гявхЗжИюЭјТчЗЂеЙзлЪі
ИХРР
БОЮФвд HRNet ТлЮФ ЮЊжї,НщЩмгявхЗжИюЯрЙиЙЄзї,ОпЬхПЩЗжЮЊ:
- бЇЯАЕЭЗжБцТЪБэЪО:FCNЁЂDeeplabЯЕСаЁЂPSPNet
- ЛжИДИпЗжБцТЪБэЪО:U-Net,Hourglass,SegNet,DeconvNet
ЦфжаHourglassКЭU-NetЯрЫЦ,DeconvNetгыSegNetЯрЫЦ,ВЛЕЅЖРНщЩм - ИпЕЭЗжБцТЪВЂаабЇЯА:HRNet
вЛЁЂбЇЯАЕЭЗжБцТЪБэЪО
FCN
ГіЗЂЕу
- LeNetЁЂAlexNetЁЂVGGNetЁЂGoogLeNetжївЊгУгкЗжРр,ОпгаЦНвЦВЛБфад(translation invariance)
- етаЉЭјТчашвЊЙЬЖЈЕФЪфШы
ДДаТЕу
- НЋКѓУцЕФШЋСЌНгВуЛЛГЩОэЛ§Ву,ЪЕЯжУмМЏдЄВт,гУгкгявхЗжИюЁЃЦфжаОэЛ§ВуВЩгУЗДОэЛ§Ву(backwards convolution / deconvolution),гЩЫЋЯпадВюжЕШЈжЕГѕЪМЛЏЗДОэЛ§КЫЁЃКѓУцЛсДѓжТНщЩмЗДОэЛ§ВйзїЁЃ
- ВЩгУЬјНгНсЙЙ,ШкКЯЩюВу(АќКЌСЫЗжРраХЯЂ)гыжаВу(АќКЌСЫЮЛжУаХЯЂ)ЕФЬиеї,ЬсЩ§ЪфГіЕФЬиеїзМШЗТЪ
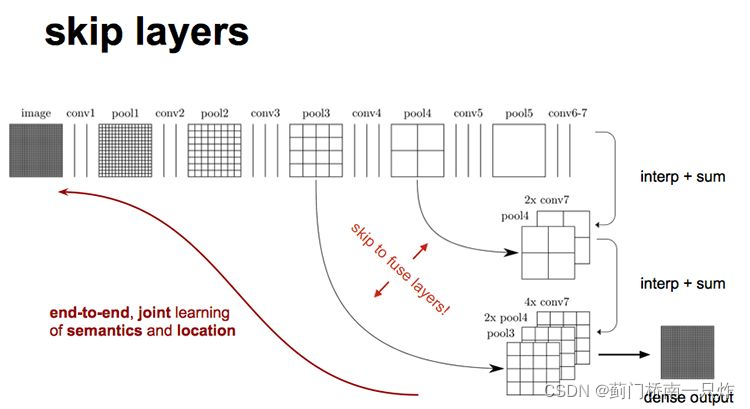
ЗДОэЛ§
ЙигкЗДОэЛ§ЕФЯъЯИЫЕУї,ПЩВщПДЮвЕФСэвЛЦЊВЉПЭЗДОэЛ§ЕФРэНтЁЃ
Deeplab-v1
НсЙЙ
ЛљгкVGGNet,дкFCNЛљДЁЩЯаоИФ,ЮФеТУЛгазмЬхНсЙЙЭМ,ЯТУцЗХVGGNetНсЙЙ
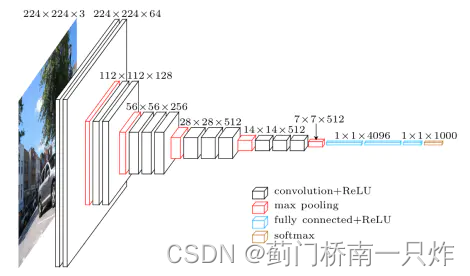
ДДаТЕу
-
НЋзюКѓСНИіmaxpoolingЕФstrideгЩ2ИФЮЊ1,ЬсИпЪфГіЗжБцТЪ
-
НЋЩЯЪіpoolingВуКѓУцЕФОэЛ§ВуИФГЩПеЖДОэЛ§,ЬсИпИаЪмвА
pooling+ЦеЭЈОэЛ§КЭПеЖДОэЛ§ЖМФмдіМгИаЪмвА,ВЛЭЌЕФЪЧЧАепЕФОэЛ§ЫљзїгУЕФЪфШыЬиеїЭМЗжБцТЪИќЕЭ,ЖјПеЖДОэЛ§ЮоаыНЕЕЭЬиеїЭМЗжБцТЪ,вђЖјФмЙЛЬсИпЬиеїУмЖШ
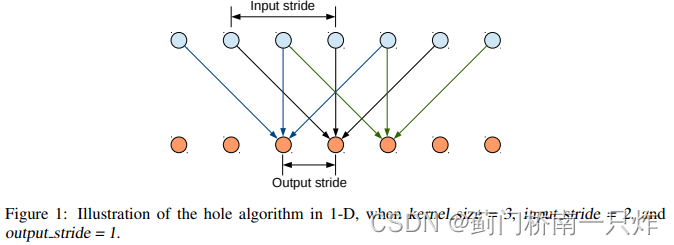
-
НсКЯCRFs,ЛжИДЯИНкТжРЊ
гыFCNЯрБШ
- ВЛашвЊПЩбЇЯАЕФЩЯВЩбљВЮЪ§
Deeplab-v2
ДДаТЕу
- backboneЛЛГЩResNet-101
- ВЩгУПеЖДПеМфН№зжЫўГиЛЏASPP
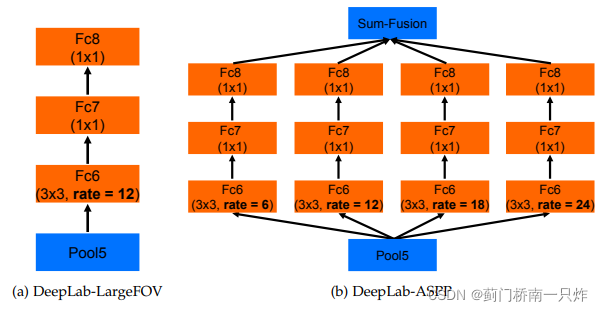
Deeplab-v3
ДДаТЕу
-
МгЩюЭјТч(діМгЭјТчЩюЖШ)
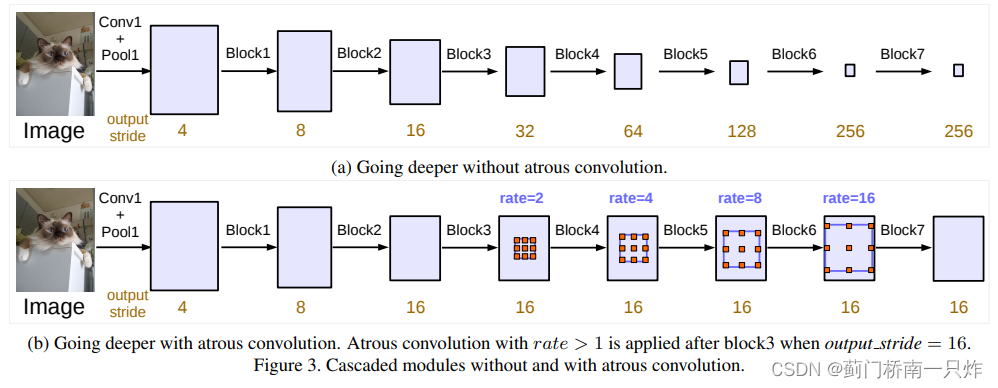
ИДжЦResNetЕк4ИіBlock,ВЩгУВЛЭЌrateЕФПеЖДОэЛ§НјааМЖСЊ,МћЯТЭМЁЃ
-
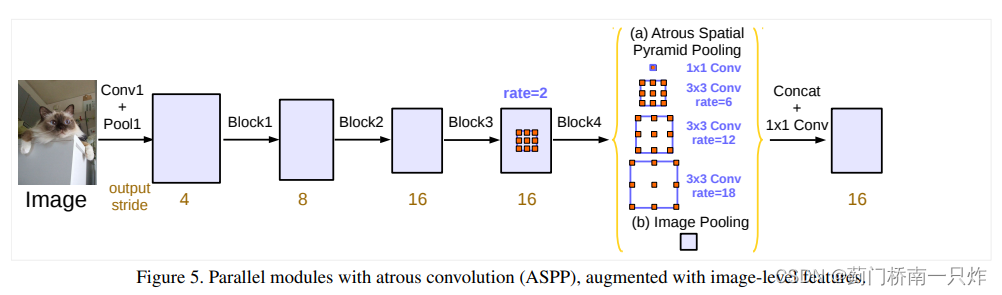
ИФНјЕФASPP(діМгЭјТчПэЖШ,ЯрБШгкЕквЛЕу,етвЛЕудкКѓајЙЄзїжагУЕФИќЖр)
a. ЫцзХПеЖДОэЛ§rateдіДѓ,гааЇЕФОэЛ§КЫШЈжиБфЩй,вђЖјдіМг1ЁС1ОэЛ§
b. ЮЊСЫдіМгШЋОжаХЯЂ,ЖдЩЯВуЪфГіЬиеїЭМНјааПеМфЦНОљГиЛЏ
c. НЋетМИИіЗжжЇдкЭЈЕРЮЌЖШЩЯЦДНгКѓНгШы1ЁС1ОэЛ§Ву,ШкКЯИїЗжжЇЬиеї
-
вЦГ§CRF
Deeplab-v3.5
ДДаТЕу
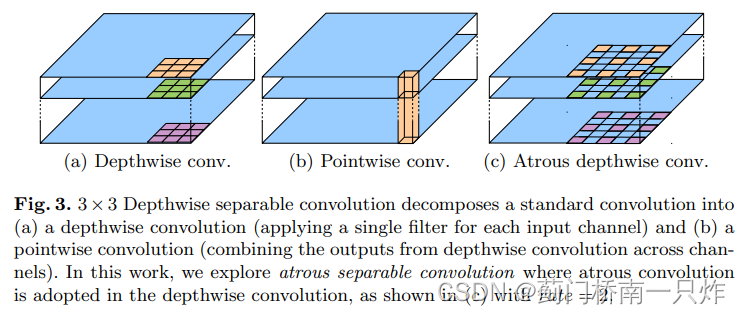
- ЬсГіDepthwise separable convolution,гЩdepthwise convolutionКЭpointwise convolutionзщГЩ,ШчЯТЭМжа(a)КЭ(b)ЁЃетСНжжОэЛ§ЗжБ№ЬсШЁПеМфКЭЭЈЕРаХЯЂ,ДѓДѓМѕЩйВЮЪ§СПКЭМЦЫуСПЁЃЦфжаdepthwise convolutionгЩПеЖДОэЛ§ЬцЛЛ,ШчЯТЭМжа?
- ЬсГіencoder-decoderНсЙЙ,ЪЕМЪЩЯЪЧдкЭјТчКѓУцдіМгСЫвЛаЉНсЙЙ,ШкКЯжаВуаХЯЂ,ВЩгУЫЋЯпадВюжЕЩЯВЩбљвдЛжИДЗжБцТЪ
- аоИФXception
a. ИќЩюЕФXception
b. ЫљгаЕФГиЛЏВуЬцЛЛЮЊДјВНГЄЕФdepthwise separable convolution
c. дкЫљга3ЁС3ОэЛ§КѓУцНгЩЯBNКЭReLU,НшМјгкBobileNet

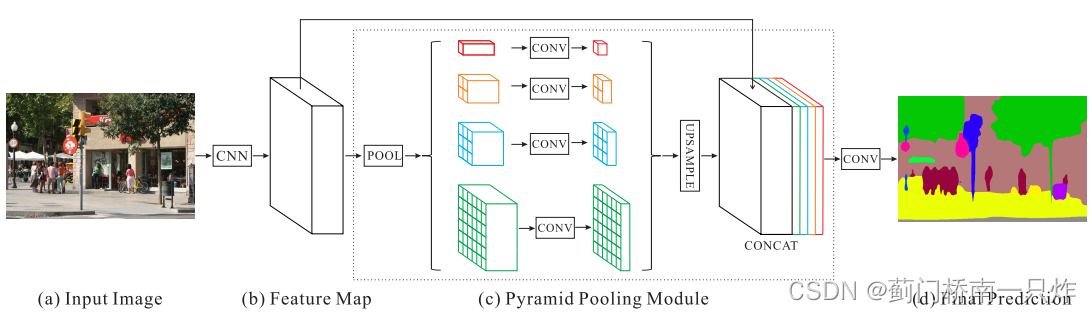
PSPNet
ДДаТЕу
- ЬсГіПеМфН№зжЫўГиЛЏ(SSP)
a. ОЙ§4ИіВЛЭЌГпЖШЕФГиЛЏ
b. 1ЁС1ОэЛ§НЕЕЭЭЈЕРЪ§ЮЊдРДЕФ1/4
c. ЫЋЯпадВюжЕЩЯВЩбљвдЛжИДЪфШыЗжБцТЪ
d. КЭЪфШыЬиеїЭМКЯВЂ
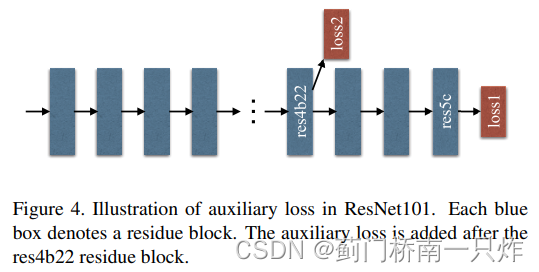
- діМгИЈжњloss
ФмЙЛгХЛЏбЇЯАЙ§ГЬ,ЮФеТКУЯёУЛОпЬхЫЕЪЧЪВУДlossЁЃ
ЖўЁЂЛжИДИпЗжБцТЪБэЪО
U-Net
ЭјТчНсЙЙ
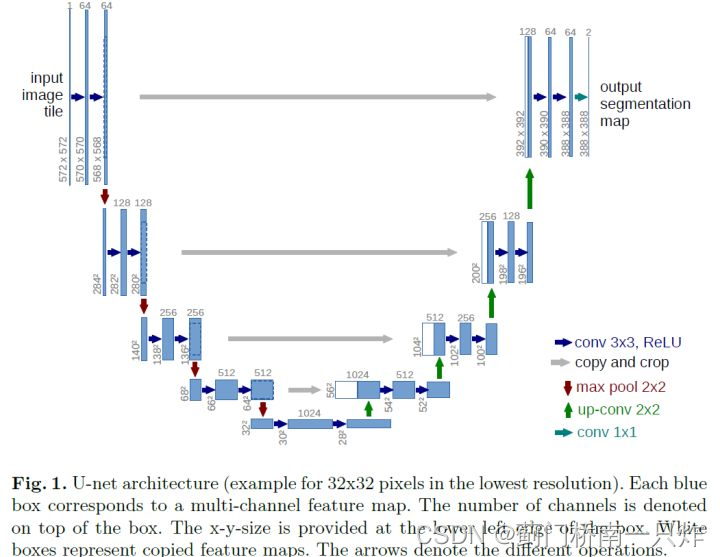
ДДаТЕу
- ВЩгУЗДОэЛ§ЩЯВЩбљ
- дкdecoderжаШкКЯencoderжаЖдгІЕФЬиеїаХЯЂ(ЭЌHourglass)
- ЮоpaddingОэЛ§+Overlap-tileВпТд,вдЪЪХфНЯДѓГпДчЕФЪфШыЭМЯё(вНбЇЭМЯёЕФЬиЕу)
ЕБЭМЯёНЯДѓЪБ,ПЩвдЭЈЙ§ЛЌДАЗНЪНЖдЭМЯёНјааж№ВНдЄВтЁЃЕБЛЌДАДІгкБпНчВПЗжЪБ,ШчЯТгвЭМжаЛЦЩЋВПЗж,ДЫЪБИаЪмвАЮЊРЖЩЋЧјгђ,ЦфжаЕФПеАзВПЗжгЩЛЦЩЋЧјгђОЕЯёРДЬюГф,ШчЯТзѓЭМЫљЪО,ВЛЭЌгкдРДЕФвд0жЕЛђОљжЕРДЬюГфЕФВйзїЁЃ
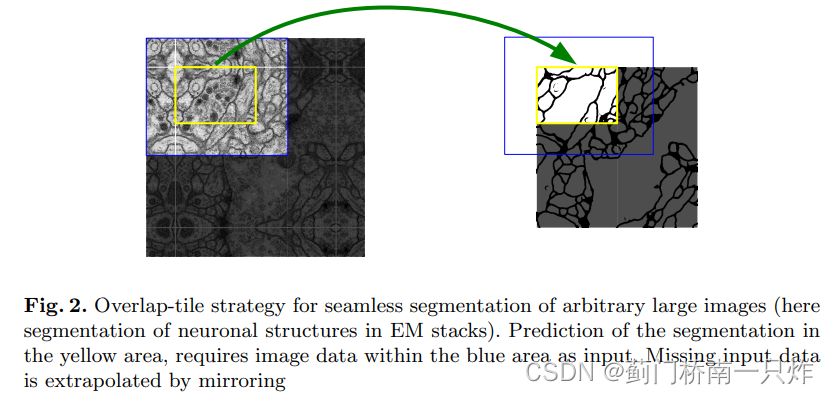
ЬиЕу
ЮЊЪВУДЪЪгУгквНбЇЭМЯё:
- вНбЇЭМЯёЕФЕЭМЖЬиеїЭЌбљКмживЊ,вђДЫашвЊгаU-NetЕФЧГВу-ЩюВуСЌНгНсЙЙ
- вНбЇЭМЯёвЛАуНЯДѓ,ашвЊOverlap-tileВпТд
- вНбЇЭМЯёвЛАубљБОЩй,вђДЫU-NetашвЊЩшМЦГЩЧсСПМЖ
SegNet
ЭјТчНсЙЙ

ДДаТЕу
- ВЩгУPooling IndicesМЧзЁГиЛЏВйзїЪБбЁШЁЕФжЕЕФЮЛжУ,дкЩЯВЩбљЗДГиЛЏВйзїжаНЋжЕЗХШыМЧТМЕФЮЛжУ,ЦфгрЮЛжУжУСуЁЃ(ЭЌ DeconvNet)
гЩгкЭјТчВЩгУЖдГЦЕФencoder-decoderНсЙЙ,вђДЫdecoderжаЕФУПИіЗДГиЛЏВйзїдкencoderжаЖМгагыжЎЖдгІЕФГиЛЏВйзїЁЃЗДГиЛЏКѓЕФЬиеїЭМЪЧЯЁЪшЕФ,ашвЊОЙ§ОэЛ§ВуЗсИЛЦфЬиеїФкШнЁЃ
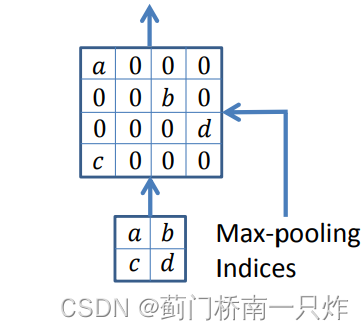
гыU-NetЧјБ№
- дкdecoderВЩгУЗДГиЛЏВйзї,ЖјВЛЪЧНсКЯencoderжаЖдгІЕФЬиеїЭМ
- U-NetУЛгаЪЙгУVGGжаЕФconv5ВПЗж,ЖјSegNetВЩгУСЫШЋВПЕФVGGНсЙЙ
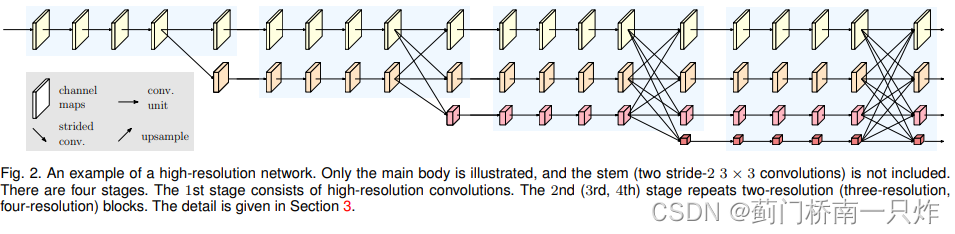
Ш§ЁЂHRNet
НсЙЙ
- Parallel Multi-Resolution Convolutions
ЖрЗжБцТЪВЂааЕФОэЛ§

- Repeated Multi-Resolution Fusions
жиИДЕФЖрЗжБцТЪаХЯЂШкКЯ
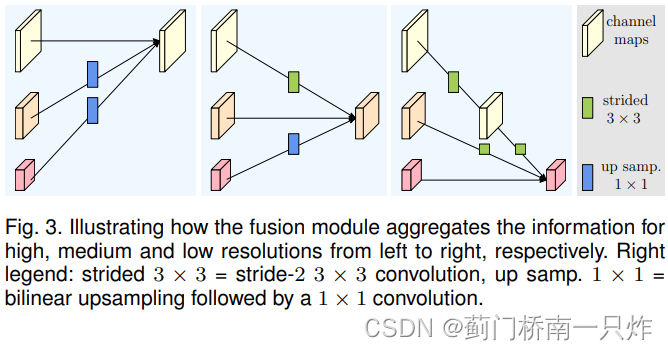
- Representation Head
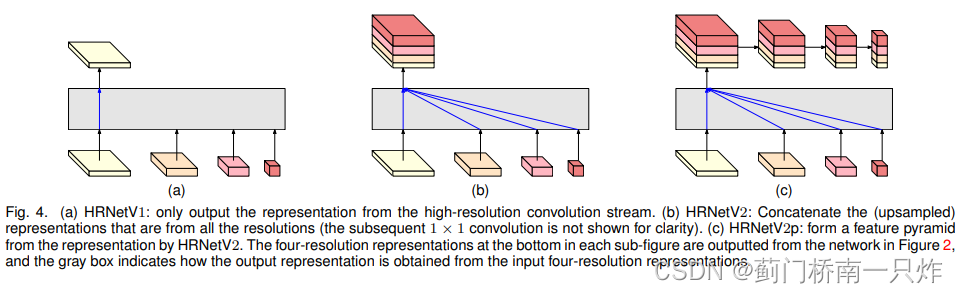
ЯТЭМЗжБ№ЖдгІHRNetV1ЁЂHRNetV2ЁЂHRNetV2pЁЃЗжБ№ЪЪгУгкШЫЬхзЫЬЌЙРМЦЁЂгявхЗжИюКЭФПБъМьВтЁЃЦфжа(b)ЭМжаЕФШкКЯЗНЪНЮЊ:ЕЭЗжБцТЪЭМЫЋЯпадВхжЕЕНИпЗжБцТЪКѓЦДНг,дйОЙ§1ЁС1ОэЛ§ВуШкКЯет4ИіЗжжЇаХЯЂЁЃЖј?ЭМжадђНјвЛВНЖдЪфГіНјааЯТВЩбљ,ЕУЕНЖрИіlevelЕФЪфГіЁЃ
- Instantiation
НЋЧАШ§жжНсЙЙАВзАЕНвЛЦ№,ЕУЕНзюжеЕФHRNetНсЙЙ,ШчЯТЭМЫљЪОЁЃ