгаЬсИпЁЃ

