?相关文章和数据源:
Python自动化办公--Pandas玩转Excel数据分析【二】
Python自动化办公--Pandas玩转Excel数据分析【三】
python处理Excel实现自动化办公教学(含实战)【一】
python处理Excel实现自动化办公教学(含实战)【二】
python处理Excel实现自动化办公教学(数据筛选、公式操作、单元格拆分合并、冻结窗口、图表绘制等)【三】
python入门之后须掌握的知识点(模块化编程、时间模块)【一】
python入门之后须掌握的知识点(excel文件处理+邮件发送+实战:批量化发工资条)【二】
spandas玩转excel码源.zip-数据挖掘文档类资源-CSDN下载
Python自动化办公(2021最新版!有源代码,).zip-
Python自动化办公(可能是B站内容最全的!有源代码,).zip-
上面是对应码源,图方便的话可以直接下载都分类分好了,当然也可以看文章。
1.知识巩固excel
这个系列文章主要以实例为主,学会每个demo,活学活用,办公效率提升飞快!
1.1 xlrd+xlwt读写excel
#安装命令:
pip install xlrd
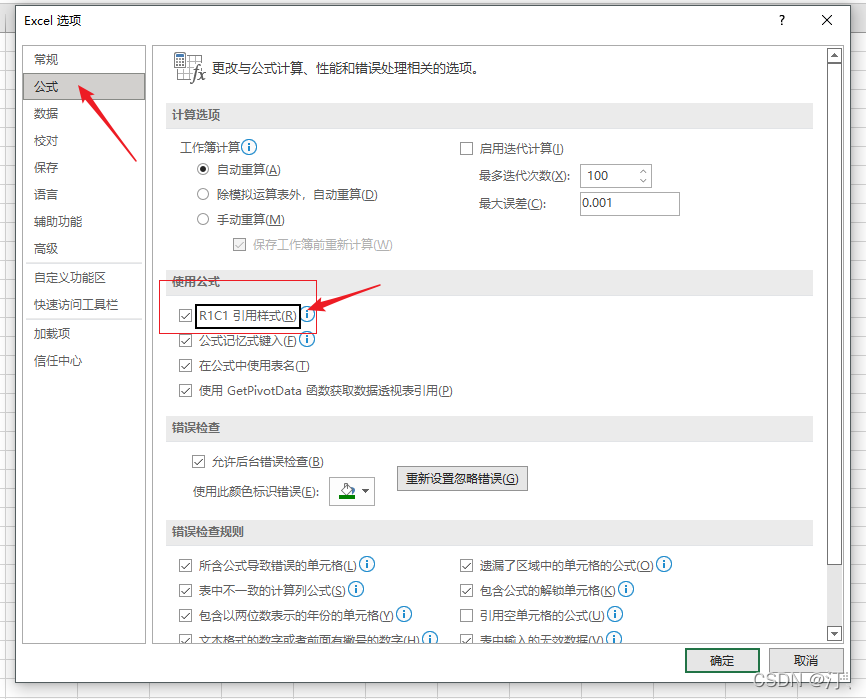
pip install xlwt我们在读取文件的时候,excel的列是字母我们不容易直观看出来是第几列,下面对excel进行设置。

?操作如下
import xlrd
# 打开excel
xlsx = xlrd.open_workbook('7月新.xls')
sheet = xlsx.sheet_by_index(0)
data = sheet.cell_value(5, 1)
print(data)
# for i in xlsx.sheet_names():
# print(i)
# table = xlsx.sheet_by_name(i)
# print(table.cell_value(3, 3))
# 通过sheet名查找:xlsx.sheet_by_name("7月下旬入库表")
# 通过索引查找:xlsx.sheet_by_index(3)
# print(table.cell_value(0, 0))
#单元格读取方式
print(sheet.cell_value(1, 2))
print(sheet.cell(0, 0).value)
print(sheet.row(0)[0].value)
# for i in range(0, xlsx.nsheets):
# sheet = xlsx.sheet_by_index(i)
# print(sheet.name)
# print(sheet.cell_value(0, 0))
#
# # 获取所有sheet名字:xlsx.sheet_names()
# # 获取sheet数量:xlsx.nsheets
#
# for i in xlsx.sheet_names():
# print(i)
# table = xlsx.sheet_by_name(i)
# print(table.cell_value(3, 3))import xlwt
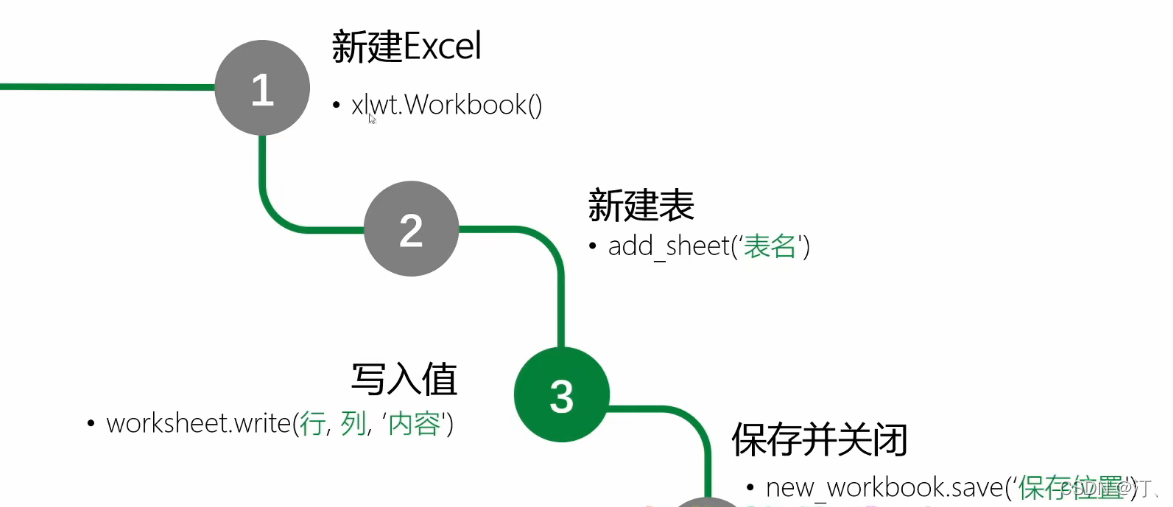
# 新建工作簿
new_workbook = xlwt.Workbook()
# 新建sheet
worksheet = new_workbook.add_sheet('new_test')
# 新建单元格,并写入内容-行列
worksheet.write(1, 2, 'test')
# 保存
new_workbook.save('test.xls')
?
?1.2??xlutils设置格式
xlutils整体没有pandas设置来的方便
from xlutils.copy import copy
import xlrd
import xlwt
# 安装:pip install xlutils
tem_excel = xlrd.open_workbook('日统计.xls', formatting_info=True) #格式信息打开
tem_sheet = tem_excel.sheet_by_index(0)
new_excel = copy(tem_excel)
new_sheet = new_excel.get_sheet(0)
style = xlwt.XFStyle()
# 字体
font = xlwt.Font()
font.name = '微软雅黑'
font.bold = True
# 18*20
font.height = 360
style.font = font
# 边框:细线==THIN
borders = xlwt.Borders()
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
style.borders = borders
# 对齐
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_CENTER
alignment.vert = xlwt.Alignment.VERT_CENTER
style.alignment = alignment
new_sheet.write(2, 1, 12)
new_sheet.write(3, 1, 18)
new_sheet.write(4, 1, 19)
new_sheet.write(5, 1, 15)
# new_sheet.write(2, 1, 12, style)
# new_sheet.write(3, 1, 18, style)
# new_sheet.write(4, 1, 19, style)
# new_sheet.write(5, 1, 15, style)
new_excel.save('填写.xls')

?
?1.3 自动生成统计报表【案例一:分数统计】

import xlrd
import xlwt
# 读取excel文件
xlsx = xlrd.open_workbook('三年二班(各科成绩单).xls')
# 选择指定sheet
sheet = xlsx.sheet_by_index(0)
all_data = []
# 统计共有多少学生,并去重
num_set = set()
for row_i in range(1, sheet.nrows):
num = sheet.cell_value(row_i, 0)
name = sheet.cell_value(row_i, 1)
grade = sheet.cell_value(row_i, 3)
student = {
'num': num,
'name': name,
'grade': grade,
}
all_data.append(student)
num_set.add(num)
# print(all_data)
# print(len(all_data))
# print(len(num_set))
# 计算总分
sum_list = []
for num in num_set:
name = ''
sum = 0
for student in all_data:
# print(student['num'])
# print(num)
if num == student['num']:
sum += student['grade']
name = student['name']
sum_stu = {
'num': num,
'name': name,
'sum': sum
}
sum_list.append(sum_stu)
print(sum_list)
# 写入新的excel
# 新建工作簿
new_workbook = xlwt.Workbook()
# 新建sheet
worksheet = new_workbook.add_sheet('2班')
# 新建单元格,并写入内容
# 写入第一列的内容
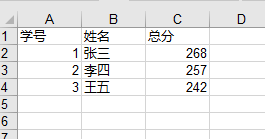
worksheet.write(0, 0, '学号')
worksheet.write(0, 1, '姓名')
worksheet.write(0, 2, '总分')
# 自动写入后面的内容
for row in range(0,len(sum_list)):
worksheet.write(row+1,0,sum_list[row]['num'])
worksheet.write(row+1,1,sum_list[row]['name'])
worksheet.write(row+1,2,sum_list[row]['sum'])
# 保存
new_workbook.save('2班学生总分.xls')
?1.4?xlsxwriter 和openpyxl
xlwt会遇到不支持超过列256的表格
# import xlwt
#
# workbook = xlwt.Workbook()
# sheet0 = workbook.add_sheet('sheet0')
# for i in range(0,300):
# sheet0.write(0,i,i)
# workbook.save('num.xls')
# 不带格式
import xlsxwriter as xw
workbook = xw.Workbook('number.xlsx')
sheet0 = workbook.add_worksheet('sheet0')
for i in range(0,300):
sheet0.write(0,i,i)
workbook.close()
# 性能不稳定
import openpyxl
workbook = openpyxl.load_workbook('number.xlsx')
sheet0 = workbook['sheet0']
sheet0['B3']= '2'
sheet0['C2']= '4'
sheet0['D7']= '3'
workbook.save('num_open.xlsx')1.5 xlwings和pandas
pandas在第一期已经详细讲解过,参考相关文章
Python用来处理Excel的全部可用库,以及它们的优缺点
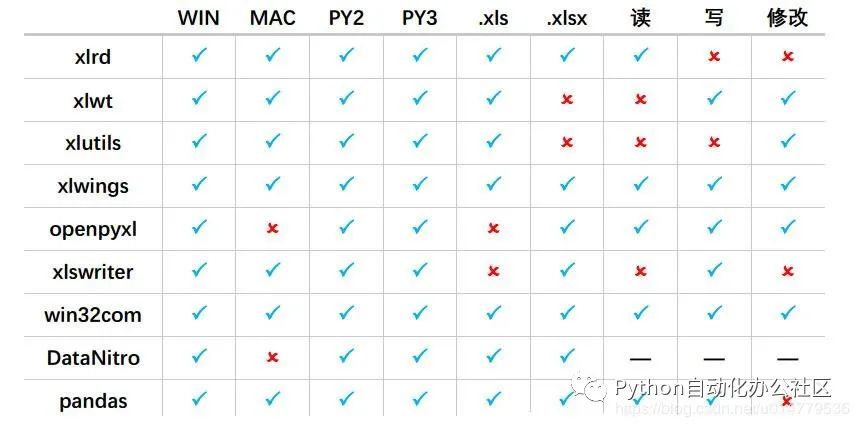
xlwings具有以下优点:
- xlwings能够非常方便的读写Excel文件中的数据,并且能够进行单元格格式的修改
- 可以和matplotlib以及pandas无缝连接
- 可以调用Excel文件中VBA写好的程序,也可以让VBA调用用Python写的程序。
- 开源免费,一直在更新
#### 1、打开/新建Excel文档
```python
import xlwings as xw
wb = xw.Book() # 新建一个文档
wb = xw.Book('test.xlsx') # 打开一个已有的文档
```
#### 2、读取/写入数据
```python
sht = wb.sheets['Sheet1'] # 找到指定sheet
print(sht.range('A1').value) # 读取指定单元格的数据,这里读的是A1
sht.range('B1').value = 10 # 给指定的空白单元格赋值,这里赋值的是B1
```
#### 3、保存文件、退出程序
```python
wb.save(r'test.xlsx') #保存Excel文档,命名为test.xlsx,并保存在D盘
wb.close() # 退出程序,该步骤不可省略
```
#### 4、连接pandas处理复杂数据
```python
import pandas as pd
df = pd.DataFrame([[1,2], [3,4]], columns=['a', 'b'])
sht.range('A1').value = df
sht.range('A1').options(pd.DataFrame, expand='table').value
```
#### 5、连接**Matplotlib** 画图
```python
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot([1, 2, 3, 4, 5])
sht.pictures.add(fig, name='MyPlot', update=True)1.6 案例实战---把文件名整理到excel中
import os
import xlwt
# 目标文件夹
file_path = 'd:/'
# 取出目标文件夹下的文件名
os.listdir(file_path)
new_workbook = xlwt.Workbook()
sheet = new_workbook.add_sheet('new_dir')
n = 0
for i in os.listdir(file_path):
sheet.write(n,0,i)
n+=1
new_workbook.save('dir.xls')1.7? 案例实战---excel填充画
把一幅画导入到excel中用每个单元格背景色生成原画
# coding: utf-8
from PIL import Image
from xlsxwriter.workbook import Workbook
class ExcelPicture(object):
FORMAT_CONSTRAINT = 65536
def __init__(self, pic_file, ratio=0.5):
self.__pic_file = pic_file
self.__ratio = ratio
self.__zoomed_out = False
self.__formats = dict()
# 缩小图片
def zoom_out(self, _img):
_size = _img.size
_img.thumbnail((int(_img.size[0] * self.__ratio), int(_img.size[1] * self.__ratio)))
self.__zoomed_out = True
# 对颜色进行圆整
def round_rgb(self, rgb, model):
return tuple([int(round(x / model) * model) for x in rgb])
# 查找颜色样式,去重
def get_format(self, color):
_format = self.__formats.get(color, None)
if _format is None:
_format = self.__wb.add_format({'bg_color': color})
self.__formats[color] = _format
return _format
# 操作流程
def process(self, output_file='_pic.xlsx', color_rounding=False, color_rounding_model=5.0):
# 创建xlsx文件,并调整行列属性
self.__wb = Workbook(output_file)
self.__sht = self.__wb.add_worksheet()
self.__sht.set_default_row(height=9)
self.__sht.set_column(0, 5000, width=1)
# 打开需要进行转换的图片
_img = Image.open(self.__pic_file)
print('Picture filename:', self.__pic_file)
# 判断是否需要缩小图片尺寸
if self.__ratio < 1:
self.zoom_out(_img)
# 遍历每一个像素点,并填充对应的颜色到对应的Excel单元格
_size = _img.size
print('Picture size:', _size)
for (x, y) in [(x, y) for x in range(_size[0]) for y in range(_size[1])]:
_clr = _img.getpixel((x, y))
# 如果颜色种类过多,则需要将颜色圆整到近似的颜色上,以减少颜色种类
if color_rounding: _clr = self.round_rgb(_clr, color_rounding_model)
_color = '#%02X%02X%02X' % _clr
self.__sht.write(y, x, '', self.get_format(_color))
self.__wb.close()
# 检查颜色样式种类是否超出限制,Excel2007对样式数量有最大限制
format_size = len(self.__formats.keys())
if format_size >= ExcelPicture.FORMAT_CONSTRAINT:
print('Failed! Color size overflow: %s.' % format_size)
else:
print('Success!')
print('Color: %s' % format_size)
print('Color_rounding:', color_rounding)
if color_rounding:
print('Color_rounding_model:', color_rounding_model)
if __name__ == '__main__':
r = ExcelPicture('test.jpg', ratio=0.5)
r.process('0407.xlsx', color_rounding=True, color_rounding_model=5.0)
# 同级目录
效果如下:
 原图
原图
下面可以看到有一点糊是因为填充单元格可以当作像素点来考虑

?
?2.自动化处理word
安装库
>pip install python-docx- python-docx
? ? - 说明文档:https://python-docx.readthedocs.io/en/latest/#api-documentation
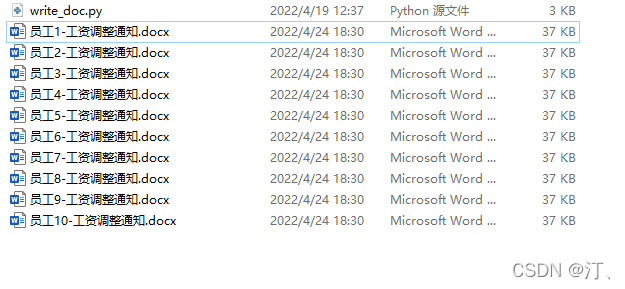
2.1 自动生成word【批量化写模板文档】

from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
from docx.oxml.ns import qn
import time
price = input('请输入工资调整金额:')
# 全体员工姓名
company_list = ['员工1', '员工1', '员工2', '员工3', '员工4',
'员工5', '员工6', '员工7', '员工8', '员工9', '员工10']
# word和excel可以结合
# excel学习:for
# 当天的日期!
today = time.strftime("%Y{y}%m{m}%d{d}", time.localtime()
).format(y='年', m='月', d='日')
for i in company_list:
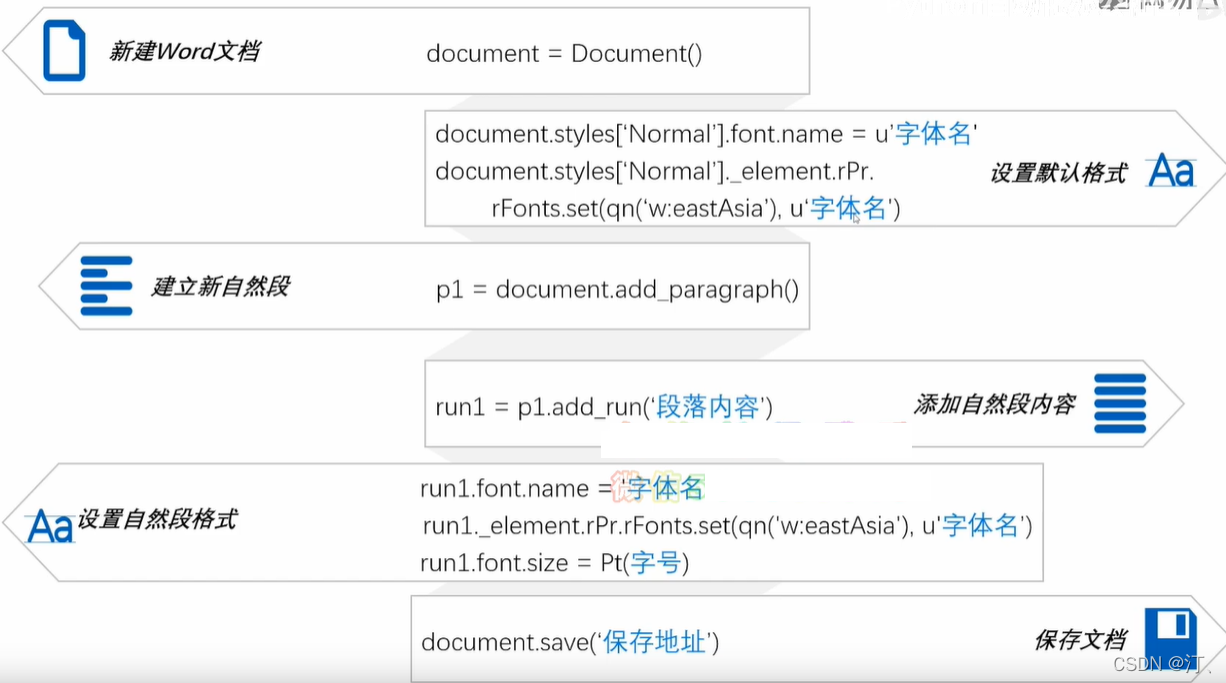
document = Document()
# 设置文档的基础字体
document.styles['Normal'].font.name = u'宋体'
# 识别中文
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 建立一个自然段
p1 = document.add_paragraph()
# 对齐方式为居中,没有这句的话默认左对齐
p1.alignment = WD_ALIGN_PARAGRAPH.CENTER
run1 = p1.add_run('关于%s工资调整的通知' % (today))
run1.font.name = '微软雅黑'
run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')
run1.font.size = Pt(21)
run1.font.bold = True
p1.space_after = Pt(5)
p1.space_before = Pt(5)
p2 = document.add_paragraph()
run2 = p2.add_run(i + ':')
run2.font.name = '宋体'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run2.font.size = Pt(16)
run2.font.bold = True
p3 = document.add_paragraph()
run3 = p3.add_run('因为疫情影响,我们很抱歉的通知您,您的工资调整为每月%s元,特此通知' % price)
run3.font.name = '宋体'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run3.font.size = Pt(14)
p4 = document.add_paragraph()
p4.alignment = WD_ALIGN_PARAGRAPH.RIGHT
run4 = p4.add_run('人事:王小姐 电话:686868')
run4.font.name = '宋体'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run4.font.size = Pt(14)
run4.font.bold = True
document.save('%s-工资调整通知.docx' % i)
其中在读取员工信息这块可以和excel结合。

?
2.2?批量化写模板文档【并添加图片和表格】
新的要求,要求小杨在通知函上方加上图片红头,价格数据以表格形式展示。并在第二页加
上广告【插入分页符】。
效果如下:

from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
from docx.oxml.ns import qn
from docx.shared import Inches
import time
price = input('请输入工资调整金额:')
company_list = ['员工1', '员工1', '员工2', '员工3', '员工4',
'员工5', '员工6', '员工7', '员工8', '员工9', '员工10', ]
today = time.strftime("%Y{y}%m{m}%d{d}", time.localtime()
).format(y='年', m='月', d='日')
for i in company_list:
document = Document()
# 设置文档的基础字体
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 红头文件加入文件
document.add_picture('title002.jpg', width=Inches(6))
# 建立一个自然段
p1 = document.add_paragraph()
# 对齐方式为居中,没有这句的话默认左对齐
p1.alignment = WD_ALIGN_PARAGRAPH.CENTER
run1 = p1.add_run('关于%s工资调整的通知' % (today))
run1.font.name = '微软雅黑'
run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')
run1.font.size = Pt(21)
run1.font.bold = True
p1.space_after = Pt(5)
p1.space_before = Pt(5)
p2 = document.add_paragraph()
run2 = p2.add_run(i + ':')
run2.font.name = '宋体'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run2.font.size = Pt(16)
run2.font.bold = True
p3 = document.add_paragraph()
run3 = p3.add_run('因为疫情影响,我们很抱歉的通知您,您的工资调整为每月%s元,特此通知。' % price)
run3.font.name = '宋体'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run3.font.size = Pt(14)
#添加表格
table = document.add_table(rows=2, cols=2, style='Table Grid')#默认格式
# 合并单元格
table.cell(0, 0).merge(table.cell(0, 1)) #坐上合并到右下
table_run1 = table.cell(0, 0).paragraphs[0].add_run('签名栏')
table_run1.font.name = '黑体'
table_run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'黑体')
table.cell(0, 0).paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
table.cell(1, 0).text = i
table.cell(1, 0).paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
p4 = document.add_paragraph()
p4.alignment = WD_ALIGN_PARAGRAPH.RIGHT
run4 = p4.add_run('人事:王小姐 电话:686868')
run4.font.name = '宋体'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run4.font.size = Pt(14)
run4.font.bold = True
#插入分页符
document.add_page_break()
p5= document.add_paragraph()
run4=p5.add_run("此处是广告")
document.save('%s-工资调整通知.docx' % i)
2.3 读取word文档【?文字+表格混合文档:】
from docx import Document
document = Document('pure.docx')
all_paragraphs = document.paragraphs
for p in all_paragraphs:
print(p.text)
# excel写入
?如果word里是表格呈现读取如下:


?文字+表格形式:
word基本格式问题:把word重名后缀为zip的文件,打开看到里面有xml的格式文件

?导入zipfile库解压文件,设置格式只读取我们需要的文字:进行组合。
![]()
import zipfile
word_book = zipfile.ZipFile('word_table.docx')
xml = word_book.read("word/document.xml").decode('utf-8')
# print(xml)
xml_list = xml.split('<w:t>')
# print(xml_list)
text_list = []
for i in xml_list:
if i.find('</w:t>') + 1:
text_list.append(i[:i.find('</w:t>')])
else:
pass
text = "".join(text_list)
print(text)
2.4 word转pdf(批量化)
安装库:
pip install pywin32from win32com.client import Dispatch,constants,gencache
doc_path = 'test.docx'
pdf_path = 'test.pdf'
gencache.EnsureModule('{00020905-0000-0000-C000-000000000046}',0,8,4)
wd = Dispatch("Word.Application")
doc = wd.Documents.Open(doc_path,ReadOnly=1)
doc.ExportAsFixedFormat(pdf_path,constants.wdExportFormatPDF,
Item=constants.wdExportDocumentWithMarkup,
CreateBookmarks=constants.wdExportCreateHeadingBookmarks)
wd.Quit(constants.wdDoNotSaveChanges)在执行时报错了,下面来说解决方法。
参考网站:win32api pywin32 安装后出现 ImportError: DLL load failed_mengfanteng的博客-CSDN博客
- 找到我们安装python的文件夹,在Lib文件中找到site-packages\pywin32_system32
- D:\Program Files (x86)\Python\Python36\Lib\site-packages\pywin32_system32
- 把里面的所有的文件复制到:C:\Windows\System32
import os
from win32com.client import Dispatch,constants,gencache
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt
from docx.oxml.ns import qn
import time
price = input('请输入工资调整金额:')
# 全体员工姓名
company_list = ['员工1', '员工1', '员工2', '员工3', '员工4', '员工5', '员工6', '员工7', '员工8', '员工9', '员工10' ]
# 当天的日期
today = time.strftime("%Y{y}%m{m}%d{d}", time.localtime()).format(y='年', m='月', d='日')
for i in company_list:
document = Document()
# 设置文档的基础字体
document.styles['Normal'].font.name = u'宋体'
# 识别中文
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 建立一个自然段
p1 = document.add_paragraph()
# 对齐方式为居中,没有这句的话默认左对齐
p1.alignment = WD_ALIGN_PARAGRAPH.CENTER
run1 = p1.add_run('关于%s工资调整的通知' % (today))
run1.font.name = '微软雅黑'
run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')
run1.font.size = Pt(21)
run1.font.bold = True
p1.space_after = Pt(5)
p1.space_before = Pt(5)
p2 = document.add_paragraph()
run2 = p2.add_run(i + ':')
run2.font.name = '宋体'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run2.font.size = Pt(16)
run2.font.bold = True
p3 = document.add_paragraph()
run3 = p3.add_run('因为疫情影响,我们很抱歉的通知您,您的工资调整为每月%s元,特此通知' % price)
run3.font.name = '宋体'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run3.font.size = Pt(14)
p4 = document.add_paragraph()
p4.alignment = WD_ALIGN_PARAGRAPH.RIGHT
run4 = p4.add_run('人事:王小姐 电话:686868')
run4.font.name = '宋体'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
run4.font.size = Pt(14)
run4.font.bold = True
document.save('%s-工资调整通知.docx' % i)
doc_path = '%s-工资调整通知.docx' % i
pdf_path = '%s-工资调整通知.pdf' % i
gencache.EnsureModule('{00020905-0000-0000-C000-000000000046}',0,8,4)
wd = Dispatch("Word.Application")
doc = wd.Documents.Open(doc_path,ReadOnly=1)
doc.ExportAsFixedFormat(pdf_path,constants.wdExportFormatPDF,Item=constants.wdExportDocumentWithMarkup,CreateBookmarks=constants.wdExportCreateHeadingBookmarks)
wd.Quit(constants.wdDoNotSaveChanges)
time.sleep(10)3.PDF识别以及读取PDF中文字【pdf合并】
3.1 使用?pdfplumber和PyPDF2
安装库:
pip install pdfplumber
pip install PyPDF2参考文章:
PDFPlumber使用入门_顺其自然~的博客-CSDN博客_pdfplumber
import PyPDF2
import pdfplumber
def extract_content(pdf_path):
# 内容提取,使用 pdfplumber 打开 PDF,用于提取文本
with pdfplumber.open(pdf_path) as pdf_file:
# 使用 PyPDF2 打开 PDF 用于提取图片
pdf_image_reader = PyPDF2.PdfFileReader(open(pdf_path, "rb"))
print(pdf_image_reader.getNumPages())
content = ''
# len(pdf.pages)为PDF文档页数,一页页解析
for i in range(len(pdf_file.pages)):
print("当前第 %s 页" % i)
# pdf.pages[i] 是读取PDF文档第i+1页
page_text = pdf_file.pages[i]
# page.extract_text()函数即读取文本内容
page_content = page_text.extract_text()
if page_content:
content = content + page_content + "\n"
print(page_content)
extract_content('静夜思.pdf')合并pdf
from PyPDF2 import PdfFileReader, PdfFileWriter
def merge_pdfs(paths, output):
pdf_writer = PdfFileWriter()
for path in paths:
pdf_reader = PdfFileReader(path)
for page in range(pdf_reader.getNumPages()):
# 把每张PDF页面加入到这个可读取对象中
pdf_writer.addPage(pdf_reader.getPage(page))
# 把这个已合并了的PDF文档存储起来
with open(output, 'wb') as out:
pdf_writer.write(out)
if __name__ == '__main__':
paths = ['静夜思.pdf', '静夜思.pdf']
merge_pdfs(paths, output='pandas官方文档中文版.pdf')from PyPDF2 import PdfFileReader, PdfFileWriter
def merge_pdfs(paths, output):
pdf_writer = PdfFileWriter()
for path in paths:
pdf_reader = PdfFileReader(path)
for page in range(pdf_reader.getNumPages()):
# 把每张PDF页面加入到这个可读取对象中
pdf_writer.addPage(pdf_reader.getPage(page))
# 把这个已合并了的PDF文档存储起来
with open(output, 'wb') as out:
pdf_writer.write(out)
if __name__ == '__main__':
paths = ['study.pdf', 'labuladong的算法小抄官方完整版.pdf']
merge_pdfs(paths, output='pandas官方文档中文版.pdf')3.2 pdfminer(推荐)
读取:

?4.ppt自动化操作
?python-pptx说明文档
? ? - https://pypi.org/project/python-pptx/
# pip install python-pptx4..1在ppt中写入文字
from pptx import Presentation
from pptx.util import Inches,Pt
ppt = Presentation()
slide = ppt.slides.add_slide(ppt.slide_layouts[1])# 在PPT中插入一个幻灯片
body_shape = slide.shapes.placeholders
# body_shape[0].text = '这是占位符0'
# body_shape[1].text = '这是占位符1'
#
title_shape = slide.shapes.title
title_shape.text = '这是标题'
# subtitle = slide.shapes.placeholders[1] #取出本页第二个文本框
# subtitle.text = '这是文本框'
#
# new_paragraph = body_shape[1].text_frame.add_paragraph()
# new_paragraph.text = '新段落'
# new_paragraph.font.bold = True
# new_paragraph.font.italic = True
# new_paragraph.font.size = Pt(15)
# new_paragraph.font.underline = True
#
left = Inches(2)
top = Inches(2)
width = Inches(3)
height = Inches(3)
#
#
#
textbox = slide.shapes.add_textbox(left,top,width,height)
textbox.text = 'new textbox'
# 如何在文本框里添加第二段文字?
# new_para = textbox.text_frame.add_paragraph()
# new_para.text = '第二段文字'
#
ppt.save('test.pptx')4.2 在ppt插入图片表格
# pip install python-pptx
from pptx import Presentation
from pptx.util import Inches,Pt
ppt = Presentation()
slide = ppt.slides.add_slide(ppt.slide_layouts[1])# 在PPT中插入一个幻灯片
left = Inches(1)
top = Inches(1)
width = Inches(2)
height = Inches(2)
img = slide.shapes.add_picture('img.jpg',left,top,width,height)
rows = 2
cols = 2
left = Inches(1)
top = Inches(1)
width = Inches(4)
height = Inches(4)
table = slide.shapes.add_table(rows,cols,left,top,width,height).table
table.columns[0].width = Inches(1)
table.columns[1].width = Inches(3)
table.cell(0,0).text = '00'
table.cell(0,1).text = '01'
table.cell(1,0).text = '10'
table.cell(1,1).text = '11' #二进制的11,代表十进制的多少?
ppt.save('text.pptx')


