文章来源 | 恒源云社区
原文地址 | VSA
原文作者 | 咚咚
伙伴们,好久不见了啊。
最近平台各种功能上线,实在抽不出时间搬运大佬们的文章,不是小编消极怠工哦~
这不,稍微有点时间空下来,小编就立即去社区精心挑选了一篇文章分享给你们啦。
走过路过,不要错过呀!废话不多说,正文走起🏃?♀?
👇👇👇
摘要
- 引入主题: 窗口自注意力已经在视觉Transformer中得到了广泛的探索,以平衡性能、计算复杂度和内存占用。
- 现存问题: 目前的模型采用预先定义的固定大小窗口设计,限制了它们建模长期依赖关系和适应不同大小对象的能力。
- 解决方法: 提出了可变尺寸窗口注意(VSA)来从数据中学习自适应窗口配置。具体来说,基于每个默认窗口中的token,VSA 使用了一个窗口回归模块来预测目标窗口的大小和位置。通过对每个注意头独立采用 VSA,可以建立长期依赖关系模型,从不同窗口捕获丰富的上下文,促进窗口之间的信息交换。
- 实验结果: VSA 是一个易于实现的模块,它可以用较小的修改和可以忽略的额外计算成本来替代最先进的代表性模型中的窗口注意力,同时大幅度地提高它们的性能,例如,在ImagNet 分类任务中,分类性能相对Swin-T提高了1.1% ,使用较大的图像训练和测试时,性能增益增加更大。另外,在目标检测分割、实例分割和语义分割任务中,处理不同大小的对象时,VSA 比普通窗口注意力更有优势。

算法
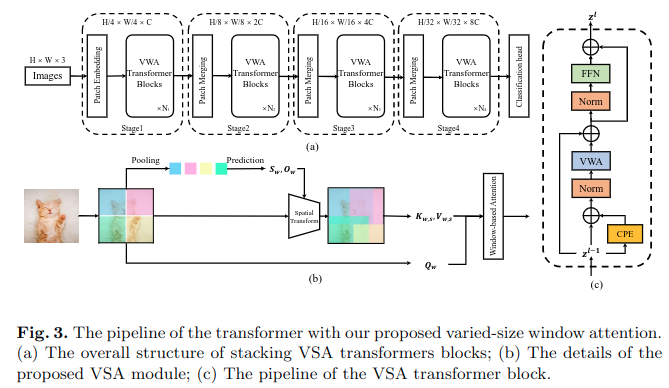
模型整体框架如上图(a)所示,是基于swin模型进行修改的,最主要的创新点是使用VSA(VWA) Transfomer blocks替代swin中的窗口自注意力block。
VSA Transformer模块如上图?所示,与传统的窗口自注意力模块不同,其中使用了VSA(VWA)(上图(b)所示)和CPE模块。接下来进行分别介绍。
VSA模块
上图(b)所示,可以简要看出,VSA module修改了每个窗口的大小和位置,提高模型对长远依赖的建模以及不同大小目标对象的检测。具体操作步骤如下:
-
给定VSA模块的输入特征 X X X,首先将其平分成大小一样的不重叠窗口 X w X_w Xw??,这与传统方法一样
-
对每个窗口进行线性操作得到对应的查询 Q w Q_w Qw??, Q w = L i n e a r ( X w ) Q_w = Linear(X_w) Qw?=Linear(Xw?)
-
为了获得每个窗口的长宽两个方向上的缩放和位置偏置,需要进行如下操作:
1). 对 X w X_w Xw?使用核大小和步长与窗口大小一样的平均池化操作,并附加LeakyRelu激活层
2). 进一步使用1 ×1的卷积层,输出 S w S_w Sw??和 O w O_w Ow?,大小均为 R 2 × N R^{2×N} R2×N,其中2表示长宽两个方向,N表示head个数

-
获得了缩放和偏置,那就要提取特征了,首先基于输入特征 X X X进行线性操作获取特征图 K K K和 V V V
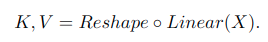
-
然后,VSA模块根据缩放和偏置在 K K K和 V V V上进行特征提取,得到 K k , v , V k , v ∈ R M × N × C ′ K_{k, v}, V_{k, v} \in R^{M×N×C^{\prime}} Kk,v?,Vk,v?∈RM×N×C′
-
最后将 K k , v , V k , v , Q w K_{k, v}, V_{k, v}, Q_w Kk,v?,Vk,v?,Qw??输入到多头自注意力模块MHSA中
CPE模块
由于窗口变形会导致位置信息的变化,使得Q和K V的位置信息出现偏差,论文使用了条件位置编码CPE(来自CPVT论文)来解决这个问题
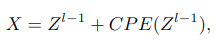
实验
ImageNet分类任务

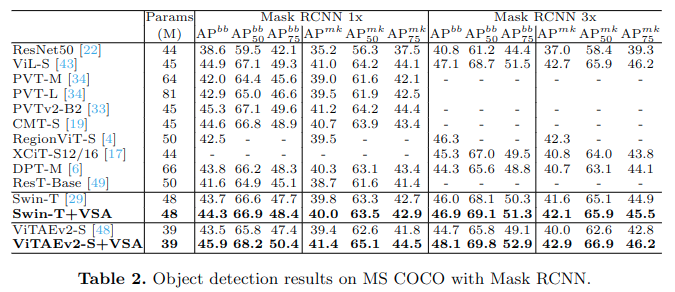
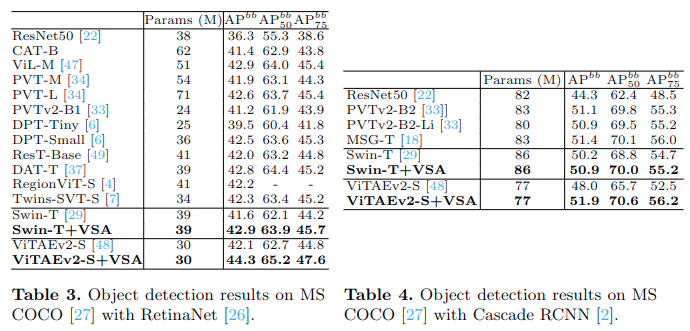
MS COCO目标检测和实例分割任务
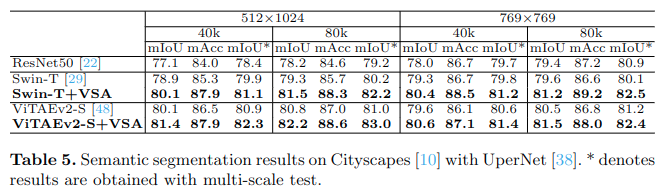
Cityscapes语义分割任务
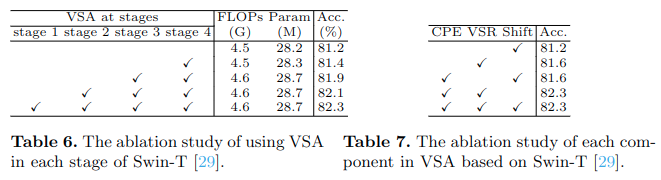
消融实验
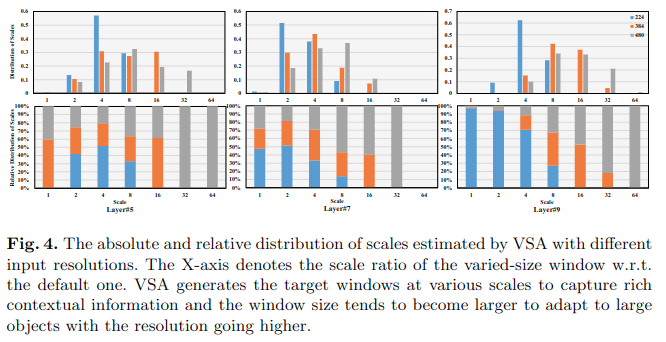
可视化


