论文及代码链接
作者思考及论文动机
个人的一些碎碎念
??其实PVCNN这篇论文十分好理解,采用的模型也十分简单,就是通过卷积的方法去提取局部特征,然后通过插值进行上采样,最后将上采样的特征直接concat到点云原始特征,之后就是pointnet那一套了。这篇论文最大的亮点是可以让我们更直观深入地理解基于体素的方法与基于点的方法的区别,文章中不仅指出了两种方法的局限,也给出了相应的实验与分析。
论文动机
??我们做3D目标检测很多时候是要用于终端设备的,终端设备,我们就不得不考虑成本问题、实时性问题。(当然硬要在终端设备上跑一台3090,我也不太敢说啥)。实时性就要求算法计算量不能太大,而成本限制了算力与存储空间。所以说,我认为,在不断追求算法的高AP的同时,最求real-time以及light也是十分重要的。当然,作者也是这么认为的。
当前方法的一些问题
??Voxel-based: 由于体素化,会带来较大的内存占用。(这块儿很多人会有疑问了,为什么体素化会带来比较大的内存占用呢,按理来说,体素的数量是一定远小于点云的数量的,因为一个体素内应该包含多个的点。其实应该说是有值的体素的数量是远小于点云的数量的,但是没有值,也就是内部没有点的体素我们也需要存起来,也就是说其也占显存,为什么呢,一来,只有这样,通过体素间的下标差才能和体素间距离对应起来,二来,在卷积过程中,空体素也会有值,只要当卷积核覆盖这个体素的时候,卷积核内有非空体素。由于点云的极度稀疏性,体素的数量将远远远大于点的数量,内存占用大就不难理解了)。同时,在体素化的方法中,内存占用与计算量与体素的分辨率是成正比的。也就是分别率每变到原来的两倍,内存占用与计算量就是原来的2x2x2倍,但是分辨率越大,体素化带来的信息损失就越少。也就是体素化的方法一直面临着分辨率与内存占用、计算量之间的矛盾。
Point-based: Point-based方法得益于点云的稀疏性,其占用的内存比较少,但是由于点云是无序的,其在存储空间中的存储没有规律。因此,每当我们想找一个点周围一定范围内的点聚合局部特征的时候,我们就需要遍历点云中的所有的点,而不能像规则数据那样直接通过索引偏移(其实就是内存地址偏移)得到。这种操作很花时间,大大限制了基于点的方法的使用范围。
PVCNN的模型结构
??PVCNN的模型结构如下图所示:
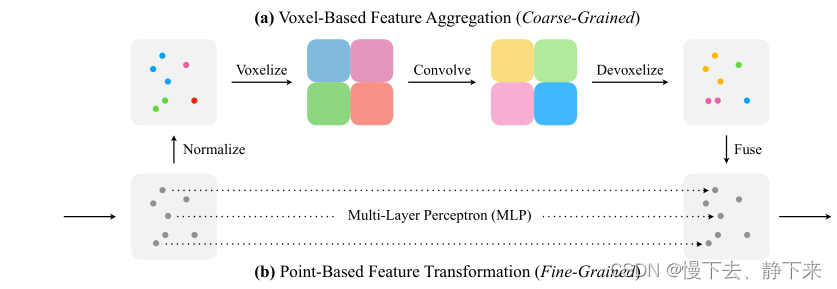
??其思想及其简单:具体思路我用大白话表达就是。Point-based方法为什么花时间呢,因为我们需要提取局部特征,提取局部特征需要寻找关键点的周围的点,需要我们遍历整个点云。但是,提取全局特征是不用的,因为全局特征用的是点云中的所有点,不用去寻找邻域了。也就是说,Point-based方法的短板主要是在提取局部特征这块儿。
??那PVCNN怎么解决的呢,PVCNN直接用体素化的方法来提取局部特征。不过前头不是说了吗,体素化的方法会带来较大的显存占用。确实是的,但是这是在分辨率较大的情况下,由于我们还保留有点的原始特征,我们可以将体素化的分辨率设的小一点(注意分辨率小就是体素网格大呀),这样内存占用就会小一些。体素化好之后,我们就可以采用3D来提取局部特征了。最后,我们通过三线性插值(这个就是双线性插值在三维空间的使用,很很好理解的),就可以得到每个点的局部空间特征,将这个特征与点的原始特征进行拼接,然后采用pointnet的结构进行处理就行了。
结果以及个人思考
??论文中给出的结果当然就是又快又好又轻量了,这块就不具体讲了,大家啊自己看一下原论文就行。
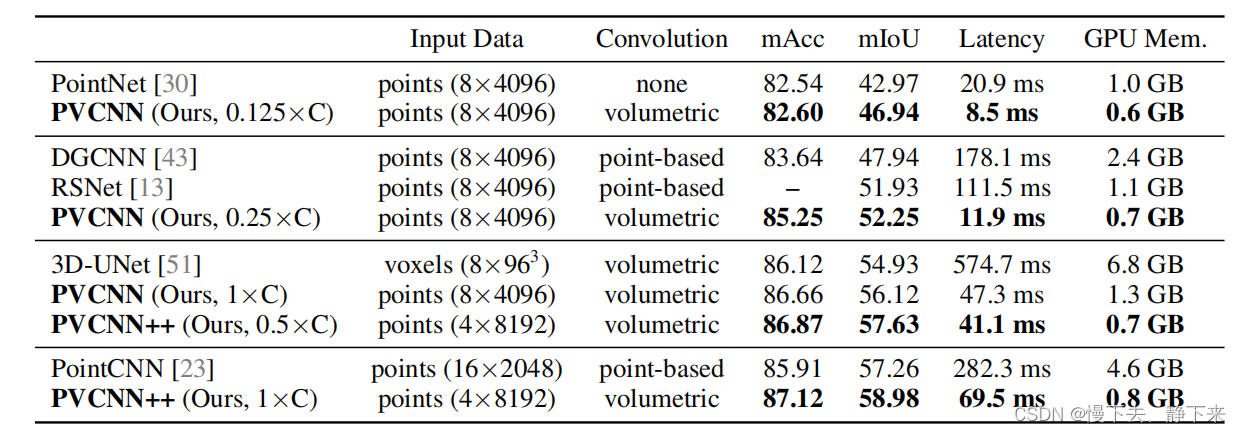
??其实这个网络总体来看,就是pointnet++的改进,改进了的地方就是局部特征的提取部分。pointnet++是通过SA结构来提取的,也就是不断找局部空间然后采用pointnet聚合特征,而PVCNN是通过体素化来提取局部特征的。这个时候,我说pointnet++所采用的数据没有信息损失,而PVCNN采用的数据有信息损失大家应该没有意见吧?但是大家看一下这样一个结果:
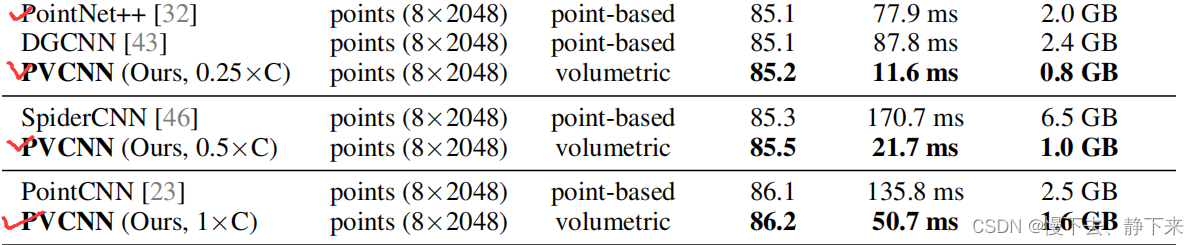
??为什么PVCNN所采用的数据已经有了信息损失还比pointnet++效果好呢?一个可能的原因就是3DCNN的特征提取能力比MLP强,这个原因也应该比较明显,大家如果还可以找到别的解释,是不是一篇paper就来了?反正菜菜的我找不到了,各位大佬加油

