该博客配套代码、数据及PPT见百度网盘
链接:https://pan.baidu.com/s/1j1iWnhXmQiAnQ7VnfsCIrQ?
提取码:6666
算法实战
数据为31个省份的出生率和死亡率,文件名为Province.xlsx

在密度聚类算法的实战部分,我们将使用国内31个省份的人口出生率和死亡率数据作为分析对象。首先,将数据读入到Python中,并绘制出生率和死亡率数据的散点图,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 读取外部数据
Province = pd.read_excel(r'D:\myPythonFiles\python数据分析\TextbookCode\密度聚类\Province.xlsx')
Province.head() # 显示表格的前五行
# 绘制出生率与死亡率散点图
plt.scatter(Province.Birth_Rate, Province.Death_Rate) # Birth_Rate作为x Death_Rate作为y
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show() ?如上图所示,31个点分别代表了各省份人口的出生率和死亡率,通过肉眼,就能够快速地发现三个簇,即图中的红色椭圆(这是通过截图后面添加的椭圆),其他不在圈内的点可能就是异常点了。接下来利用密度聚类对该数据集进行验证,代码如下:
?如上图所示,31个点分别代表了各省份人口的出生率和死亡率,通过肉眼,就能够快速地发现三个簇,即图中的红色椭圆(这是通过截图后面添加的椭圆),其他不在圈内的点可能就是异常点了。接下来利用密度聚类对该数据集进行验证,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing # 用于变量的标准化处理
from sklearn import cluster
import numpy as np
# 选取建模的变量
predictors = ['Birth_Rate', 'Death_Rate']
# 变量的标准化处理
X = preprocessing.scale(Province[predictors])
X = pd.DataFrame(X)
# 构建空列表,用于保存不同参数组合下的结果
res = []
# 迭代不同的eps值
for eps in np.arange(0.001, 1, 0.05):
# 迭代不同的min_samples值
for min_samples in range(2, 10):
dbscan = cluster.DBSCAN(eps=eps, min_samples=min_samples)
# 模型拟合
dbscan.fit(X)
# 统计各参数组合下的聚类个数(-1表示异常点)
n_clusters = len([i for i in set(dbscan.labels_) if i != -1])
# 异常点的个数
outlines = np.sum(np.where(dbscan.labels_ == -1, 1, 0))
# 统计每个簇的样本个数
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)
res.append({'eps': eps, 'min_samples': min_samples, 'n_clusters': n_clusters, 'outlines': outlines, 'stats': stats})
# 将迭代后的结果存储到数据框中
df = pd.DataFrame(res)
# 根据条件筛选合理的参数组合
print(df.loc[df.n_clusters == 3, :])?我们通过把不同参数组合下的结果保存下来,寻找较为合理的聚类结果。
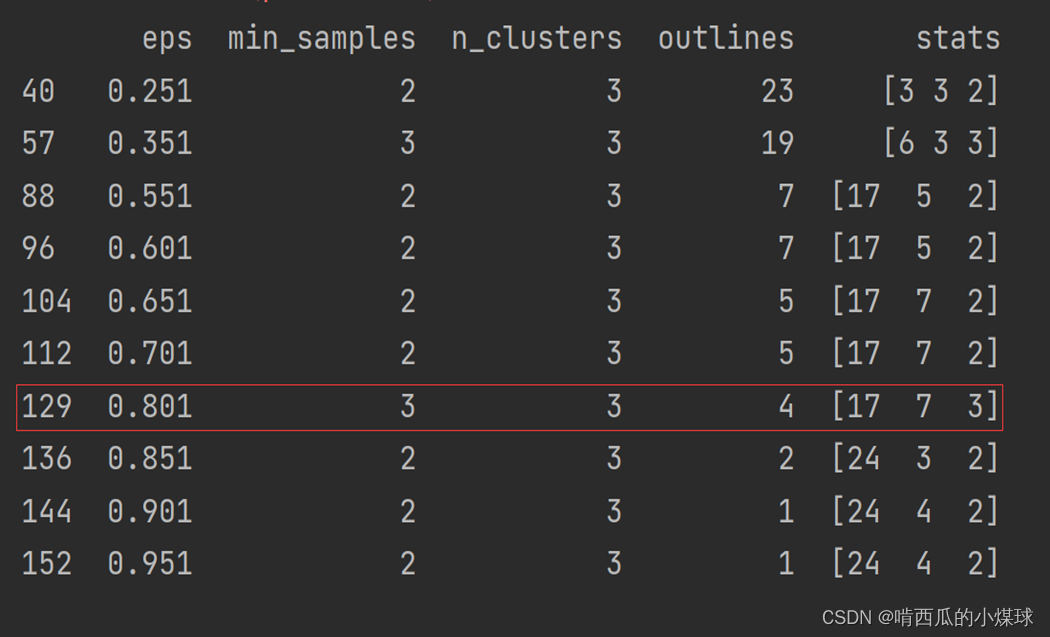
?如上表所示,如果需要将数据聚为3类,则得到如上几种参数组合,这里不妨选择eps为0.801,min_samples为3的参数值(因为该参数组合下的异常点个数比较合理)。接下来,利用如上所得的参数组合,构造密度聚类模型,实现原始数据集的聚类
该算法完整代码如下:
# 导入模块
# coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing # 用于变量的标准化处理
from sklearn import cluster
import numpy as np
import seaborn as sns # 用于绘制聚类的效果散点图
# 用于DataFrame显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 用于最后输出的图形汉字显示正常
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 读取外部数据
Province = pd.read_excel(r'D:\myPythonFiles\python数据分析\TextbookCode\密度聚类\Province.xlsx')
Province.head() # 显示表格的前五行
# 绘制出生率与死亡率散点图
plt.scatter(Province.Birth_Rate, Province.Death_Rate) # Birth_Rate作为x Death_Rate作为y
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
# plt.show()
# 选取建模的变量
predictors = ['Birth_Rate', 'Death_Rate']
# 变量的标准化处理
X = preprocessing.scale(Province[predictors])
X = pd.DataFrame(X)
# 构建空列表,用于保存不同参数组合下的结果
res = []
# 迭代不同的eps值
for eps in np.arange(0.001, 1, 0.05):
# 迭代不同的min_samples值
for min_samples in range(2, 10):
dbscan = cluster.DBSCAN(eps=eps, min_samples=min_samples)
# 模型拟合
dbscan.fit(X)
# 统计各参数组合下的聚类个数(-1表示异常点)
n_clusters = len([i for i in set(dbscan.labels_) if i != -1])
# 异常点的个数
outlines = np.sum(np.where(dbscan.labels_ == -1, 1, 0))
# 统计每个簇的样本个数
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)
res.append({'eps': eps, 'min_samples': min_samples, 'n_clusters': n_clusters, 'outlines': outlines, 'stats': stats})
# 将迭代后的结果存储到数据框中
df = pd.DataFrame(res)
# 根据条件筛选合理的参数组合
print(df.loc[df.n_clusters == 3, :])
# 利用上述的参数组合值,重建密度聚类算法
dbscan = cluster.DBSCAN(eps=0.801, min_samples=3)
# 模型拟合
dbscan.fit(X)
Province['dbscan_label'] = dbscan.labels_
# 绘制聚类的效果散点图 hue用于分类
sns.lmplot(x='Birth_Rate', y='Death_Rate', hue='dbscan_label', data=Province,
markers=['*', 'd', '^', 'o'], fit_reg=False, legend=False)
# 添加省份标签
for x, y, text in zip(Province.Birth_Rate, Province.Death_Rate, Province.Province):
plt.text(x+0.1, y-0.1, text, size=8)
# 添加参考线
plt.hlines(y=5.8, xmin=Province.Birth_Rate.min(), xmax=Province.Birth_Rate.max(),
linestyles='--', colors='red')
plt.vlines(x=10, ymin=Province.Death_Rate.min(), ymax=Province.Death_Rate.max(),
linestyles='--', colors='red')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
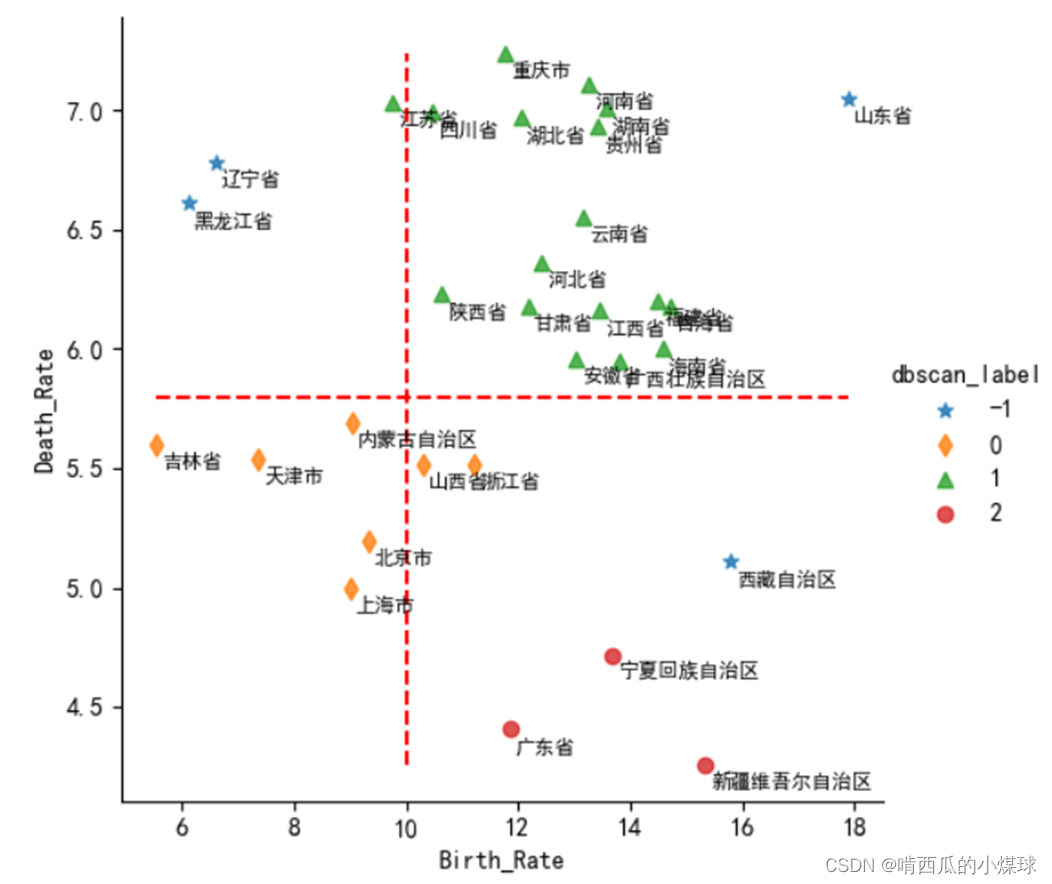
?如左图所示,三角形、菱形和圆形所代表的点即为三个不同的簇,五角星所代表的点即为异常点,这个聚类效果还是非常不错的,对比建模之前的结论非常吻合。从上图可知,以北京、天津、上海为代表的省份,属于低出生率和低死亡率类型;广东、宁夏和新疆三个省份属于高出生率和低死亡率类型;江苏、四川、湖北为代表的省份属于高出生率和高死亡率类型。四个异常点中,黑龙江与辽宁比较相似,属于低出生率和高死亡率类型;山东省属于极高出生率和高死亡率的省份;西藏属于高出生率和低死亡率的省份,但它与广东、宁夏和新疆更为相似。
代码中遇到的语法问题
一、for i?in set()来迭代遍历去除列表中的重复元素
n_clusters = len([i for i in set(dbscan.labels_) if i != -1]) 这句用来统计各参数组合下的聚类个数,对于for in i set() 的用法看下面的例子
list1 = [-1, 111, 111, 222, 777, 777, 333, 444, 555, 666]
for i in list1:
print(i)输出结果为: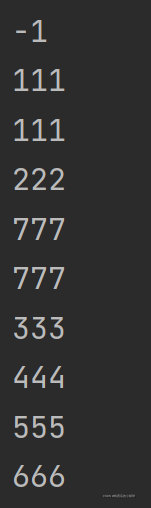
加上set()后
list1 = [-1, 111, 111, 222, 777, 777, 333, 444, 555, 666]
for i in set(list1):
print(i)?输出结果为: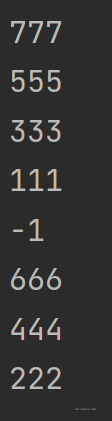 ,可以看出去除了重复元素,但是变得无序。
,可以看出去除了重复元素,但是变得无序。
那么我们就可以理解下面这个语句。
list1 = [-1, 111, 111, 222, 777, 777, 333, 444, 555, 666]
print(len([i for i in set(list1) if i != -1]))?这个语句用来打印出 list1 列表去除了重复元素和-1之后的长度,输出为7。
二、np.where的用法
outlines = np.sum(np.where(dbscan.labels_ == -1, 1, 0))上面这行代码用来统计不同参数组合下的异常点的个数。
np.where有两种用法
1.np.where(condition,x,y) 当where内有三个参数时,第一个参数表示条件,当条件成立时where方法返回x,当条件不成立时where返回y。
2.np.where(condition) 当where内只有一个参数时,那个参数表示条件,当条件成立时,where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式。
?
上面这行代码其实就是用法一,dbscan.labels_ == -1是判断条件,当聚类的标签为-1时返回1,否则返回0。最后用np.sum()函数求和就可以得到异常点的个数。
接着我们看下用法二的代码示例:
a = np.array([1, 3, 4, 6, 8, 9])
# 只有一个参数表示条件的时候
print(np.where(a > 5))
# 输出为(array([3, 4, 5], dtype=int64),)注意打印的是数组的下标,并非是数组的元素。
三、pd.Series()的用法
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)上面这句是用来统计不同参数组合下的每个簇的样本个数
在pandas里面常用value_counts确认数据出现的频率。看下面的一个例子
ss = pd.Series([-1, 0, 1, 2, 1, 0, 2, 0, 1, 1])
print(ss.value_counts())
print(ss.value_counts().index[0]) # 找频数最高的键输出结果为: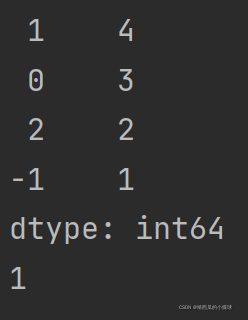
import pandas as pd
ss = pd.Series([-1, 0, 1, 2, 1, 0, 2, 0, 1, 1])
print(ss.value_counts())
print(ss.value_counts().values) 输出结果为: ,最后得到的是1,0,2,-1分别出现的次数的一个列表。
,最后得到的是1,0,2,-1分别出现的次数的一个列表。
import pandas as pd
labels = [-1, 0, 1, 2, 1, 0, 2, 0, 1, 1]
print(str(pd.Series([i for i in labels if i != -1]).value_counts().values))?输出结果为:

