Julia中的深度学习框架
目前新版的MATLAB已经自带深度学习工具箱, 入门教程可以参见本人博客Matlab深度学习上手初探. Python下较为流行的深度学习框架是PyTorch和Tensorflow, 其环境配置可以参考这里. Julia下目前有以下三种常见深度学习框架,其中点赞最多的是Flux,
Flux 是 100% 纯 Julia 堆栈,并在 Julia 的原生 GPU 和 自动差分 支持之上提供轻量级抽象。 它使简单的事情变得容易,同时保持完全可破解。
Flux is a 100% pure-Julia stack and provides lightweight abstractions on top of Julia’s native GPU and AD support. It makes the easy things easy while remaining fully hackable.
下面进行简单介绍.
Flux
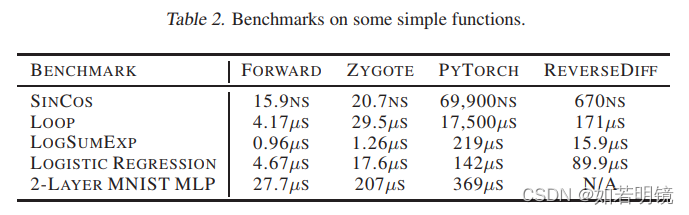
Flux使用Zygote进行自动差分,论文中给出的对比结果如下
Flux’s Model Zoo里面有常见模型的实现.
性能对比
这里对比MATLAB, Python 和Julia下的深度学习模型训练与测试性能. 由于最新版的Flux推荐使用CUDA11.2, 而本机操作系统尚且不支持CUDA11,故先对比CUDA10下的性能,后期有空了再更新环境, 重新对比.
LeNet5
对比模型就选择较为简单的LeNet5, 起初设计用于数字(0~9)手写体分类. 数据集介绍及下载可以访问这里, 其网络结构如下1 , 需要注意的是, 数据集的图像大小是
28
×
28
28\times 28
28×28, 不是下图中的
32
×
32
32\times 32
32×32

总共包含C1, C3, C5三个卷积层; S2, S4两个池化层, 也叫下采样层; 一个全连接层F6 和一个输出层OUTPUT. 具体参数如下, 其中卷积层参数格式输出通道数×输入通道数×卷积核高×卷积核宽, stride, padding (卷积输出大小的计算可以参考本人博客深度神经网络中的卷积) ; 池化层参数格式池化窗口的高×池化窗口的宽, stride, padding; 全连接参数格式输出神经元×输入神经元.
| 层名 | 参数 | 输入大小 | 输出大小 | 备注 |
|---|---|---|---|---|
| C1 | 6 × 1 × 5 × 5 6\times 1\times 5\times 5 6×1×5×5, 1, 0 | N × 1 × 32 × 32 N\times 1 \times 32\times 32 N×1×32×32 | N × 6 × 28 × 28 N\times 6 \times 28\times 28 N×6×28×28 | 32 + 2 × 0 ? 5 1 + 1 = 28 \frac{32+2\times 0 - 5}{1} + 1 = 28 132+2×0?5?+1=28 |
| S2 | 2 × 2 2\times 2 2×2, 2, 0 | N × 6 × 28 × 28 N\times 6 \times 28\times 28 N×6×28×28 | N × 6 × 14 × 14 N\times 6 \times 14\times 14 N×6×14×14 | 28 + 2 × 0 ? 2 2 + 1 = 14 \frac{28+2\times 0 - 2}{2} + 1 = 14 228+2×0?2?+1=14 |
| C3 | 16 × 6 × 5 × 5 16\times 6\times 5\times 5 16×6×5×5, 1, 0 | N × 6 × 14 × 14 N\times 6 \times 14\times 14 N×6×14×14 | N × 16 × 10 × 10 N\times 16 \times 10\times 10 N×16×10×10 | 14 + 2 × 0 ? 5 1 + 1 = 10 \frac{14+2\times 0 - 5}{1} + 1 = 10 114+2×0?5?+1=10 |
| S4 | 2 × 2 2\times 2 2×2, 2, 0 | N × 16 × 10 × 10 N\times 16 \times 10\times 10 N×16×10×10 | N × 16 × 5 × 5 N\times 16 \times 5\times 5 N×16×5×5 | 10 + 2 × 0 ? 2 2 + 1 = 5 \frac{10+2\times 0 - 2}{2} + 1 = 5 210+2×0?2?+1=5 |
| C5 | 120 × 16 × 5 × 5 120\times 16\times 5\times 5 120×16×5×5, 1, 0 | N × 16 × 5 × 5 N\times 16 \times 5\times 5 N×16×5×5 | N × 120 × 1 × 1 N\times 120 \times 1\times 1 N×120×1×1 | 可以使用全连接实现 |
| F6 | 84 × 120 84\times 120 84×120 | N × 120 N\times 120 N×120 | N × 84 N\times 84 N×84 | - |
| OUT | 10 × 84 10\times 84 10×84 | N × 84 N\times 84 N×84 | N × 10 N\times 10 N×10 | 0~9共10类 |
如今经常使用的LeNet5网络与原始的结构略微有些差异,主要体现在激活函数上, 如原始的输出层使用径向基(RBF),而现在常用Softmax. 卷积后的激活函数则常用ReLU.
由于原始的LeNet5网络计算了比较小,不能充分发挥GPU的性能,这里将C1, C3, C5 的输出通道数分别从 6, 16, 120 改为32, 64, 128, 下面给出实验代码和具体结果.
- 训练代数:
100 - 批大小:
600 - 每训练1代 (参数更新了60000/600=100次) 验证一次
- 学习率: 初始0.001, 每30代衰减一次,衰减系数0.1
- 不使用权重正则
Matlab实现
gpuDevice;
device = 'cpu';
mnist_folder = './mnist/';
[Xtrain, Ytrain, Xtest, Ytest] = read_mnist(mnist_folder);
rng(2022);
epochs = 100;
batch_size = 600;
[H, W, C, Ntrain] = size(Xtrain);
Ntest = size(Xtest, 4);
Ytrain = categorical(Ytrain);
Ytest = categorical(Ytest);
layers = [
imageInputLayer([28 28 1],"Name","imageinput")
convolution2dLayer([5 5],32,"Name","C1")
reluLayer("Name","relu1")
maxPooling2dLayer([2 2],"Name","S2","Stride",[2 2])
convolution2dLayer([5 5],64,"Name","C3")
reluLayer("Name","relu2")
maxPooling2dLayer([2 2],"Name","S4","Stride",[2 2])
convolution2dLayer([4 4],128,"Name","C5")
reluLayer("Name","relu3")
fullyConnectedLayer(84,"Name","F6")
reluLayer("Name","relu4")
fullyConnectedLayer(10,"Name","OUT")
softmaxLayer("Name","softmax")
classificationLayer("Name", "classoutput")];
plot(layerGraph(layers));
options = trainingOptions('adam', ...
'ExecutionEnvironment',device, ...
'ValidationData', {Xtest, Ytest}, ...
'ValidationFrequency', Ntrain/batch_size, ...
'Plots', 'none', ... % 'training-progress' or 'none'
'Verbose', true, ...
'VerboseFrequency', Ntrain/batch_size, ... %
'WorkerLoad', 1, ...
'MaxEpochs', epochs, ...
'Shuffle', 'every-epoch', ...
'InitialLearnRate', 1e-3, ...
'LearnRateSchedule', 'piecewise', ...
'LearnRateDropFactor', 0.1, ...
'LearnRateDropPeriod', 30, ...
'L2Regularization', 0, ....
'MiniBatchSize', batch_size);
net = trainNetwork(Xtrain, Ytrain, layers, options);
Ptest = classify(net, Xtest);
precision = sum(Ptest==Ytest) / numel(Ptest);
disp(precision)
PyTorch实现
Flux实现
参考文献
Y. LeCun, L. Bottou, Y. Bengio and P. Haffner: Gradient-Based Learning Applied to Document Recognition, Proceedings of the IEEE, 86(11):2278-2324, November 1998. ??

