1.BP神经网络
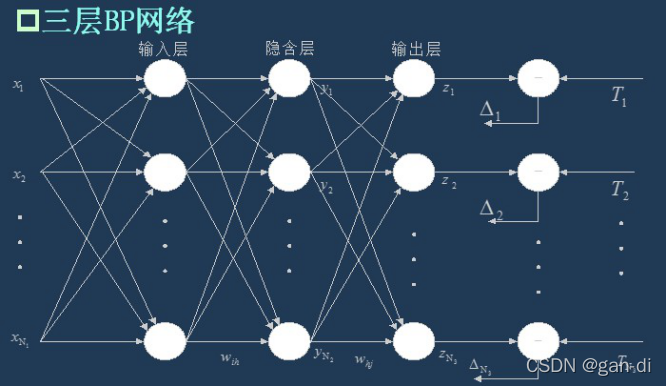
BP神经网络可以分为两个部分,BP和神经网络,BP是 Back Propagation 的简写 ,意思是反向传播。而神经网络,可以说是一类相对复杂的计算网络。 正向传播就是让信息从输入层进入网络,依次经过每一层的计算,得到最终输出层结果的过程。反向传播的信息是误差,也就是输出层的结果与输入信息x对应的真实结果之间的差距。 通过一次正向传播,和一次反向传播,我们就可以将网络的参数更新一次,所谓训练网络,就是让正向传播和反向传播不断的往复进行,不断地更新网络的参数,最终使网络能够逼近真实的关系。
理论上,只要网络的层数足够深,节点数足够多,可以逼近任何一个函数关系。但是这比较考验你的电脑性能,事实上,利用 BP 网络,能够处理的数据其实还是有限的,但是这并不影响 Bp 网络是一种高明的策略。
结合实现中文分词的模型解释:
(1)随机设下一个起始点,并固定下来,确保每一次运行时都有同一个起始点。
(2)加载模型需要的参数。
加载字表。字表的生成:对训练文本去重复,按照字频从高到低排序,并编号。
加载训练数据:未进行分词的句子。
加载标签:通过SBME来标识已进行过分词的训练数据。
加载学习率;轮次;一个字用多少维度的向量来表示;(原模型只有一个隐藏层,此处增加一层)第一个隐藏层的输出大小;第二个隐藏层的输出大小。
(3)加载模型
(4)模型预测
(5)评价预测准确率
2.模型具体参数以及主要部分代码实现
(1)模型具体参数
学习率――0.000015
轮次――5->8->10(效果不再有显著提升)
输出维度――4 (对每一个字预测SBME中的一个标签)
每一个字的向量维度――16
第一层输出维度――32
第一层输出维度――64
(2)模型实现部分
1.一个输入层:输入维度――字表大小,输出维度――字的向量维度16;
两个隐藏层:
2.第一层隐藏层:输入维度――字的向量维度16,输出维度――32;
3.第二层隐藏层:输入维度――32,输出维度――64;
4.做非线性变换,维度不变;
5.一个输出层:输入维度――64,输出维度――4;
6.使用softmax()函数,将输出数据归一化,概率最大的数的下标即为预测值。
3.模型评价结果
(1)Accuracy,中文为准确率,指的是“预测正确的样本数÷样本数总数”。计算公式为:
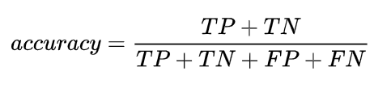
(2)Precision,中文为精确率或者精度,指的是在我们预测为True的样本里面,有多少确实为True的。在信息检索领域,precision也被称为“查准率”。其公式为:
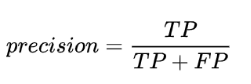
(3)Recall,中文是召回率,指的是,实际上为True的样本有多少被我们挑出来了。在信息检索领域,recall也被称为“查全率”。其公式为:
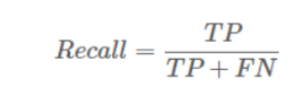
(4)Accuracy和Recall的调和指标:F1 Score
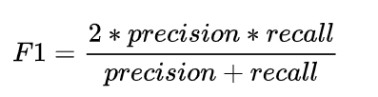
4.正式开始
先放上代码的框架:

1.训练样本 train.txt(文章末有链接)
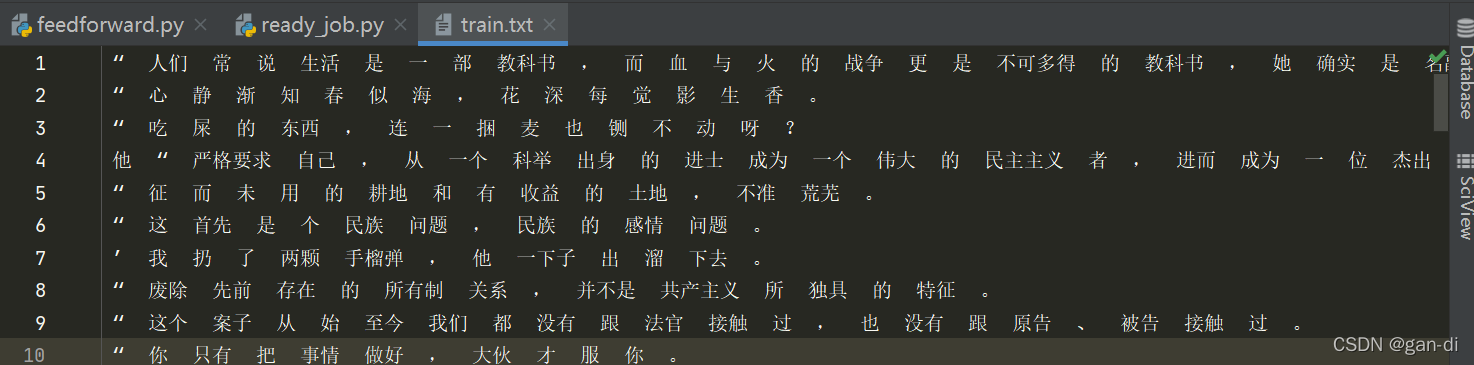

可以看到是已经分好词的文本,一共有5000行。接下来我们就利用这个训练样本来训练我们的分词模型,目标是提取中文分词的规律,就像我们找一个数列的规律,不过这一次我们借助计算机的脑子。
2.训练样本的预处理
#WordsegBP/utils/ready_job.py
#generate train_data
#generate target_data
#generate vocal_table
import pickle as pkl
import time
def build_train_data(file_path): #file_path = '../data/train.txt'
with open(file_path,'r',encoding='utf-8') as f:
lines = f.readlines()
phrase_expel = []
for i in lines: #把读到的文件中的 引号 回车 和 空格 删掉
t1 = i.replace('“ ','')
t2 = t1.replace('\n','')
t3 = t2.replace(' ','')
phrase_expel.append(t3)
with open('../data/generate_pkl/train_data.pkl', 'wb') as f: #把这个处理后的文件当作训练数据
pkl.dump(phrase_expel, f) #把文件写成pkl格式
def build_target(file_path): #生成目标文件
with open(file_path,'r',encoding='utf-8') as f:
tmp = f.readlines() #tmp为每一行的数据
t = []
for i in tmp: #删掉引号和回车,这里不删空格,空格是分词的标志
t1 = i.replace('“ ','')
t2 = t1.replace('\n','')
t.append(t2)
sum_list = []
for i in t:
sum_ = ''
for j in i.split(): #以空格为分割,一个词一个词的提取
if len(j) == 1: #如果词的长度为1 ,就标记为S -single
sum_ += 'S'
continue
else:
sum_ += 'B' #如果长度不为1,标记为一个词的开始 begin
for k in range(1, len(j)):
if k == len(j) - 1: #如果是这个词的最后一个,就标记为end
sum_ += 'E'
else:
sum_ += 'M' #其他情况就是middle
sum_list.append(sum_)
with open('../data/generate_pkl/target.pkl', 'wb') as f:
pkl.dump(sum_list, f)
def build_vocab_dict(file_path): #'../data/train_data.pkl'
vocab_dic = {}
with open(file_path, 'rb') as f:
z = pkl.load(f)
for line in z:
for hang in line: #统计词频,按照词多到少排列
vocab_dic[hang] = vocab_dic.get(hang, 0) + 1
vocab_dic_sorted = sorted(vocab_dic.items(), key=lambda x: x[1], reverse=True)
vocab_dic2 = {word_count[0]: idx for idx, word_count in enumerate(vocab_dic_sorted)}
with open('../data/generate_pkl/vocab.pkl', 'wb') as f:
pkl.dump(vocab_dic2, f)
if __name__ == '__main__':
build_train_data('../data/train.txt')
time.sleep(5)
build_target('../data/train.txt')
build_vocab_dict('../data/generate_pkl/train_data.pkl')
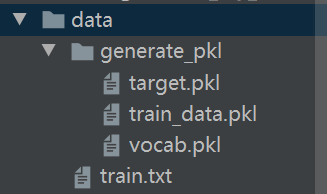
运行后得到如下三个pkl文件:
3.简单的BP神经网络构建,由于这里比较简洁,就没有单独在一个文件夹models里面放这个模型,而是直接写在main里面了。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import pickle as pkl
from tqdm import tqdm
class Config(object):
#parameters settings
def __init__(self):
self.vocab = pkl.load(open('../data/generate_pkl/vocab.pkl', 'rb')) # 读取词表
self.train_data = pkl.load(open('../data/generate_pkl/train_data.pkl', 'rb')) # 读取训练数据
self.target = pkl.load(open('../data/generate_pkl/target.pkl', 'rb')) # 读取标签
self.learning_rate = 0.000015 # 学习率
self.epoch = 5 # epoch次数
self.output_size = 4
self.embed_dim = 16
self.hout1 = 32
self.hout2 = 64
class Model(nn.Module):
def __init__(self, output_size, vocab_size, embed_dim,hout1,hout2):
super(Model, self).__init__()
#把每一个字都表示为embed_dim维的字向量
self.embedding = nn.Embedding(vocab_size, embed_dim)
#隐藏层为全连接层
self.hid_layer1 = nn.Linear(embed_dim, hout1)
self.hid_layer2 = nn.Linear(hout1, hout2)
self.out_layer = nn.Linear(hout2, output_size)
#self指的是上面的初始化模型参数,in_layer指的是待分词的句子的张量表示
def forward(self, in_layer):
#将in_layer张量中的每一个元素(字的序号)都变成一个embed_dim维的张量
emd = self.embedding(in_layer)
#将每个字从一个embed_dim维变为hout1维的向量,神经元的出现(w,b)
h_out1 = self.hid_layer1(emd)
#将每个字从一个hout1维变为hout2维的向量,神经元的增加(w‘,b’)
h_out2 = self.hid_layer2(h_out1)
#非线性变换
out_ = F.relu(h_out2)
#将hout2维变为output_size维
out_ = self.out_layer(out_)
#每一个字都会得到到一个 为BMES的概率,最大的即为所预测的
out_ = F.softmax(out_, dim=1)
return out_
def model_eval(model_out, true_label):
confusion_matrix = torch.zeros([2, 2], dtype=torch.long)
predict_label = torch.argmax(model_out, 1)
accuracy = []
precision = []
recall = []
f_1 = []
for l in range(4):
tp_num, fp_num, fn_num, tn_num = 0, 0, 0, 0
for p, t in zip(predict_label, true_label):
if p == t and t == l:
tp_num += 1
if p == l and t != l:
fp_num += 1
if p != l and p != t:
fn_num += 1
if p != l and p == t:
tn_num += 1
accuracy.append((tp_num + tn_num) / (tp_num + tn_num + fp_num + fn_num))
try:
prec = tp_num / (tp_num + fp_num)
except:
prec = 0.0
try:
rec = tp_num / (tp_num + fn_num)
except:
rec = 0
precision.append(prec)
recall.append(rec)
if prec == 0 and rec == 0:
f_1.append(0)
else:
f_1.append((2 * prec * rec) / (prec + rec))
ave_acc = torch.tensor(accuracy, dtype=torch.float).mean()
ave_prec = torch.tensor(precision, dtype=torch.float).mean()
ave_rec = torch.tensor(recall, dtype=torch.float).mean()
ave_f1 = torch.tensor(f_1, dtype=torch.float).mean()
return ave_acc, ave_prec, ave_rec, ave_f1
def test_(model_):
text = '这是一个最好的时代。'
hang_ = []
for wd in text:
hang_.append(Config().vocab[wd])
test_tensor = torch.tensor(hang_, dtype=torch.long)
res = model_(test_tensor)
res = res.detach().numpy()
[print(np.argmax(r)) for r in res]
print(res)
if __name__ == '__main__':
#设置参数的起点
torch.manual_seed(1)
config = Config()
voc_size = len(config.vocab)
train_data_list = []
for lin in config.train_data:
hang = []
for word in lin:
hang.append(config.vocab[word])
#将列表类型转变为张量类型
train_data_list.append(torch.tensor(hang, dtype=torch.long))
target_dict = {'B': 0,
'M': 1,
'E': 2,
'S': 3}
target_list = []
for lin in config.target:
hang = []
for tag in lin:
hang.append(target_dict[tag])
target_list.append(torch.tensor(hang, dtype=torch.long))
#现在 train_data_list target_list 里面的元素都是张量,它们是由张量构成的列表
model = Model(config.output_size, voc_size, config.embed_dim,config.hout1,config.hout2)
#model __init__()函数已经生效了
losses = []
acc = []
rec = []
prec = []
f1 = []
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
#model.parameters()这里的参数就是__init__()函数里面的
loss_f = nn.CrossEntropyLoss()
#实现进度条式输出
for i in tqdm(range(config.epoch)):
for j, k in enumerate(train_data_list):
optimizer.zero_grad()
#开始forward的作用,预测句子k的标签
out = model(k)
#计算交叉熵损失
loss = loss_f(out, target_list[j])
#误差反向传播
loss.backward()
#参数向前更新
optimizer.step()
#模型评价
acc_, prec_, rec_, f1_ = model_eval(out, target_list[j])
acc.append(acc_.item())
prec.append(prec_.item())
rec.append(rec_.item())
f1.append(f1_.item())
# print('acc: ' + str(acc_.item()) + '\tprec: ' + str(prec_.item()) +'\trec: ' + str(rec_.item()) + '\tf1: ' + str(f1_.item()))
losses.append(loss.item())
#保存当前的模型参数
torch.save(model, './cut.bin')
print('\nacc: ' + str(torch.tensor(acc).mean().item()) + '\tprec: ' + str(torch.tensor(prec).mean().item())
+'\trec: ' + str(torch.tensor(rec).mean().item()) + '\tf1: ' + str(torch.tensor(f1).mean().item()))
#对模型的测试,可以直观地看出分词效果
test_(model)
4.输出结果:
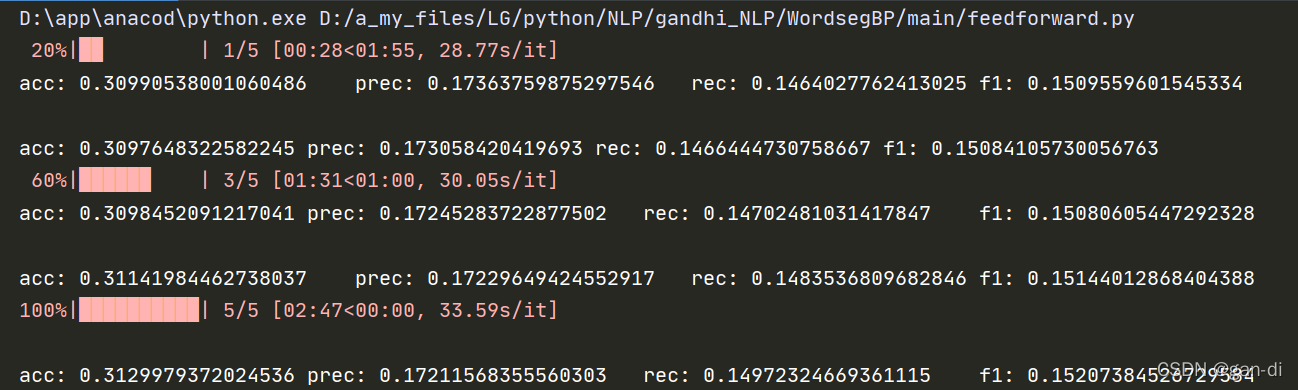
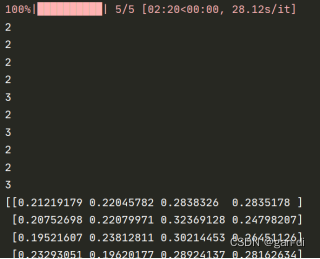
对应的标识为EEEESESES。即分词为 这 |是 |一|个 |最好| 的| 时| 代 。不是完全正确的,甚至有很明显的缺陷,效果不好。
保存的模型在modules/文件夹中――cut.bin。
资源:
train.txt:
链接:https://pan.baidu.com/s/1VcYQW4it5XtDwApL1r59_Q
提取码:2933

