Yolo v5ШчКЮИќЛЛМЄЛюКЏЪ§?
ЮФеТФПТМ
1.1 МЄЛюКЏЪ§ИќЛЛЗНЗЈ🍀
(1)евЕНactivations.py,МЄЛюКЏЪ§ДњТыаДдкСЫactivations.py ЮФМўРя.
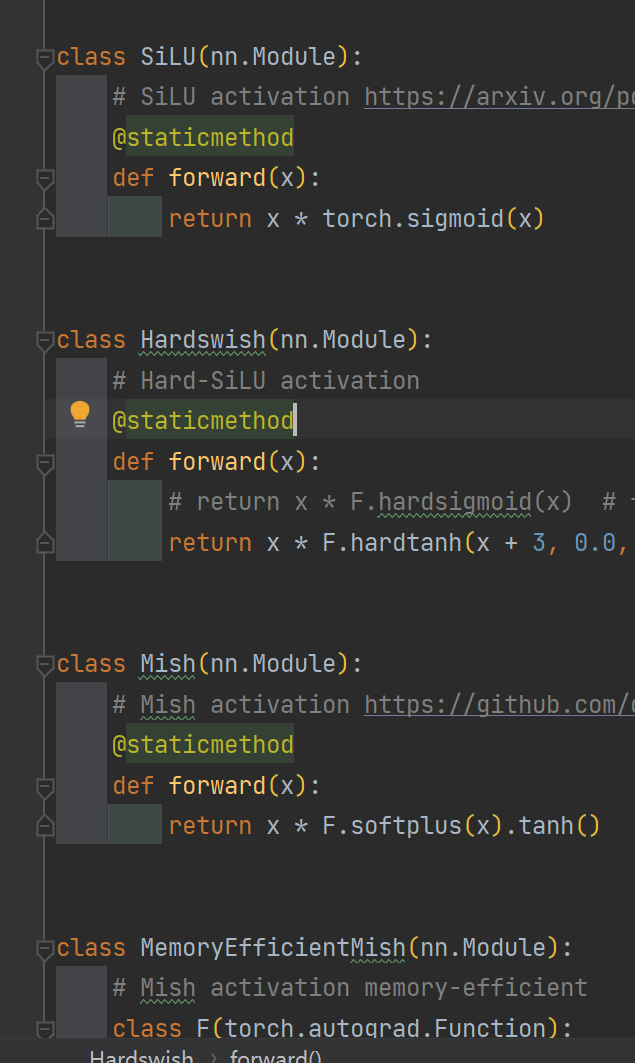
ДђПЊКѓОЭПЩвдПДЕНКмЖржжаДКУЕФМЄЛюКЏЪ§
(2)ШчЙћвЊНјаааоИФПЩвдШЅcommon.pyЮФМўРяаоИФ
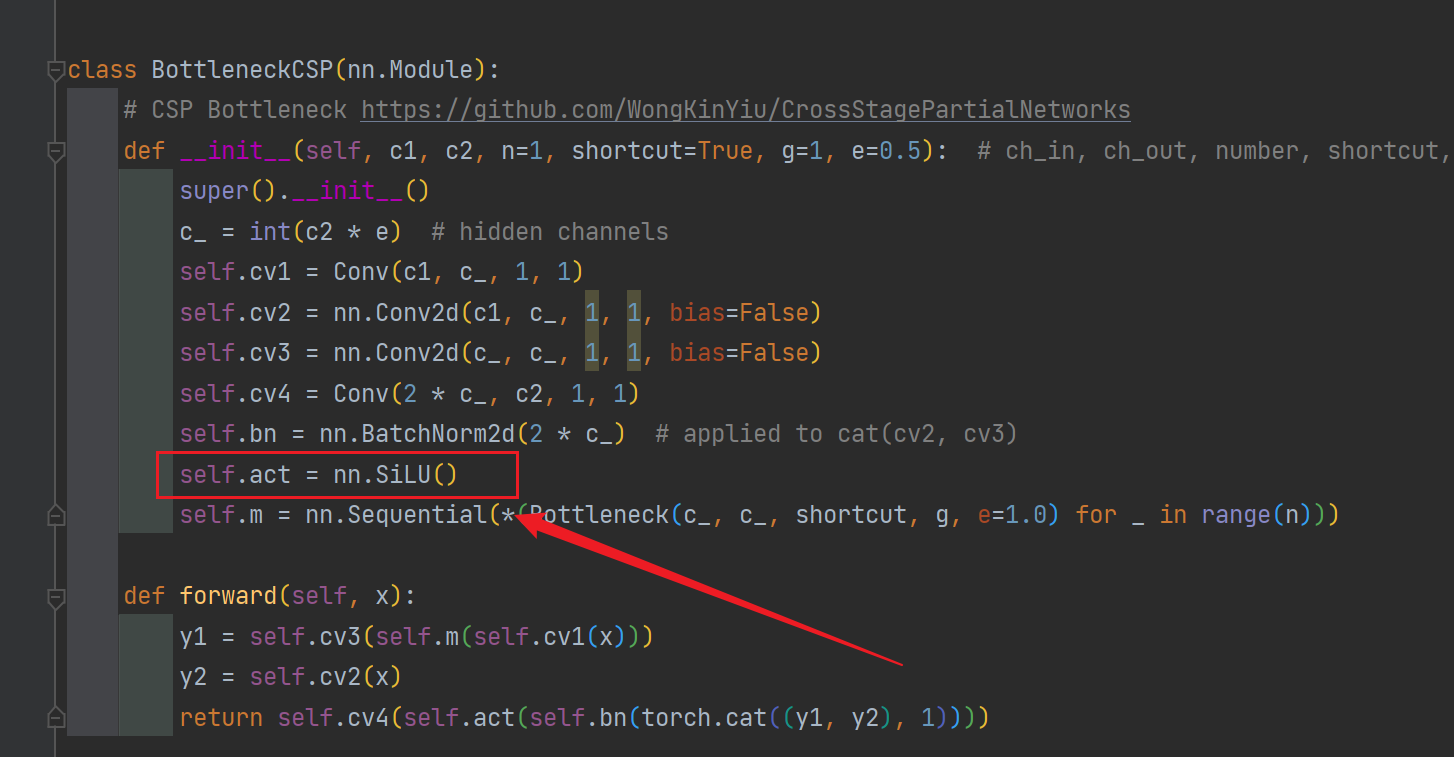
етРяКмЖрОэЛ§зщЖМЩцМАЕНСЫМЄЛюКЏЪ§(ЫЦКѕОЭетСЉЩцМАЕНСЫ),ЫљвдИФЕФЪБКђвЊШЋУцЁЃ

ЯТУцЗХЩЯвЛаЉаЇЙћБШНЯКУЕФМЄЛюКЏЪ§МАЭМЯё
1.2 МЄЛюКЏЪ§НщЩм💡(ГжајИќаТжа,вдКѓЛсЗХЩЯзюаТpaperЕФИДЯжНсЙћ)
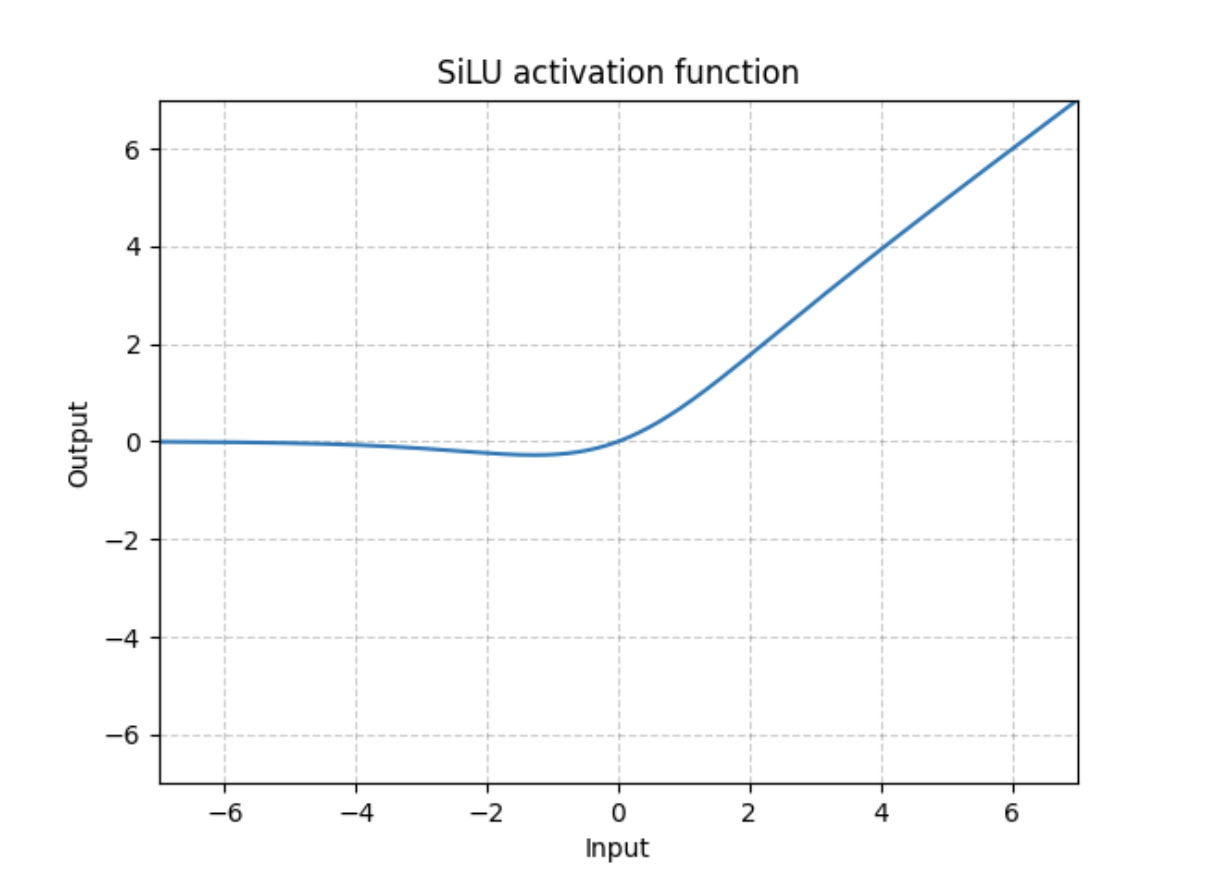
1.2.1 SiLU
SiLUгХЕу:
- ЮоЩЯНч(БмУтЙ§ФтКЯ)
- гаЯТНч(ВњЩњИќЧПЕФе§дђЛЏаЇЙћ)
- ЦНЛЌ(ДІДІПЩЕМ ИќШнвзбЕСЗ)
- x<0ОпгаЗЧЕЅЕїад(ЖдЗжВМгаживЊвтвх етЕувВЪЧSwishКЭReLUЕФзюДѓЧјБ№)
# SiLU https://arxiv.org/pdf/1606.08415.pdf ----------------------------------------------------------------------------
class SiLU(nn.Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
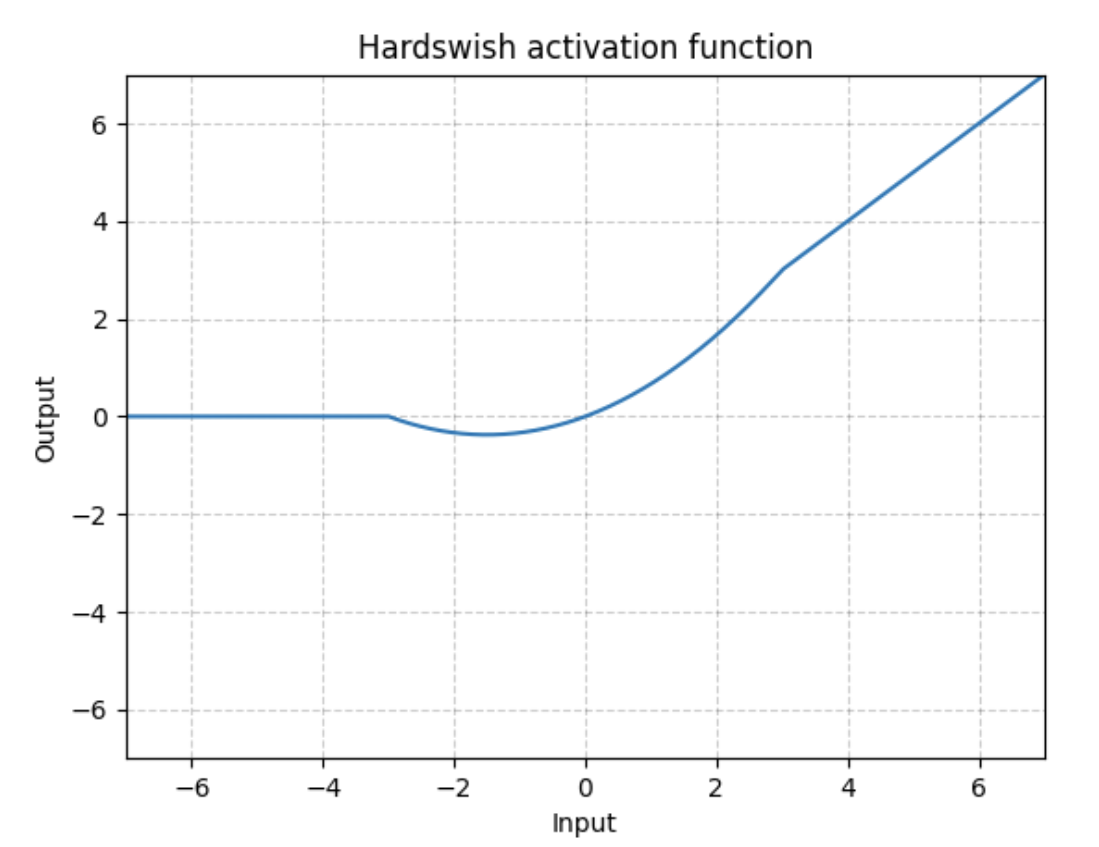
1.2.2 Hardswish
class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for TorchScript and CoreML
return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
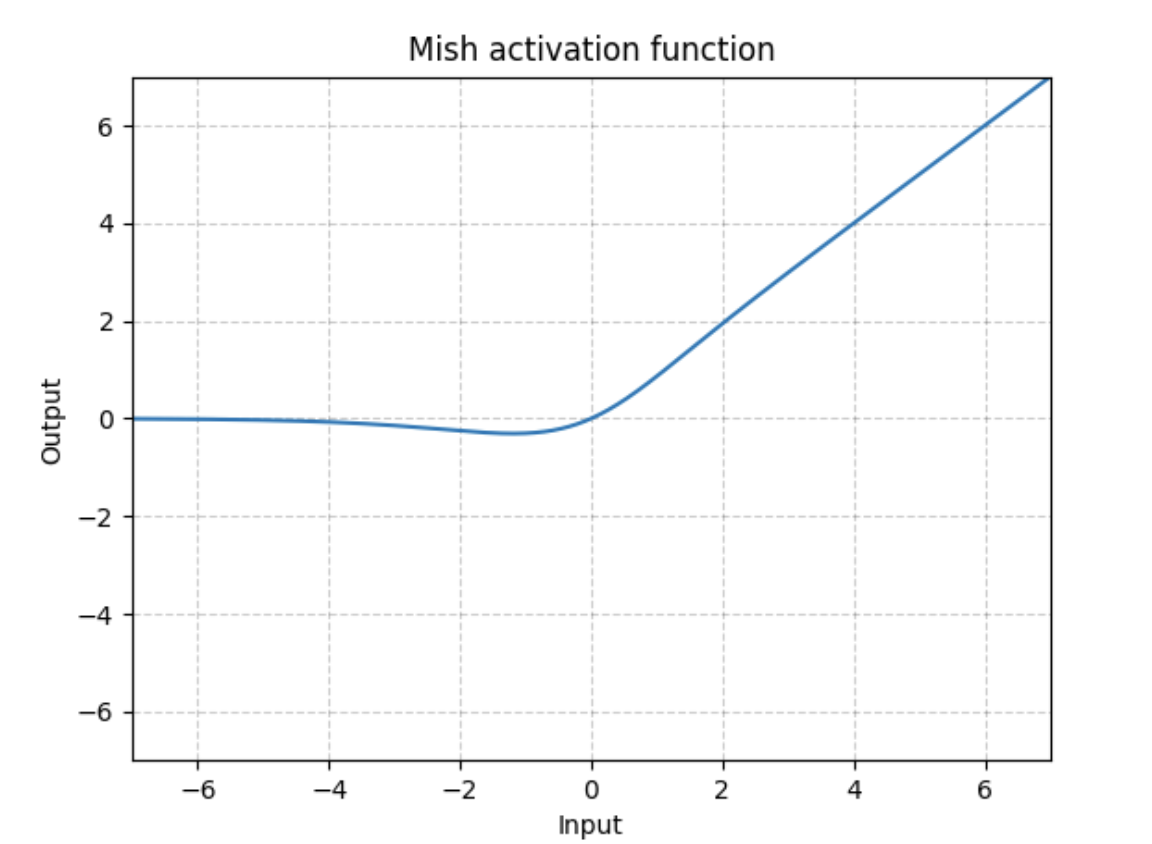
1.2.3 Mish
MishЬиЕу:
1.ЮоЩЯНч,ЗЧБЅКЭ,БмУтСЫвђБЅКЭЖјЕМжТЬнЖШЮЊ0(ЬнЖШЯћЪЇ/ЬнЖШБЌеЈ),НјЖјЕМжТбЕСЗЫйЖШДѓДѓЯТНЕ;
2.гаЯТНч,дкИКАыжсгаНЯаЁЕФШЈжи,ПЩвдЗРжЙReLUКЏЪ§ГіЯжЕФЩёОдЊЛЕЫРЯжЯѓ;ЭЌЪБПЩвдВњЩњИќЧПЕФе§дђЛЏаЇЙћ;
3.здЩэБООЭОпгазде§дђЛЏаЇЙћ(ЙЋЪНПЩвдЭЦЕМ),ПЩвдЪЙЬнЖШКЭКЏЪ§БОЩэИќМгЦНЛЌ(Smooth),ЧвЪЧУПИіЕуМИКѕЖМЪЧЦНЛЌЕФ,етОЭИќШнвзгХЛЏЖјЧввВПЩвдИќКУЕФЗКЛЏЁЃЫцзХЭјТчдНЩю,аХЯЂПЩвдИќЩюШыЕФСїЖЏЁЃ
4.x<0,БЃСєСЫЩйСПЕФИКаХЯЂ,БмУтСЫReLUЕФDying ReLUЯжЯѓ,етгаРћгкИќКУЕФБэДяКЭаХЯЂСїЖЏЁЃ
5.СЌајПЩЮЂ,БмУтЦцвьЕу
6.ЗЧЕЅЕї
# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
class Mish(nn.Module):
@staticmethod
def forward(x):
return x * F.softplus(x).tanh()
1.2.4 MemoryEfficientMish
вЛжжИпаЇЕФMishМЄЛюКЏЪ§ ВЛВЩгУздЖЏЧѓЕМ(здМКаДЧАЯђДЋВЅКЭЗДЯђДЋВЅ) ИќИпаЇ,MishЕФЩ§МЖАц
class MemoryEfficientMish(nn.Module):
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
sx = torch.sigmoid(x)
fx = F.softplus(x).tanh()
return grad_output * (fx + x * sx * (1 - fx * fx))
def forward(self, x):
return self.F.apply(x)
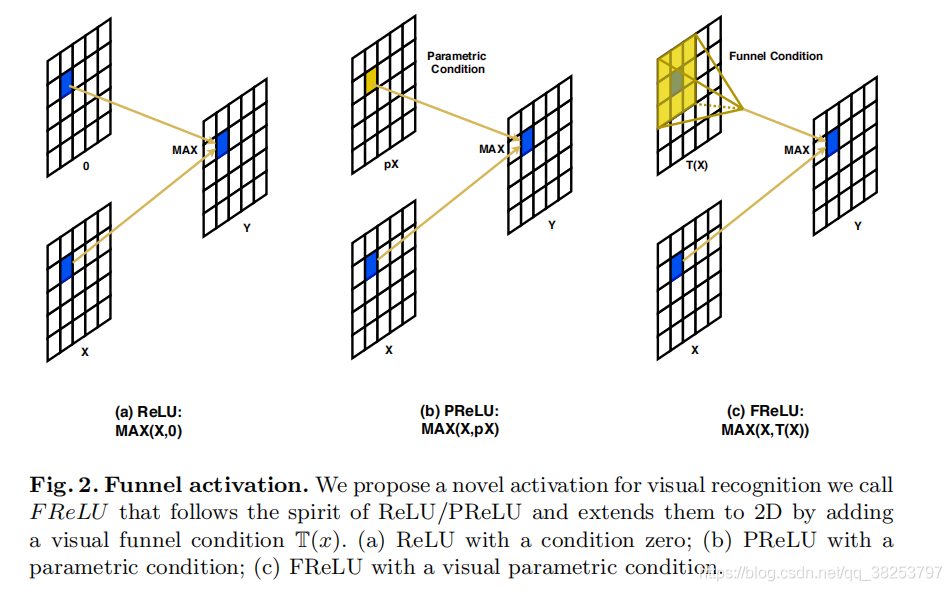
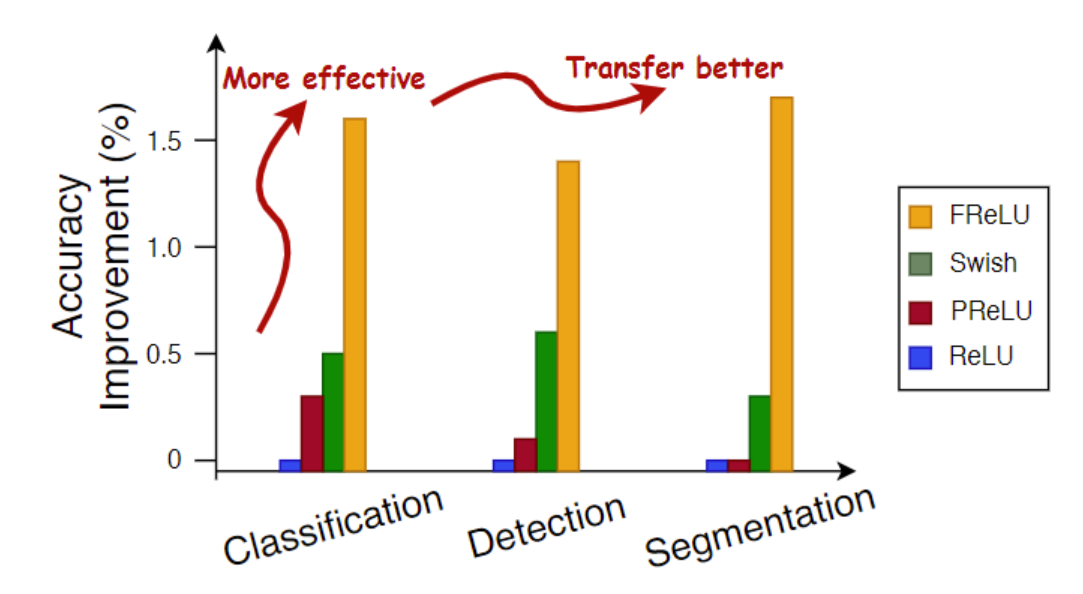
1.2.5 FReLU
FReLU(Funnel ReLU ТЉЖЗReLU)ЗЧЯпадМЄЛюКЏЪ§,дкжЛдіМгвЛЕуЕуЕФМЦЫуИКЕЃЕФЧщПіЯТ,НЋReLUКЭPReLUРЉеЙГЩ2DМЄЛюКЏЪ§ЁЃОпЬхЕФзіЗЈЪЧНЋmax()КЏЪ§ФкЕФЬѕМўВПЗж(дЯШReLUЕФx<0ВПЗж)ЛЛГЩСЫ2DЕФТЉЖЗЬѕМў(ДњТыЪЧЭЈЙ§DepthWise Separable Conv + BN ЪЕЯжЕФ),НтОіСЫМЄЛюКЏЪ§жаЕФПеМфВЛУєИаЮЪЬт,ЪЙЙцдђ(ЦеЭЈ)ЕФОэЛ§вВОпБИВЖЛёИДдгЕФЪгОѕВМОжФмСІ,ЪЙФЃаЭОпБИЯёЫиМЖНЈФЃЕФФмСІЁЃ
# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
class FReLU(nn.Module):
def __init__(self, c1, k=3): # ch_in, kernel
super().__init__()
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
self.bn = nn.BatchNorm2d(c1)
def forward(self, x):
return torch.max(x, self.bn(self.conv(x)))
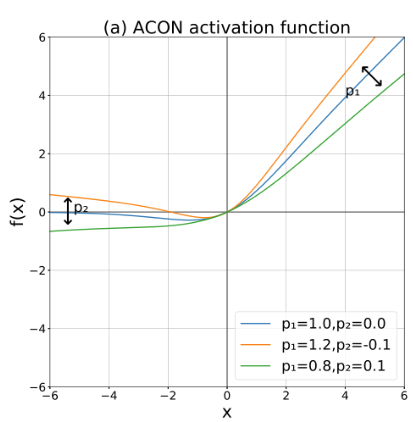
1.2.6 AconC
етЪЧ2021ФъаТГіЕФвЛИіМЄЛюКЏЪ§,ЯШДгReLUКЏЪ§ГіЗЂ,ВЩгУSmoth maximumНќЫЦЦНЛЌЙЋЪНжЄУїСЫSwishОЭЪЧReLUКЏЪ§ЕФНќЫЦЦНЛЌБэЪО,етвВЫуЬсГівЛжжаТгБЕФSwishКЏЪ§НтЪЭ(SwishВЛдйЪЧвЛИіКкКа)ЁЃжЎКѓНјвЛВНЗжЮіReLUЕФвЛАуаЮЪНMaxoutЯЕСаМЄЛюКЏЪ§,дйДЮРћгУSmoth maximumНЋMaxoutЯЕСаРЉеЙЕУЕНМђЕЅЧвгааЇЕФACONЯЕСаМЄЛюКЏЪ§:ACON-AЁЂACON-BЁЂACON-CЁЃзюжеЬсГіmeta-ACON,ЖЏЬЌЕФбЇЯА(здЪЪгІ)МЄЛюКЏЪ§ЕФЯпад/ЗЧЯпад,ЯджјЬсИпСЫБэЯжЁЃ
ЯИНкЧыПДетЮЛДѓРаЕФЮФеТ
class AconC(nn.Module):
r""" ACON activation (activate or not).
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
1.2.7 MetaAconC
ЩЯУцФЧИіЕФВЛЭЌАцБО
class MetaAconC(nn.Module):
r""" ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
зюКѓдйЗХвЛеХГЃМћМЄЛюКЏЪ§ЕФЭМ
ЧАбиpaperЕФМЄЛюКЏЪ§ИДЯж ГжајИќаТжаЁЃЁЃЁЃЁЃ

