[LiteratureReview]CubeSLAM: Monocular 3-D Object SLAM
出处:2019 IEEE Transactions on Robotics,(截止到2022-3-30)Google论文被引162次;
P.S:相比RAL这种接收短文的期刊,IEEE Transactions on Robotics现在只接收长文,Cube-SLAM这篇论文正文13页;
作者主页:https://shichaoy.github.io/
Code:https://github.com/shichaoy/cube_slam
Cube-SLAM作者相关的其他论文(下列所有论文都可以在作者主页上找到):
- Monocular Object and Plane SLAM in Structured Environments. 2019 RAL;
- Direct Monocular Odometry Using Points and Lines. 2019 ICRA;
- Pop-up SLAM: Semantic Monocular Plane SLAM for Low-texture Environments. 2016 IROS;
- Real-time 3D Scene Layout from a Single Image Using Convolutional Neural Networks. 2016 ICRA;
- 作者博士论文:Monocular Visual SLAM with Object and Layout Understanding;
Introduction
方法概述:CubeSLAM利用目标检测算法生 成 2D boundingbox ,通过消失点法 ( Vanishing points,VP)生成物体3D Boundingbox,根据与图像边缘的对齐情况对提案进行进一步评分和选择,并将objects作为landmarks,结合物体约束信息与几何信息,融合到一个 最小二乘公式中 ,改善相机位姿估计 ,提高 了 SLAM 的定位精度,该方法在静态和动态环境下都可以工作;与基于特征点的 SLAM 系统相比,物体级 SLAM 系统可以提供更多的几何约束和尺度一致性,所提算法在公开数据集上得到了较好的位姿估计精度,同时还提高了 3D 物体的检测精度;
Object以两种方式使用:
- 在 BA 中提供几何和尺度约束;
- 为难以三角测量的点提供深度初始化;
CubeSLAM主要贡献:
- 对于单图像对象检测,从二维(2D)边界框和消失点采样生成高质量的长方体建议,根据与图像边缘的对齐情况对提案进行进一步评分和选择;
- 提出了新object测量的多视图BA,以联合优化cameras,objects和points的位姿,Object可以提供远程几何和尺度约束,以改善相机位姿估计并减少单目漂移;

Related Work
A. Single Image 3-D Object Detection
与2D相比,从单张图片中进行3D物体检测更加有挑战,因为需要 考虑更多的object的位姿变量和相机投影几何;现有的3D检测可以分为两类:有形状先验(如CAD)和没有形状先验的;
- With prior models:与 RGB 图像对齐的best object pose可以通过关键点透视-n 点 (PnP) 匹配 [7]、手工制作的纹理特征 [8] 或更近期的深度网络 [3]、[9] 找到;
- Without prior models:物体通常用长方体表示,典型的方法是将几何建模与学习相结合;例如,可以通过 VPs [10]、[11] 组合Manhattan edges或射线(rays)来生成objects; [12]建议在地面上对许多 3-Dboundingbox进行详尽的采样,然后根据各种上下文特征进行选择;与我们类似的两个工作是 [13] 和 [14],它们使用射影几何来寻找长方体以紧密地拟合 2-D 边界框;作者将其扩展在无需预测object大小和方向的情况下工作。
B. Multiview Object SLAM
Object-augmented mapping主要有两种:
- 解耦( decoupled):该方法首先构建 SLAM 点云图,然后基于点云聚类和语义信息 [16]-[18] 进一步检测和优化 3-D object poses;与二维物体检测相比,它显示出改进的结果,但它并没有改变 SLAM 部分;因此,如果 SLAM 无法构建高质量地图,解耦方法可能会失败;
- 耦合(coupled)该方法也叫做object-level SLAM; [19]提出了第一个语义 SfM 来联合优化相机位姿、物体、点和平面;SLAM++[20]使用 RGBD 相机和先验的object model;和[22]相似,[21]将物体表示为球体以纠正单目 SLAM 的尺度漂移;[23]中提出了一种使用先验object model的实时单目object SLAM;24] 分析解决了多视图 3-D 椭球对象定位问题,QuadriSLAM [25] 将其扩展到没有先验模型的在线 SLAM,对象 SLAM 的不确定数据关联在 [26] 中得到解决;[27] 提出了一个类似的想法,将场景理解与 SLAM 结合起来,但仅适用于平面;
最近有一些基于end-to-end深度学习没有object表示的SLAM,例如DVSO[28]和DeepVO [29],其在 KITTI 数据集上取得了很好的表现,但是还不清楚能否推广到新的环境。
C. Dynamic Environment SLAM
大多数现有的方法[4], [30], [31]将动态区域特征视为outliers,and only utilize static background for pose estimation;最近有一项工作[34]基于刚性形状和恒定运动假设 ,利用动态点 BA 来改进相机位姿估计,但是该论文显示了有限的真实数据集结果,并且没有明确表示地图中的object;
Methods
SINGLE IMAGE 3-D OBJECT DETECTION
A. 3-D Box Proposal Generation
-
Principles:作者利用2D boundingbox生成3D cuboid提案;正常一个3D cuboid可以用9 Dof参数表示:3 DoF position t = [,ty,tz],3 DoF rotation R和3 DoF dimension d = [dx, dy,dz];cuboid的坐标系建立在cuboid中心,与主轴对齐;K代表相机内参且已知;基于长方体的投影角(cuboid’s projected corners )应该紧密贴合 2-D 边界框的假设,只有 4 个约束对应于 2-D 框的四个边,不可能完全约束所有九个参数,所以需要其他信息;例如,在许多车辆检测算法 [12]-[14] 中使用的提供或预测的对象尺寸和方向(信息先验);这里作者不依赖于预测的维度,而是利用 VP 来改变和减少回归参数,以便适用于一般object(这里指生成提案然后筛选的方式);
VP 是投影到透视图像 [35] 后平行线的交点,一个 3-D 长方体具有三个正交轴,并且可以在投影后形成三个 VPs,具体取决于对象旋转 R wrt 相机框架和相机内参矩阵K:
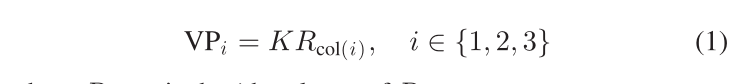
其中Rcol(i)是 R 的第 i 列;
- Get 2-D Corners From the VP:这部分说明如何基于 VP 获得八个二维长方体角(2-D cuboid corners);由于最多可以同时观察三个长方体面,可以根据图 2 所示的可观察面的数量将长方体配置分为三个常见类别;

? 这里更详细地解释图 2(a),假设三个 VPs和顶角p1是已知的或估计的,× 表示两条线的交点,所以p2 = (VP1, p1) × (B, C), 同理,对于p4. p3 = (VP1, p4) × (VP2, p2), p5 = (VP3, p3) × (C, D);类似的可以得到其他角点;
- Get 3-D Box Pose From 2-D Corners:在得到 2-D 图像空间中的长方体角点后,需要估计cuboid’s 3-D corners和pose;作者将objects分为两种场景:
- 任意位姿物体(Arbitrary pose objects):于单目尺度模糊性,我们使用 PnP 求解器来求解一般长方体的 3-D 位置和尺寸,直至达到比例因子。在数学上,长方体在对象框架中的八个 3-D 角是 [±dx, ±dy , ±dz ] /2,在相机框架中是 R [±dx, ±dy , ±dz ] /2 + t。如图2(a)所示,我们可以选择四个相邻的角,例如1、2、4、7,可以从上述3-D角投影出来;例如;角落 1:
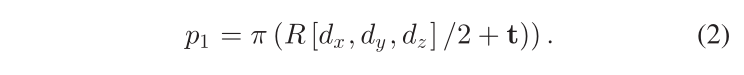
π 是相机投影函数,pi (i = 1, 2, . . . , 8) 是八个二维对象角之一。每个角提供两个约束,因此四个角可以完全约束除尺度之外的对象姿态(9 Dof),迭代或非迭代 PnP 求解器可以在 [35] 中找到;
- 地面物体(Ground objects):对于位于地平面上的物体,我们可以进一步简化上述过程,更容易得到比例因子。我们在地平面上构建世界框架,然后物体的滚动/俯仰角为零。与上一节类似,我们可以从 VP 获得八个二维角。然后代替使用(2)中复杂的 PnP 求解器,我们可以直接将地角像素反向投影到 3D 地平面,然后计算其他垂直角以形成 3-D 长方体。这种方法非常有效并且具有解析表达式。例如,对于由 [n, m] 表示的 3-D 地平面上的角点 5(相机帧中的法线和距离),对应的 3-D 角点 P5 是反投影光线 K-1p5 与地平面的交点:
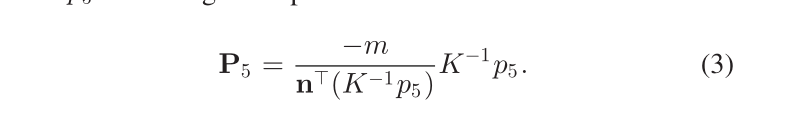
类似地,[27] 中解释了更详细的投影过程,比例由投影过程中的相机高度决定;
4.Sample VP and Summary:从前两节的分析来看,盒子估计问题变成了如何得到三个 VP 和一个 top 2-D corner,因为在得到 VP 之后,我们可以使用 Section III-A2 来计算 2-D corners,那么使用 Section III-A3 计算 3-D 框。由(1)式可知,VP 由对象旋转矩阵 R 决定。虽然深度网络可以通过大量数据训练直接预测它们,但作者选择手动对其进行采样,然后对它们进行评分(排名)以达到泛化的目的;对于一般物体,我们需要对完整的旋转矩阵 R 进行采样,但是对于地面物体,使用相机的 roll/pitch 和物体的 yaw 进行采样来计算 R,更重要的是,在 SUN RGBD 或 KITTI 等数据集中,相机滚动/pitch 已经提供;对于多视图视频数据,作者使用 SLAM 来估计相机位姿,因此采样空间大大减少,也变得更加准确;在本文的实验中,作者只考虑地面物体。
B. Proposal Scoring
OBJECT SLAM
作者将 single image 3-D object detection应用到multiview object SLAM用于jointly optimize object pose and camera pose;CubeSLAM整个系统建立在ORB-SLAM上,主要修改的是在BA中包含 objects、points和camera pose一起;
A. BA Formulation
作者将一组camera poses、3-D cuboids和points表示为 C = {Ci}, O = {Oj }, P = {Pk},则 BA 可以表示为非线性最小二乘优化问题
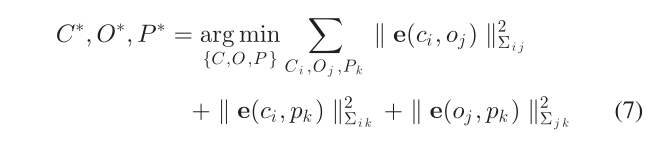
其中e(c, o)、e(c, p)和e(o, p)分别表示相机物体、相机点、物体点的测量误差;Σ 是不同误差测量的协方差矩阵;
B. Measurement Errors
-
Camera-Object Measurement:作者提出了两种物体和相机之间的测量误差;
- 3-D Measurements:
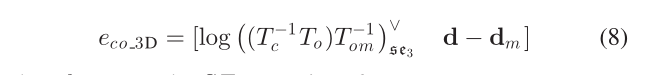
- 2-D Measurements:

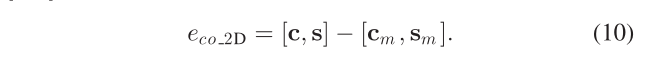
-
Object-Point Measurement:Points and objects can provide constraints for each other;如果点 P 属于图 4(b)中所示的object,它应该位于 3-D cuboid内部,所以首先将点转换为长方体框架,然后与长方体尺寸进行比较以获得 3-D 误差:
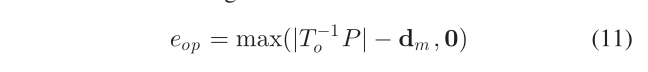
使用 max 运算符是因为作者只鼓励点位于长方体内部,而不是恰好位于曲面上;
-
amera-Point Measurement:这里使用基于特征的 SLAM [4] 中使用标准的 3-D 点重投影误差:
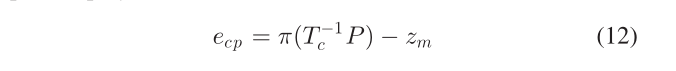
其中 zm 是 3-D 点 P 的观察到的像素坐标;
C. Data Association
Data association across frames 是SLAM另一个重要部分;与点匹配相比,object association因为包含更多纹理并且可以使用许多二维对象跟踪或模板匹配方法显得更加容易,即使是 2-D 框重叠也可以在一些简单的场景中工作;然而,如果重复对象存在严重的对象遮挡,这些方法并不鲁棒,如图 5 所示;此外,需要检测动态对象并将其从当前的 SLAM 优化中移除,但标准的object tracking 方法无法分类是否为静态对象与否,除非使用特定的运动分割;

作者提出另一种基于特征点匹配的object association method,如果在 2-D object
bounding box 中观察到点至少两帧并且它们到 cuboid 中心的 3-D 距离小于 1 m,作者首先将特征点与其对应的object相关联;Note:在(11)中计算 BA 中的 object-point measurement erro也使用此object-point association ;最后,如果两个objects在彼此之间具有最多的共享特征点并且数量也超过某个阈值(在作者的实现中为 10),将匹配不同帧中的两个objects;通过作者的实验,这种方法适用于宽基线匹配、重复对象和遮挡;属于运动物体的object,例如图 5 中的前青色汽车。(被抛弃的object会不会还生成3D boundingbox?会的因为作者的方法是单帧生成)
DYNAMIC SLAM
上一节涉及 static object SLAM SLAM,在本节中,作者提出了一种联合估计相机位姿和动态物体轨迹的方法;作者的方法对物体进行了一些假设,以减少未知数并使问题可解决,两个常用的假设是物体是刚性的并且遵循一些物理上可行的运动模型,刚体假设表明点在其关联对象上的位置不会随着时间而改变。这使能够利用标准的 3-D 地图点重投影误差来优化其位置;对于运动模型,最简单的形式是匀速恒定运动模型。对于某些特定物体,例如车辆,它还受到非完整车轮模型的额外约束(带有一些侧滑)。
A. Notations
这里新定义了一些地图元素;
B. SLAM Optimization
动态对象估计的因子图如图6所示。蓝色节点是静态SLAM组件,而红色节点代表动态对象、点和运动速度。绿色方块是测量因子,包括(10)中的相机-物体因子、(14)中的物体-速度因子和(15)中的点-相机-物体因子,下面将进行解释。有了这些因素,相机位姿也可以受到动态元素的限制。

-
Object Motion Model:一般的 3-D 物体运动可以用一个位姿变换矩阵 T ∈ SE(3) 来表示;我们可以将 T 应用于先前的位姿,然后用当前位姿计算位姿误差。在这里,我们采用了更受限制的非完整车轮模型 [39],该模型也用于其他动态车辆跟踪工作 [14]。汽车运动由线速度 v 和转向角 φ 表示。假设车辆大致在局部平面上移动,则物体roll/pitch = 0,z轴平移tz = 0。只需要tx,ty,θ(航向偏航)来表示其完整状态To = [R(θ ) [tx, ty , 0]?]。从速度预测的状态是:
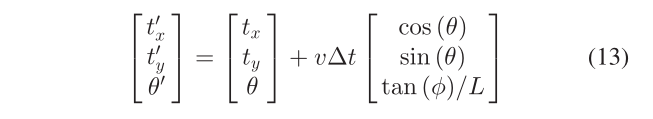
其中 L 是前后轮中心之间的距离。请注意,此模型要求 x、y、θ 定义在后轮中心,而我们的对象框架定义在车辆中心。两个坐标系有 L/2 的偏移量,需要补偿。最终的运动模型误差如下
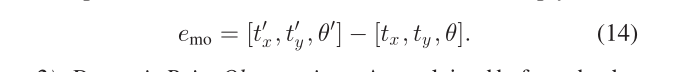
- Dynamic Point Observation:如前所述,动态点锚定到其关联对象,因此首先将其转换为世界框架,然后投影到相机上。假设第 i 个对象上第 k 个点的局部位置为 iP k,第 j 个图像中的对象位姿为 j T io ,则该点的重投影误差为:
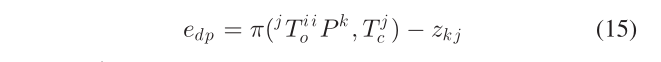
其中 T jc 是第 j 个相机位姿,zkj 是该点的观察像素
C. Dynamic Data Association
通过实验,我们发现第IV-C节中的静态环境关联方法由于难以匹配动态点特征而不适用于动态情况。跟踪特征点的典型方法是预测其投影位置,搜索与描述符匹配的附近特征,然后检查对极几何约束 [4]。然而,对于单目动态情况,难以准确预测物体和点的运动,当物体运动不准确时,极线几何也不准确。
因此,我们为点和对象关联设计了不同的方法。特征点直接通过2-D KLT稀疏光流算法跟踪,不需要3-D点位置。在像素跟踪之后,动态特征的 3-D 位置将考虑到对象的移动进行三角测量。在数学上,假设两帧的投影矩阵是 M1 和 M2。这两帧中的 3-D 点位置是 P1,P2,对应的像素观测值是 z1,z2。两帧之间的物体运动变换矩阵为ΔT,那么我们可以推断出P2 = ΔT P1。基于投影规则,我们有:
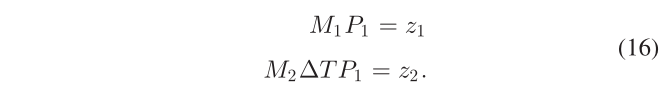
如果我们将 M2ΔT 视为修正的相机位姿补偿对象运动,则上述方程是标准的两视图三角剖分问题 [35],可以通过 SVD 解决
当像素位移较大时,KLT 跟踪可能仍会失败,例如,当另一辆车靠近并靠近摄像头时。因此,对于动态对象跟踪,我们不使用第 IV -C 节中的共享特征点匹配方法。相反,我们直接利用视觉对象跟踪算法[40]。跟踪对象的二维边界框,并从前一帧预测其位置,然后将其与当前帧中检测到的具有最大重叠率的边界框进行匹配。
IMPLEMENTATIONS
A. Object Detection
2-D object detection:在室内场景中使用YOLO detector [41],概率阈值为 0.25;在户外 KITTI 上使用MS-CNN [42],概率是0.5;两者都是实时在GPU上运行的;
在已知accurate camera pose下(如SUN RGBD dataset):只需要采样对象偏航来计算 VPs,如第 III-A4 节所述;如第 IV -B1 节所述,将 90° 范围内的 15 个对象偏航样本生成为可以旋转的长方体,然后在二维边界框的顶部边缘采样十个点;请注意,并非所有样本都可以形成有效的长方体提议,因为一些长方体角可能位于二维框之外;
在没有ground truth camera pose provided下:需要在最初估计的角度周围的 ±20° 范围内对相机滚动/俯仰进行采样;对于没有先验信息的单个图像,作者简单地估计相机与地面平行,对于多视图场景,SLAM 用于估计相机位姿;作者的方法的一个优点是它不需要大量的训练数据,因为只需要调整 (4) 中的两个成本权重,它还可以实时运行,包括二维物体检测和边缘检测;
B. Object SLAM
整个 SLAM 算法的流程如图 4(a) 所示,Cube-SLAM系统建立在ORB-SLAM2的基础上,并且没有修改the camera tracking 和keyframe creation modules;对于新创建的关键帧,Cube-SLAM检测长方体物体,将它们关联,然后使用相机姿势和点执行 BA;对于动态物体,Cube-SLAM可以根据不同的任务选择重构或忽略它们;当立体基线或视差角小于阈值时,长方体还用于初始化难以三角测量的特征点的深度;如实验所示,这可以提高某些具有挑战性的场景中的鲁棒性,例如大相机旋转;由于对象的数量远少于点,对象关联和BA优化实时高效运行;为了获得单目 SLAM 的绝对地图比例,提供初始帧的相机高度来缩放地图;请注意,Cube-SLAM也可以在没有点的情况下独立工作,在一些特征点较少的具有挑战性的环境中,ORB SLAM 无法工作,但我Cube-SLAM仍然可以仅使用物体-相机测量来估计相机位姿;
优化中有不同的成本(见第四节),其中一些在像素空间,例如(10),而一些在欧几里德空间,例如(8)和(11),因此有必要调整它们之间的权重。由于难以分析长方体检测不确定性,作者主要通过检查测量的数量和幅度来手动调整物体成本权重,以便不同类型的测量贡献大致相同;例如,与点相比,只有少数对象,但它们在(10)中的重投影误差与点相比要大得多。根据我们的实验,物体相机和点相机测量具有相似的权重;
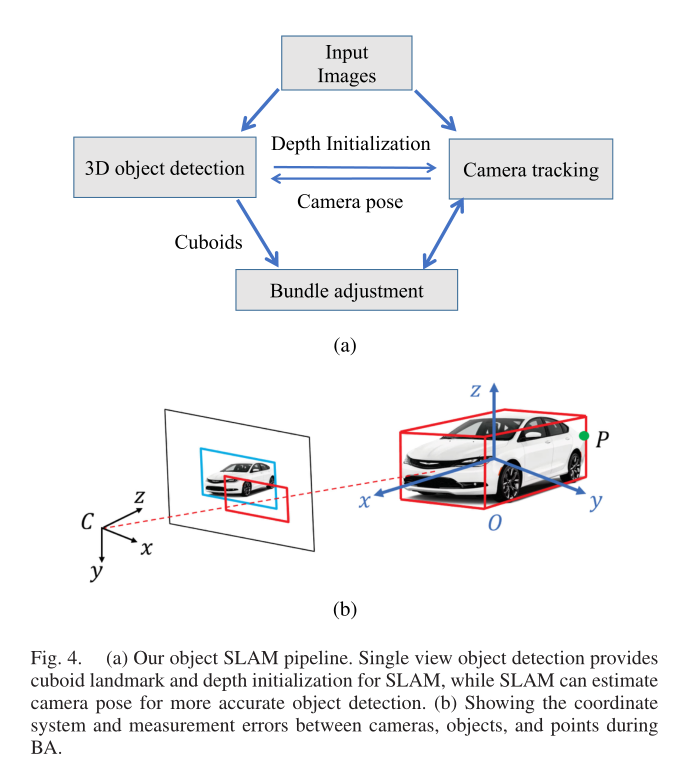
C. Dynamic Object
Dynamic objects的部署大都沿用上一节,只有以下几点不同:恒定运动模型假设可能不适用于实际数据集,因为对象可能会加速和减速(例如在图 13 中);通过ground truth object velocity分析,作者发现速度在大约 5 秒内大致保持不变;因此,在CubeSLAM 中,运动模型约束仅适用于最后 5 秒的观察结果。

Experiment
Cube-SLAM的实验分为两个部分,单图像3D目标检测和整体SLAM精度评测;单图像3D目标检测实验,作者使用了SUN RGBD(室内) 和 KITTI(室外);SLAM精度实验在TUM(室内)和KITTI(室外)上进行;综合效果上来看, Cube-SLAM在 SUN RGBD 子数据集达到了3D目标检测的最高精度,并且 在KITTI odometry datasets上实现了相机位姿估计的最高精度;
EXPERIMENTS―SINGLE VIEW DETECTION
SUN RGBD [43] and KITTI object [44] data两个数据集提供 3-D bounding box 注释以供做单图像物体检测评估;3-D intersection over union (IoU)和average precision (AP)作为评估指标,而不是很多work中使用仅旋转或视点评估;由于没有深度数据,因此作者将正确检测的 3-D IoU 阈值调整为 25% [12]、[43];因为Cube-SLAM不依赖先验的物体模型,为了获得物体位置和尺寸的绝对比例,作者只能评估已知相机高度的地面物体,如第 III-A 节所述;KITTI 数据集,这个假设已经满足;使用了常用的由[2]、[13]分割的训练和验证指标;对于 SUN RGBD 数据集,作者选择了 1670 张具有可见地平面和完全在视野中的地面物体的图像。
A. Proposal Recall
首先,作者评估了SUN RGBD 数据集下生成提案的质量,很明显,如果 2-D 边界框不准确, 3-D 长方体精度也会受到影响;通过评估 2-D IoU 大于阈值 τ 的物体的 3-D 召回来分析这种效果,如图 7(a) 所示;正如预期的那样,更大的 τ 会导致更高的 3-D 召回率,当 2-D IoU 为 0.6 时,作者的方法可以使用大约 50 个长方体提案实现 90% 的 3-D 召回率;
然后,作者在 KITTI 数据集上评估和比较提案质量,如图 7(b)所示;由于与CubeSLAM相比,Mono3D [12] 和 3DoP [45] 使用不同的验证指标,作者只评估常见图像 (1848);根据测试,不同的图像索引只会导致小的结果变化,其他算法的结果取自他们的论文;请注意,Mono3D 首先对大量长方体提案(~14 k)进行详尽的采样,然后在根据语义和实例分割对最佳提案进行评分和选择后报告召回率;因此,作者还评估了评分前后的召回率。在评分之前(绿线),Cube-SLAM的方法可以达到 90% 的召回率,每张图像有 800 个原始提案,大约 每个物体有200 个提案;评分后(红线),作者只需使用 20 个提案就可以达到相同的召回率,与 [12] 相比要少得多;这有两个主要原因。首先,作者的 3-D 提议是高质量的,因为它们保证与 2-D 检测框相匹配;其次,作者有更有效的评分功能;请注意,作者的方法有一个上限,如图 7(b)所示,因为 2-D 检测器可能会遗漏一些对象;

B. Final Detection
然后,作者评估最佳选择提案的最终准确性;据作者所知,SUN RGBD 中没有经过训练的 3-D 检测算法,因此,作者比较了两种公共方法,UN primitive [10] 和 3-D Geometric Phrases (3DGP) [46],,它们都是像Cube-SLAM这样的基于模型的算法;此外,3DGP 使用固定的先验物体模型,作者修改他们的代码以在检测和不投影到 3-D 空间时使用实际的相机位姿和校准矩阵。
对于 3-D IoU 评估,为了消除 2-D 检测器的影响,作者仅对 2-D 矩形 IoU > 0.7 的对象评估 3-D IoU;如表 I 和图 8 所示,作者的方法可以生成更多准确的长方体,其他方法 [10]、[46] 只能在 SUN RGBD 子集数据集中检测到大约 200 个长方体,而作者的算法检测到十倍以上;与使用先验模型的 3DGP 相比,作者的平均 3-D object IoU 更小,但如果仅通过 3DGP 对相同检测到的图像(≈200)进行评估,则更高,与 AP 类似,作者仅在检测到 3-D 物体的图像上评估其他方法,否则与作者在整个数据集上的 27% 相比,它们的 AP 值将非常低(<5%)。

在KITTI dataset上,作者与使用深度网络的其他单目算法 [2]、[12]、[13] 进行比较,SubCNN 还使用先验的模型;预测结果由他们的作者提供;AP是在中等大小汽车类上评估的;从表 I 中,Cube-SLAM的表现类似于 SubCNN 和 Mono3D;由于 SubCNN 产生许多误报检测,它们的 AP 值很低,表现最好的方法是 Deep3D [13],它使用深度网络直接预测车辆的方向和尺寸,由于只有一个物体类别“汽车”具有固定的相机姿势和对象形状,因此 CNN 预测比CubeSLAM手工设计的特征效果更好,最后一行是对作者选择的前十个长方体提案的评估,以表明Cube-SLAM的提案生成部分仍然可以生成高质量的提案;
EXPERIMENTS―OBJECT SLAM
评估指标:camera pose estimation和3-D object IoU;对于camera pose使用的参数是均方根误差 (Root mean squared error RMSE) [47] 和 KITTI 平移误差(KITTI translation error) [44]; 作者从第一帧的相机高度获得了地图比例,所以直接评估绝对轨迹误差(我觉得这里的原因就是使用绝对轨迹误差能更好的凸显尺度优化的效果);为了更好地评估单目姿态漂移,关闭了 ORB SLAM2中的回环模块;
A. TUM RGBD and ICL-NUIM Dataset
[47]、[48] 数据集具有用于评估的ground truth camera pose trajectory,作者仅将 RGB 图像用于 SLAM 算法,对于object的ground truth,3-D 长方体在深度图像的注册全局点云中手动标记。

TUM fr3_cabinet数据集上(如图9所示): 这是一个低纹理数据集,现有的单目 SLAM 算法都因点特征少而失败;object是唯一的 SLAM landmark,使用第 IV 节 -B1 中的 3-D 物体-相机测量,因为它可以提供比 2-D 测量更多的约束;图 9 的左侧显示了作者使用来自 SLAM 的估计相机位姿在某些帧中在线检测到的长方体,底部图像明显存在较大的检测误差,经过多视图优化后,地图中的红色立方体几乎与地面实况点云匹配;从表 II 中的“fr3/cabinet”行来看,与单图像长方体检测相比,SLAM 优化后的 3-D objectIoU 从 0.46 提高到 0.64。绝对相机位姿误差为 0.17 m;
ICL-NUIM Dataset上:这是一个通用的功能丰富的场景,由于单目 DSO 或 ORB SLAM 没有绝对尺度,作者在尺度对齐后计算它们的位姿误差 [15];Cube-SLAM提高了对象检测精度,同时由于不完美的对象测量而牺牲了一些相机位姿精度;从图 1(a) 中 ICL 数据的映射结果可以看出,作者的方法能够检测不同的物体,包括沙发、椅子和盆栽植物,展示了CUbe-SLAM在没有先验模型的情况下进行 3-D 检测的优势;
B. Collected Chair Dataset
该部分是作者使用Kinect RGBD 相机收集两个椅子数据集,如图 10 所示,RGBD版本的ORB SLAM 结果用作相机位姿的 ground truth,第二个数据集包含大的相机旋转,这对于大多数单目 SLAM 来说是具有挑战性的;如图 10(a) 所示,优化后的长方体可以紧密拟合相关的 3-D 点,表明object和点估计相互受益;定量误差显示在表 II 的底部两行,DSO 能够在第一个数据集中工作,但在第二个数据集中表现不佳,因为相机旋转较大,Mono ORB SLAM 在这两种情况下都无法初始化,而Cube-SLAM的长方体检测甚至可以为单个图像中的点提供深度初始化,与之前类似,BA 后 3-D object IoU 也得到了改进;

C. KITTI Dataset
作者在两个KITTI数据集上进行了测试,一个短的序列提供了object注释的groundtruth,另一个长的数据集是一个标准的odometry benchmark没有提供object注释;第 IV -B1 节中的 2-D 物体相机测量用于 BA,因为与用于车辆检测的 3-D 测量相比,它的不确定性较低;作者还通过第一帧相机高度(在作者的实现中为 1.7 m)缩放 ORB SLAM 的初始地图,以评估其绝对位姿误差;在图 11 中,可以观察到第一次转弯之前的初始轨迹段与地面实况很好地匹配,表明 ORB 的初始地图缩放是正确的,对于 KITTI 数据集,作者额外使用先前的汽车尺寸(在我们的实现中 w = 3.9,l = 1.6,h = 1.5)初始化对象尺寸以保持长期规模一致性,这也用于其他object SLAM 工作 [21], [22],当在某些序列中不经常观察object时,这非常有用;
-
KITTI Raw Sequence:作者选了10 个具有最多ground truth object anno-
tations的 KITTI 原始序列,命名为“2011_0926_00xx”;相机的groundtruth由GPS/INS poses提供;对于object IoU,作者比较了三种方法,第一个是单图像长方体检测 [13],第二个是仅使用帧之间的 SLAM 数据关联的物体姿态,第三个是最终的 BA 优化后的object pose;如表III的前三行所示,在大多数序列中,经过数据关联和BA优化后,目标准确率有所提高,但在某些序列中,由于局部位置漂移,目标IoU也可能有所下降。对于相机位姿估计,物体 SLAM 可以提供几何约束以减少单目 SLAM 的尺度漂移,请注意,由于大多数 KITTI 原始序列没有循环,因此禁用或启用 ORB SLAM 循环闭合模块不会产生影响;
-
KITTI Odometry Benchmark:作者没有与 ORB SLAM 进行比较,因为没有闭环,它无法在长序列中恢复尺度并且具有显着的漂移误差,如图 11 所示;如表 IV 所示,作者的objectSLAM 实现了 2.74% 的translation error,并且比其他使用object的 SLAM 表现得更好,这是因为它们将车辆表示为球体或仅使用车辆高度信息,而不如作者的长方体 BA准确;作者的算法也与基于地面的缩放方法相当,一些object mapping 和 pose estimation的可视化显示在如图 1(b)和 11 所示,可以看到作者的方法大大减少了单目尺度漂移;
Cube-SLAM 在某些序列中表现更差,例如 Seq 02、06、10,主要是因为远距离可见的object不多,导致大规模漂移,因此,作者还提出了一种将地面高度假设与Cube-SLAM相结合的简单方法;如果在最近的 20 帧中没有可见的物体,Cube-SLAM从点云拟合一个地平面,然后根据恒定的地面高度假设缩放相机姿势和局部地图;如表 IV 所示,第四行“ground based/Ours”代表 ORB SLAM,仅使用作者简单的地面缩放且没有物体,以 3.39% 的平移误差实现了良好的性能;“Combined”行将地面缩放与物体相结合,进一步将误差降低到 1.78%,并在 KITTI 基准上达到了单目 SLAM 的最新精度;注意,基于地平面的方法也有其局限性,例如,它们不适用于飞行器或手持摄像机;当地面不可见时,它们也会失败,例如 KITTI 07 的图 5 中的框架;前部动态汽车长时间遮挡地面,因此许多基于地面的方法在 KITTI 07 上失败或表现不佳。


D. Dynamic Object
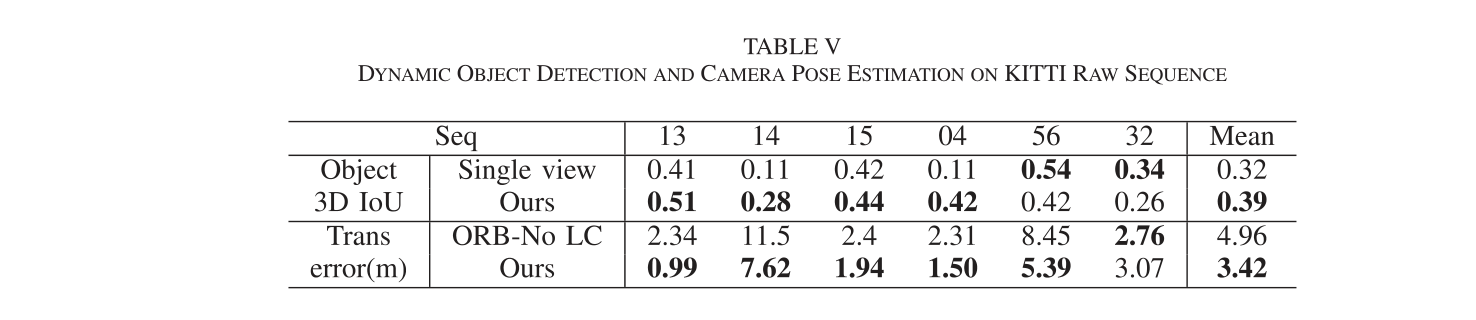
动态场景情况下在图12(a)中的KITTI datasets;作者选择了一些长时间多dynamic objects的raw sequences,数据如表5;序列的全名是“2011_0926_00xx”,前四个序列也对应于 KITTI tracking dataset中的 Seq 3、4、5、18,这些序列中的大多数汽车都在移动,Ground truth object annotations可用于所有或部分帧,ground truth camera poses由 GPS/INS 提供;

- Qualitative Results:一些单图像检测示例如图 12(a) 所示,图 12(b) 显示了图 12(a) 的第一幅图像的俯视图;对于两辆较远的前车,虽然2-D图像长方体检测看起来不错,但实际上3-D距离误差很大,这是因为只有汽车的背面是可观察的,从而导致了单张图像检测的不良约束,在多视图动态对象 BA 之后,蓝色优化对象与地面实况匹配得更好,主要是由于运动模型约束,但是,它有时会降低精度,例如图中的底部object;一些可能的原因是由于嘈杂的 2-D 和 3-D object检测,特别是对于近距离的object,当车辆加速或减速时,恒定运动假设也可能导致错误;图 12(c)显示了所有动态object的历史位姿以及相机姿势,由于运动模型的约束,物体的轨迹是平滑的;图 13 显示了对 Seq 0047 数据中一个物体的速度估计,可以看到计算的地面真实物体速度也随时间变化,因此,第 VI-C 节中解释的分段恒速运动是合理的,使用单目相机,所提出的算法可以粗略估计物体的绝对速度;
- Quantitative Results:由于目前没有利用动态object来改变相机姿态估计的单目 SLAM,因此作者直接与基于状态特征的 ORB SLAM 进行比较,虽然它已经有一些模块可以根据重投影误差将动态点检测为异常值,但为了公平地与 ORB SLAM 进行比较,作者直接移除位于动态对象区域的特征并报告其姿态估计结果;从表 V 中,可以看到我们的方法可以改进大多数序列的相机姿态估计,特别是当可以在许多连续帧上观察和跟踪对象时,例如在前四个数据集中,这是因为通过更多的观察,可以更准确地估计物体的速度和动态点的位置,从而对相机位姿估计产生更大的影响,而在最后两个序列中,物体通常只被几帧观察到;作者还将 3-D 对象定位与表 VI 中所示的其他单目方法进行了比较,与Cube-SLAM最相似的是[32],它利用语义和几何成本来优化对象位置,但他们的方法假设相机pose已经解决和修复,作者利用 [32] 中的相同度量来测量每帧中的相对对象深度误差,并且该数字直接取自论文,从表中可以看出,作者的方法在大多数序列上都优于其他方法,在序列56中,相对深度误差仅为0.8%。


E. Time Analysis
测试电脑: Intel i7-4790 CPU at 4.0 GHz;2D object detection 时间取决于 GPU 能力和 CNN 模型复杂度,很多算法(例如Yolo)可以实时;得到 2-Dboundingbox后,3-D cuboid detection每张图像大约需要 20 毫秒,它的主要计算是边缘检测;表VII 中显示了时间使用情况;计算强烈依赖于具有不同图像大小和纹理的数据集,作者选择两个代表性序列:Outdoor KITTI 07 at 10 Hz shown in Fig. 1(b) and indoor ICL-NUIM livingroom dataset at 30 Hz shown in Fig. 1(a);平均两个数据集中的每个local BA optimization中都有五个 object landmarks;The tracking thread包括ORB点特征检测和每帧的相机位姿跟踪,可以从表中实时运行;BA 地图优化发生在创建新的关键帧时,因此它不需要实时运行;在静态环境中,将object添加到系统中只会增加 7% 的优化,这是合理的,因为局部地图优化中只有少数object;对于动态场景的情况,由于许多新变量和动态点的测量,计算量增加了两倍;

Conclusion
总结(其他点):
- 提出了 new object association methods来稳健地处理遮挡和动态运动;
- Objects can provide long range geometric and scale constraints for camera pose estimation;我觉得这里的long是指长时间的尺度和几何约束;
- 对于动态场景,作者还展示了在新的测量约束条件下,运动对象和点也可以通过紧耦合优化改进相机位姿估计;
未来工作:使用Objects的稠密建图,更加完整的场景理解和SLAM优化相结合;object作为landmarks如何从初始化、tracking、重定位、优化和回环上发挥作用。

