正确理解图像信息在医学等领域是至关重要的。去噪可以集中在清理旧的扫描图像上,或者有助于癌症生物学中的特征选择。噪音的存在可能会混淆疾病的识别和分析,从而导致不必要的死亡。因此,医学图像去噪是一项必不可少的预处理技术。
所谓的自编码器技术已被证明是非常有用的图像去噪。
自编码器由编码器模型和解码器模型两个相互连接的人工神经网络组成。自动编码器的目标是找到一种将输入图像编码为压缩格式(也称为潜在空间)的方法,使解码后的图像版本尽可能接近输入图像。
Autoencoders如何工作
该网络提供了原始图像x,以及它们的噪声版本x~。该网络试图重构其输出x ',使其尽可能接近原始图像x。通过这样做,它学会了如何去噪图像。
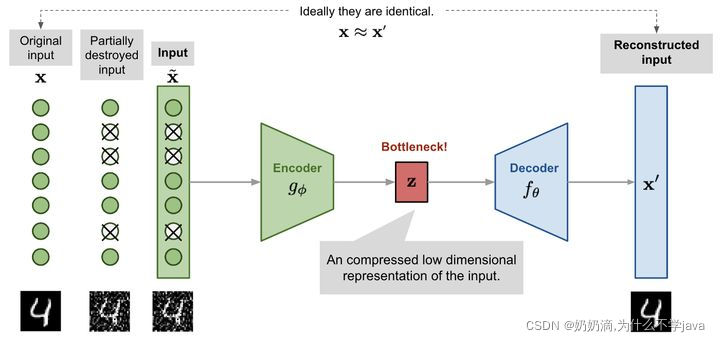
如图所示,编码器模型将输入转换为一个小而密集的表示。解码器模型可以看作是一个生成模型,它能够生成特定的特征。
编码器和解码器网络通常作为一个整体进行训练。损失函数判断网络创建的输出x '与原始输入x的差别。
通过这样做,编码器学会了在有限的潜在空间中保留尽可能多的相关信息,并巧妙地丢弃不相关的部分,如噪声。解码器学习采取压缩潜在信息,并重建它成为一个完全无错误的输入。
导入数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms
import torch.nn.functional as F
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
transform1 = transforms.Compose([
transforms.ToTensor(),
# 高斯模糊
transforms.GaussianBlur(kernel_size=3, sigma=(5.0, 10.0)),
])
# 获取手写数字的训练集和测试集
train_dataset = datasets.MNIST(root='./zibianma',
transform=transform1,
train=True,
download=True)
test_dataset = datasets.MNIST(root='./zibianma',
transform=transforms.ToTensor(),
download=True)先看一下数据集长啥样
train_dataiter = iter(train_dataset)
test_dataiter = iter(test_dataset)
plt.show()
for i in range(2):
train_images, train_labels = train_dataiter.__next__()
test_images, test_labels = test_dataiter.__next__()
train_images = train_images.numpy().squeeze()
test_images = test_images.numpy().squeeze()
plt.subplot(1,2,1)
plt.imshow(train_images)
plt.subplot(1,2,2)
plt.imshow(test_images)
plt.pause(1)
构造自己的数据集
train_dataiter = iter(train_dataset)
test_dataiter = iter(test_dataset)
train_x=[]
train_y=[]
for i in range(6000):
train_images, train_labels = train_dataiter.__next__()
test_images, test_labels = test_dataiter.__next__()
train_x.append(train_images.numpy().tolist())
train_y.append(test_images.numpy().tolist())抄了个噪声函数
from skimage.util import random_noise
# 噪声函数
def gaussian_noise(images, sigma):
sigma2 = sigma**2 / (255**2) #噪声方差
images_noisy = np.zeros_like(images)
for i in range(images.shape[0]):
image = images[i]
noise_im = random_noise(image,mode='gaussian',var=sigma2,clip=True)
images_noisy[i] = noise_im
return images_noisy转tensor加噪声
pre_train=torch.Tensor(train_x)
train= torch.from_numpy(gaussian_noise(pre_train,30))
test=torch.Tensor(train_y)构造数据集
new_train_datasets=Data.TensorDataset(train, test)构造dataloader
new_train_loader = Data.DataLoader(
dataset=new_train_datasets,
batch_size=32,
shuffle=True,
num_workers=4
)定义网络(编码,解码)
class DenoiseAutoEncoder(nn.Module):
def __init__(self):
super(DenoiseAutoEncoder, self).__init__()
#Encoder
self.Encoder = nn.Sequential(
# 1*28*28
nn.Conv2d(1, 64, 3, 1, 1),
nn.ReLU(),
# 64*28*28
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
# 64*28*28
nn.MaxPool2d(2, 2),
# 64*14*14
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, 3, 1, 1),
nn.ReLU(),
# 128*14*14
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, 1, 1),
nn.ReLU(),
# 128*14*14
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, 3, 1, 1),
nn.ReLU(),
# 256*14*14
nn.MaxPool2d(2, 2),
# 256*7*7
nn.BatchNorm2d(256),
)
#Decoder
self.Decoder = nn.Sequential(
# 256*7*7
nn.ConvTranspose2d(256, 128,3, 1, 1),
nn.ReLU(),
# 128*7*7
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 128, 3, 2, 1, 1),
nn.ReLU(),
# 128*14*14
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1),
nn.ReLU(),
# 64*14*14
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, 3, 1, 1),
nn.ReLU(),
# 64*14*14
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 32, 3, 1, 1),
# 32*14*14
nn.ConvTranspose2d(32, 16, 3,2, 1, 1),
nn.ReLU(),
# 16*28*28
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16, 1, 3, 1, 1),
nn.Sigmoid(),
)
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return decodernn.BatchNorm2d(), 归一化
nn.ConvTranspose2d(), 逆卷积
nn.Sigmoid(),?
nn.ReLU(),
nn.MaxPool2d() , 池化
nn.Conv2d(), 卷积
声明model
DAEmodel = DenoiseAutoEncoder()
DAEmodel=DAEmodel.cuda()优化器和损失函数
optimizer = optim.Adam(DAEmodel.parameters(),lr=0.0003)
loss_fn = nn.MSELoss()训练
for epoch in range(10):
Loss=0
sum=0
train_dataiter = iter(train_dataset)
test_dataiter = iter(test_dataset)
for step,(data,label) in enumerate(new_train_loader):
#梯度清空
optimizer.zero_grad()
#前向传播
output = DAEmodel(data.cuda()) # 加密,解密
#计算损失
loss=loss_fn(output,label.cuda())
#反向传播
loss.backward()
#梯度更新
optimizer.step()
# 计算损失
Loss=Loss+loss
sum=i
print(Loss/sum)
看下效果吧,在训练集上的
with torch.no_grad():
for data in new_train_loader:
images,labels = data
outputs = DAEmodel(images.cuda())
plt.subplot(1,3,1)
#加噪声图片
plt.imshow(images[0].squeeze())
plt.subplot(1,3,2)
#原图片
plt.imshow(labels[0].squeeze())
plt.subplot(1,3,3)
#修复图片
plt.imshow(outputs[0].cpu().squeeze())
plt.pause(1)

