����
�ƹ��������������ҫ2022KPL���������������ݷ���,�±�kpl�Ǵӹٷ�����ƽ̨��ȡ����2022KPL��������������500������������:
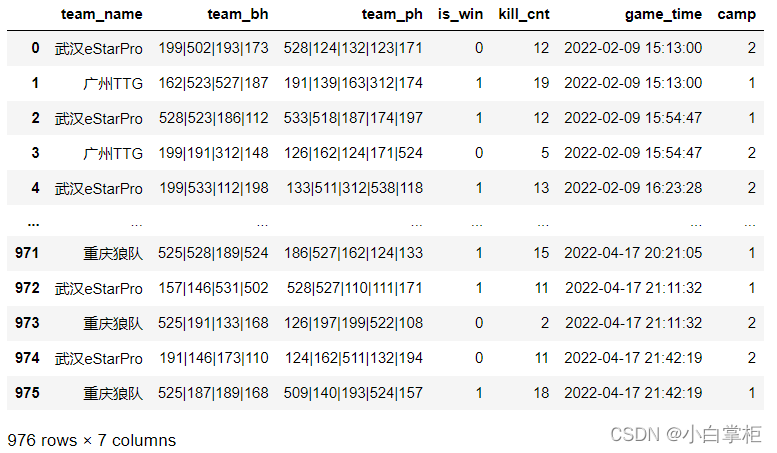
�����ҿ��Ժ����ԵĿ���team_bh��team_ph�������涼��һ������,��ʵ���Ƿֱ��������������ҫ����ĸ���Ӣ�ۡ��±�code�����ƹ�������2022KPL�������������dz�������Ӣ�ۺͶ�Ӧ�����ֱ���:

����
- ��kpl���е�team_bh��team_ph�������ݽ��в��,�ֱ�ó�ÿ��ս��ban(����)����λӢ�ۺ�pick(ѡ��)����λӢ��;
- �Բ�ֺ�Ľ���Ӣ�ۺ�ѡ��Ӣ�۸���code�����������滻��
˼·
- ��һ��������ʵ������pandas��DataFrame��һ�����������ݲ��Ϊ����,��ÿ��ֻ��һ�����ݵķ�������pandas��������������ı�����,����ʹ��.str.split()����������(|)���в��, �����µ�DataFrame;Ȼ������join���������кϲ�,���ɾ�������С�
- �ڶ�������������pandas�Ķ��н��ж�ֵ�滻�Ŀ��졣ͨ�����Բ���map()������replace()������apply()�����������滻��
���巽��
- �����ƹ���ȸ����ο����� ������˵:
import pandas as pd
ban_name = ['ban' + str(x+1) for x in range(4)] #�����ɵ�����(����Ӣ����λ)
ban = kpl['team_bh'].str.split('|', expand=True) #������|����
ban.columns = ban_name
kpl = kpl.join(ban) #�ϲ�����
kpl
��ֺ��Ч��ͼ:
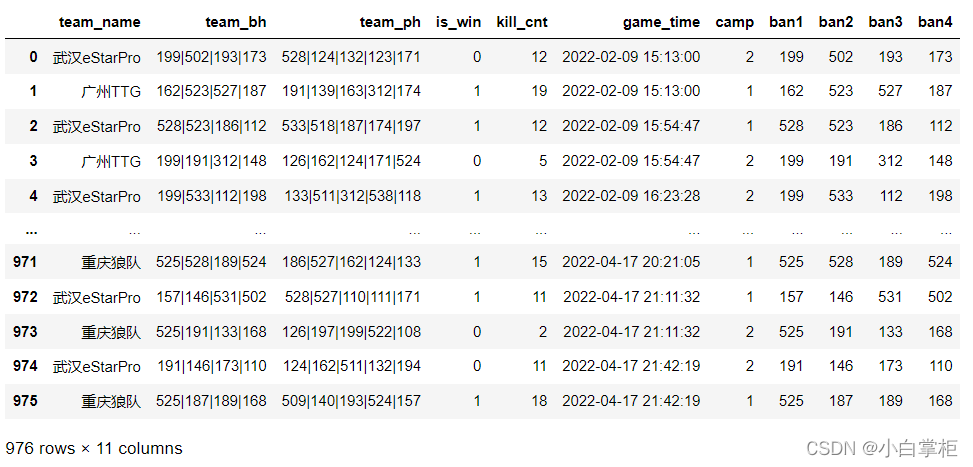
���Կ���������о��Dz�ֺ��ÿ�ӽ���Ӣ��,����ȡ��Ϊban��������1-4,��ʾ����Ӣ�۵�˳��,ban1�������Ƚ��õ�Ӣ����ͬ�����Զ�team_ph�н������ϲ���,Ȼ��ɾ��team_bh��team_ph����,�õ���ֺ����kpl��:
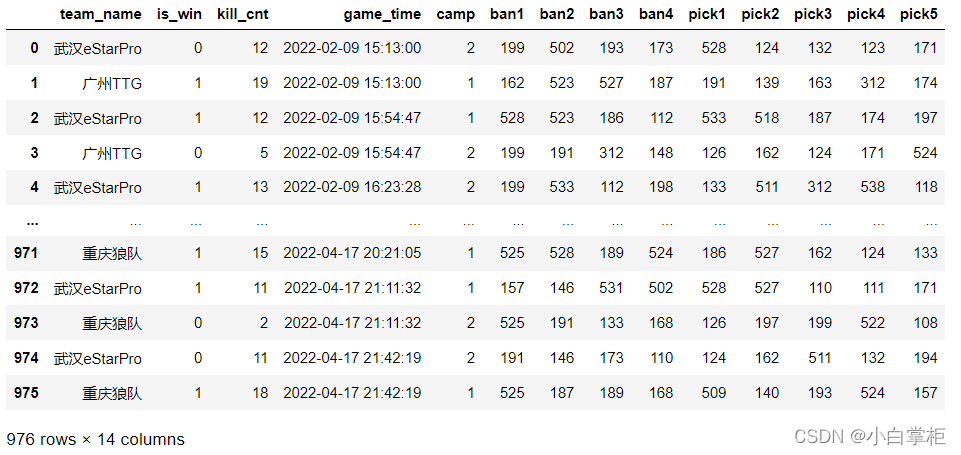
�����ͽ���˵�һ������,���������ڶ�������ľ��巽��:
- ��Ȼ�ȸ����ؼ��IJο�����(��ʵ��Ҫ��������):
hero_code = code.set_index(['code'])['hero'].to_dict()
kpl['ban1'] = kpl['ban1'].map(hero_code)
�滻���µ�kpl��:
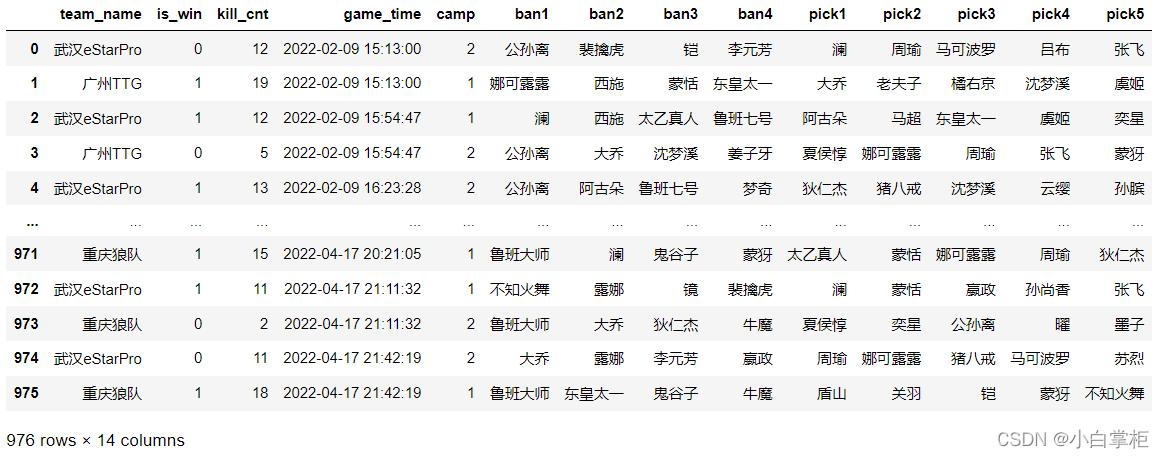
�����ƹ���code��������һ��ת��,����������ֱ���Ͷ�ӦӢ��ת��Ϊ�ֵ��ʽ,�������������������Ķ�ֵ�滻��
�����ƹ���map()��������һ��ӳ�����(Ҳ����ÿһ�е����ֶ������ֵ��е�key����һ��ƥ��,�������,���滻Ϊ��Ӧ��Ӣ������);��Ȼ����Ҳ����ʹ��replace()������apply()�������滻,�����ٶ�û��map()�����Ŀ���
���
�������ž����������kpl�������ݱ��ɾ��ܶ���,���ǿ���һ�۾Ϳ�����ÿ��ս�ӽ���Ӣ�۵�˳��(�������³���ʦ�������ڵ�һbanλ🤣)��ѡ��Ӣ�۵����ȼ�(�ĺ����һѡ�ĸ��ʽϴ�),���潫����ݸ���ս�ӽ���һϵ�е����ݷ������ھ���,�����ڴ�!🤝😁
PS:�����Ĵ������������Ŀ��������Github,лл���ĵȴ������⡣

