1、 R-CNN
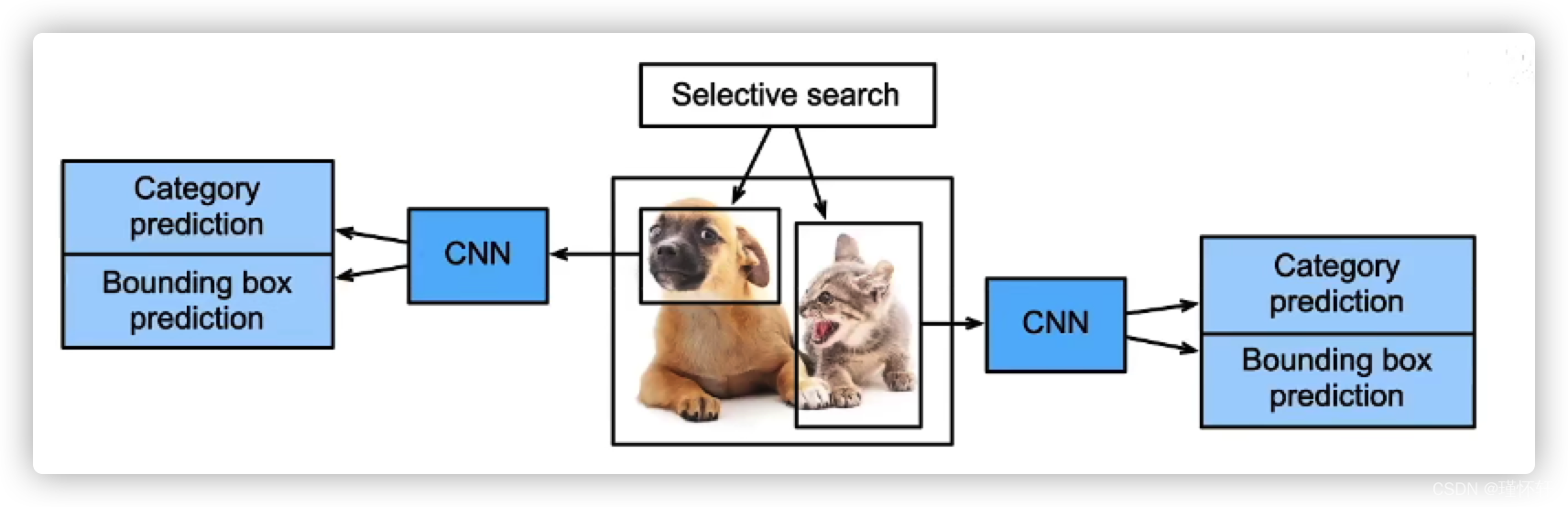
- 使用启发式搜索算法来选择锚框,如 selective search
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM对类别分类 【深度学习之前常使用】
- 训练一个线性回归模型来预测边缘框偏移
[思考🤔]怎么样使得产生的不一样大小锚框形成 一个batch?
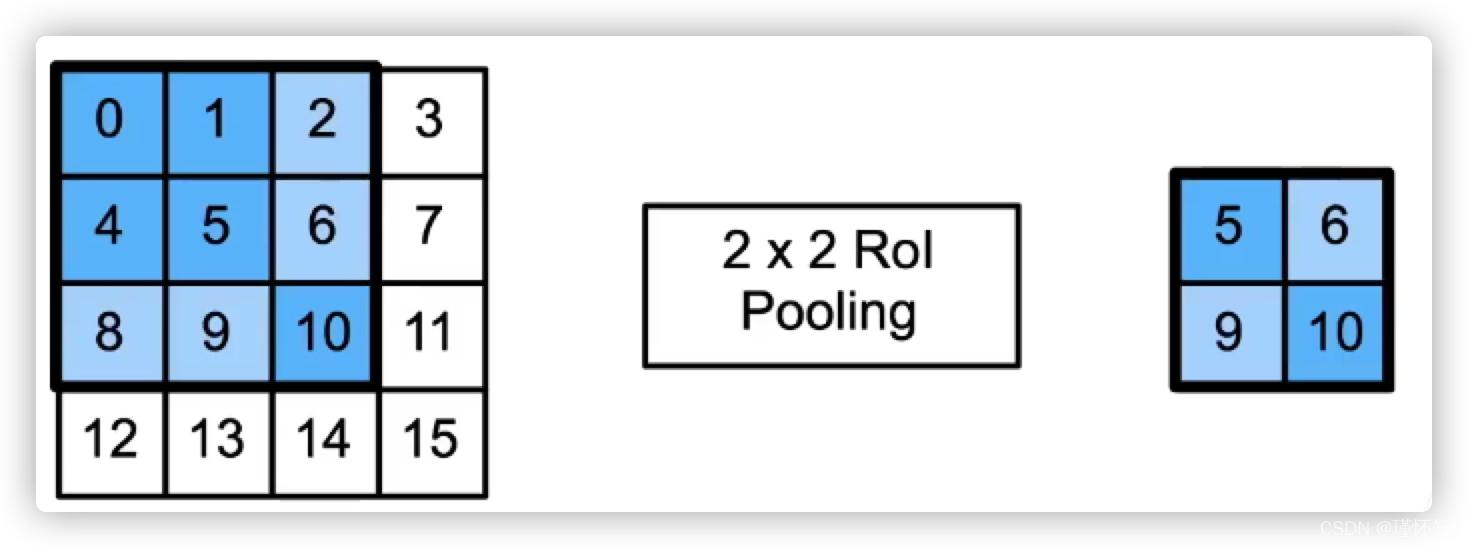
兴趣区域(RoI)池化层
- 给定一个锚框,均匀分割成n×m块,输出每块里最大值
- 不管锚框多大,输出总为nm个值
Fast RCNN
- 使用CNN对图片抽取特征
- 使用RoI池化层对每个锚框生成固定长度特征
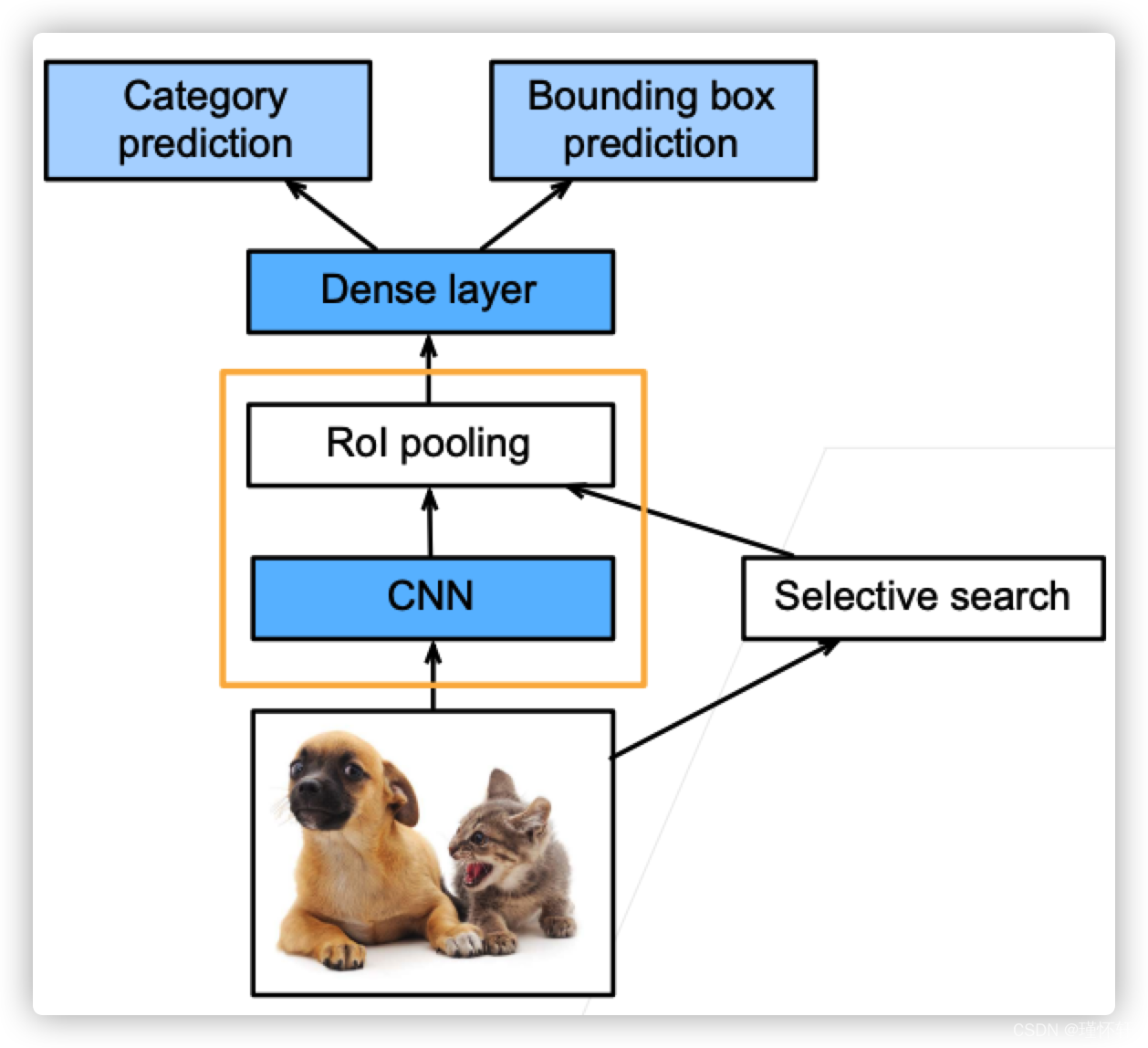
【思考🤔】这里主要是简化计算量,将图像全部区域抽取特征后,在特征层上使用selective search的方法生成锚框,通过RoI池化将锚框整合成相同大小的向量的batch。其中减小的计算量主要是锚框重合区域提取特征的开销。
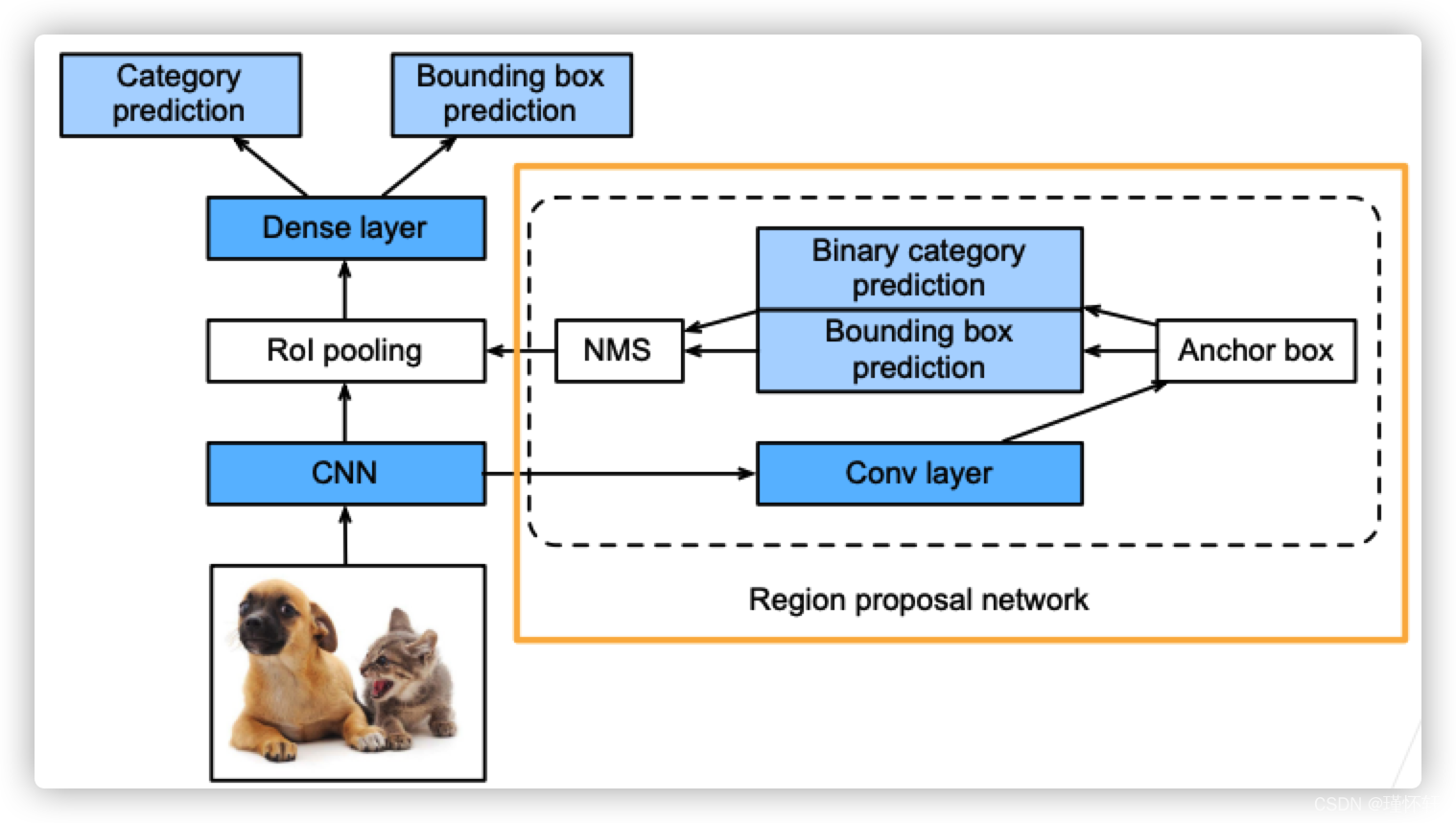
Faster R-CNN
- 使用一个区域提议网络(RPN)来替代启发式搜索(selective search)来获得更好的锚框
Mask R-CNN
- 如果有像素级的标号,使用FCN来利用这些信息
- RoI Pooling 变成 RoI Align
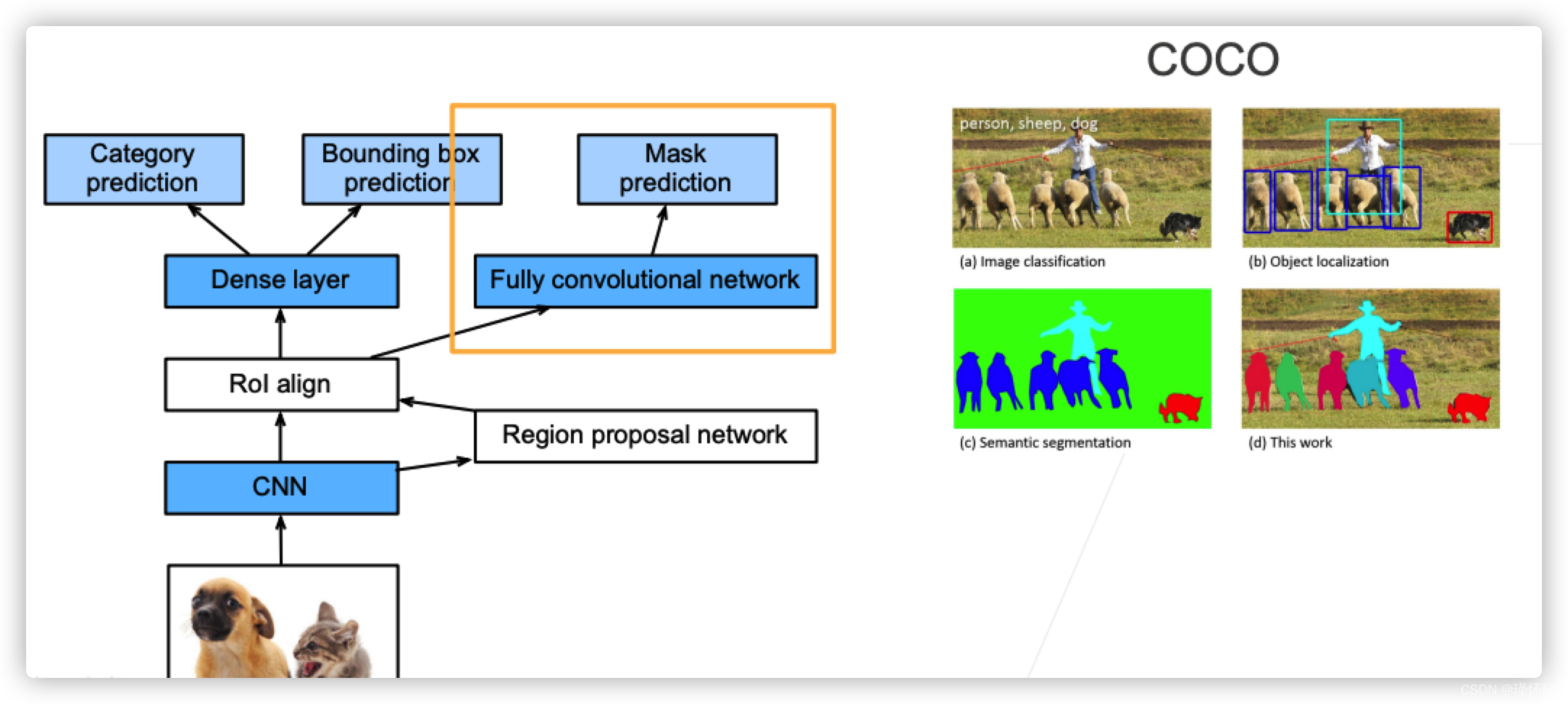
【说明】RoI Pooling在像素不能平分的情形做分割任务会有较大误差,使用RoI Align 将像素级别通过加权的方式平分共用像素;也就是说,align 没有暴力取整,保留浮点位置,并使用双线性插值,提升精度
【🤔】有像素级标签的网络模型中添加FCN就能做语义分割。
模型进度对比
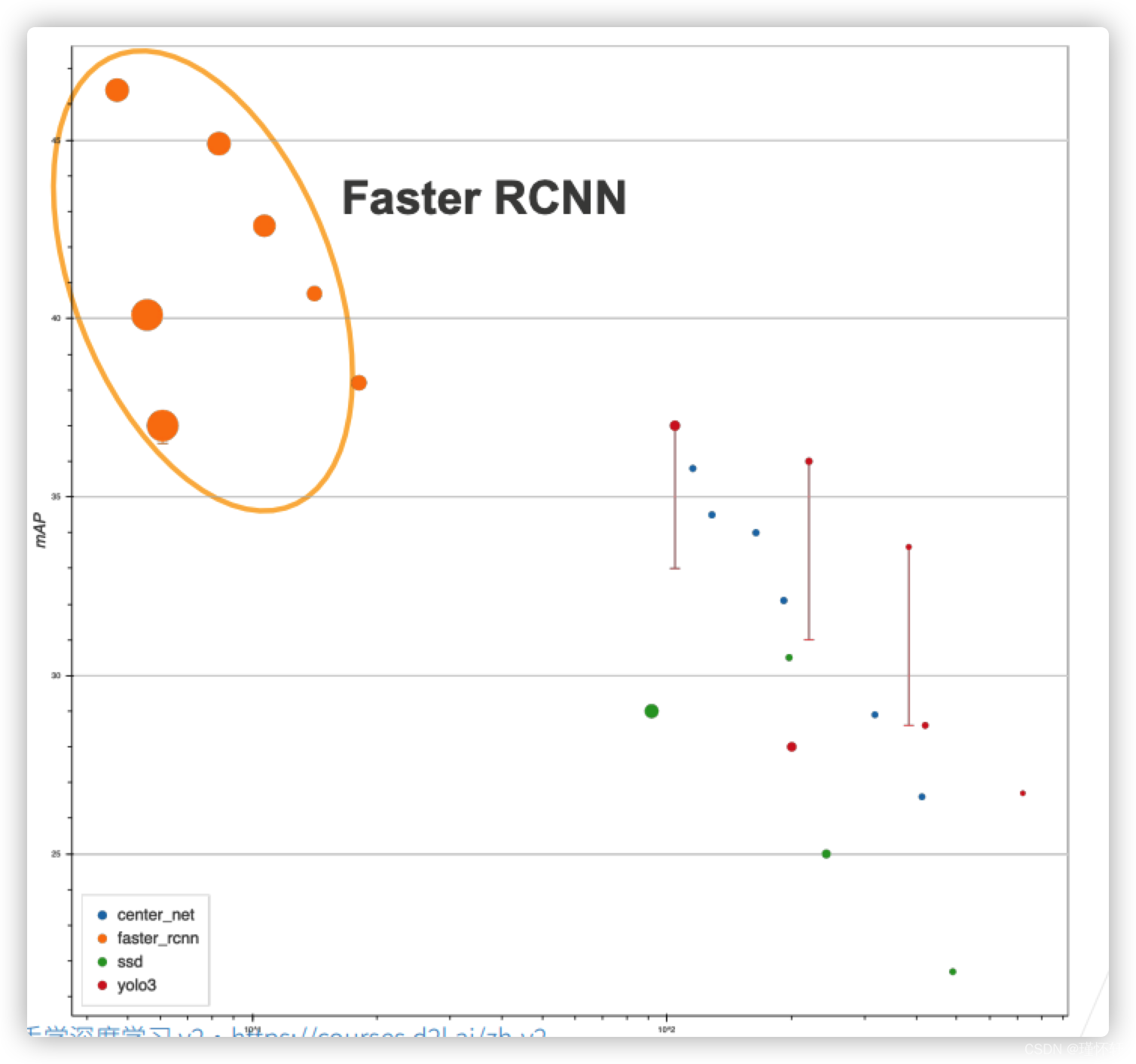
总结
- R-CNN 是最早、也是最有名的一类基于锚框和CNN的目标检测算法
- Fast、Faster R-CNN持续提升性能
- Faster R-CNN 和Mask R-CNN是在追求高精度场景下常用算法
SSD(单次多框检测)
- 对每个像素,生成多个以它为中心锚框
- 给定n个大小s1,s2…,sn 和m个高宽比,那么生成n+m-1个锚框,其中大小和宽高比分别为:(s1,r1),(s2,r1)…(sn,r1),(s1,r2)…(s1,rm)
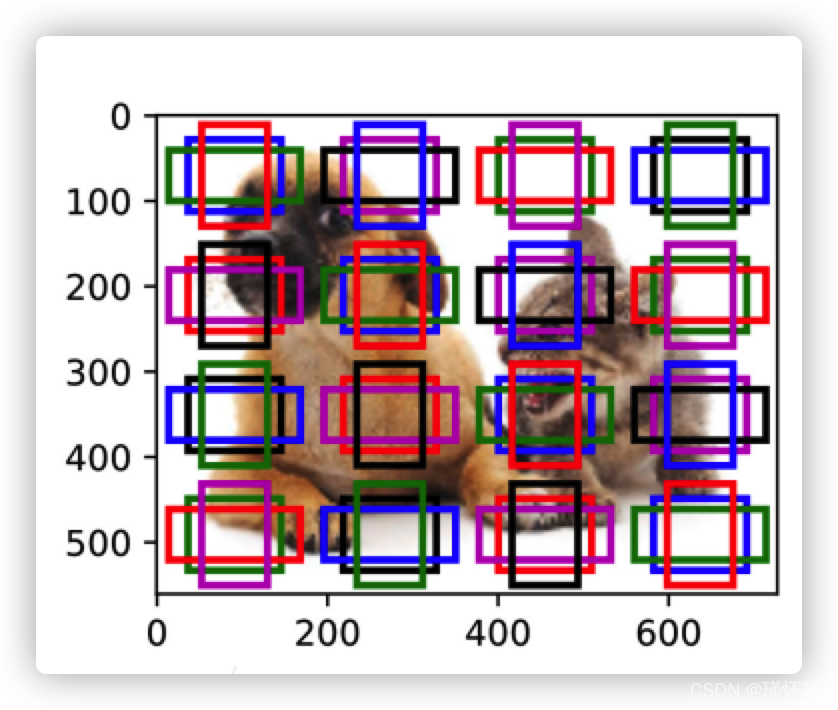
SSD 模型
- 一个基础网络来抽取特征,然后多个卷积层来减半高宽
- 在每段都生成锚框
- 底部段生成锚框来检测小物体,顶部段来检测大物体
-对每个锚框预测类别和边缘框
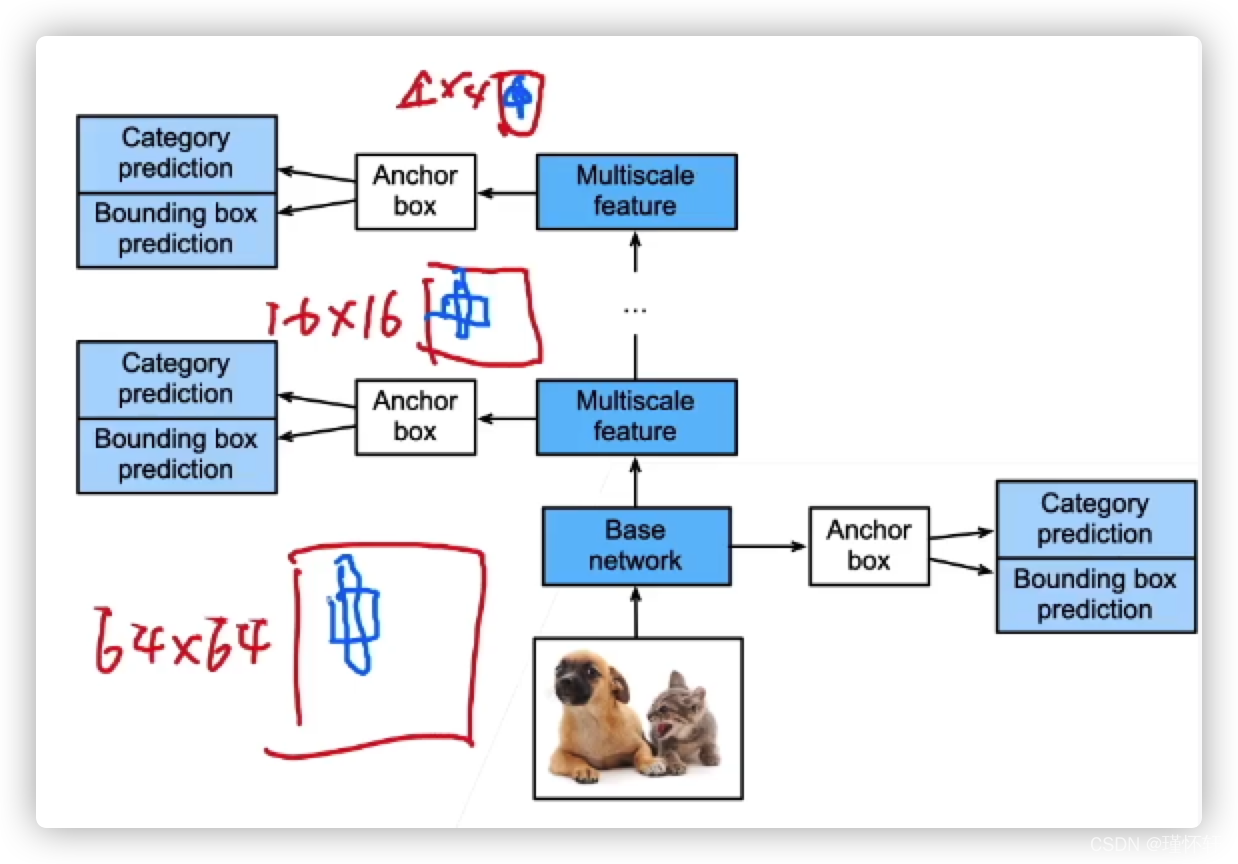
- 底部段生成锚框来检测小物体,顶部段来检测大物体
【思考🤔】生成100万个锚框,速度还能达到这么快,不过精度不是很高。主要出现的很早。相对R-CNN简单
总结
- SSD 通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框
- 在多个段的输出上进行多尺度的检测
YOLO(只看一次)
- SSD中锚框大量重叠,因此浪费了很多计算
- YOLO将图片均匀分成S×S个锚框
- 每个锚框预测B个边缘框
- 后续有持续版本改进


