Transformer�ǹȸ���2017���һƪ����"Attention is all you need"�����һ��seq2seq��ģ�ͼܹ�,�䴴���Ե��������ע������˼��,���Ժܺõı��������и�������֮����ע������ϵ�����ģ����NLP����ȡ���˾�ijɹ����������ģ�ͼܹ����������Ҳ��CV����ȡ����������Ŀ�Ľ�չ,��ͼ��ʶ��,Ŀ����ȷ��涼�ﵽ��CNNģ�͵����ܡ����Transformer����˵���˹��������������ֵ�ù�ע��ѧϰ��һ���ܹ���Ŀǰ�������Ѿ��кܶ�������ϸ�����Transformer�ļܹ�����ϸ��,�����ҽ������ظ��ⷽ�������,���ǹ�ע��ʵս����,����Tensorflow���һ��Transformerģ��,ʵ�ַ����Ӣ��ķ��롣
��Tensorflow�Ĺ�������һ����ϸ�Ľ̳�,��������δTranformer��ʵ�����������ΪӢ���Ҳ��ѧϰ������̳�֮��,����һЩ����,��ʵ�ֶԷ���-Ӣ��ķ��롣
���ݼ�����
�������վTab-delimited Bilingual Sentence Pairs from the Tatoeba Project (Good for Anki and Similar Flashcard Applications)�����ҵ��ܶͬ��������Ӣ��ķ��롣�����������ط���-Ӣ���������Ϊѵ��������֤��������http://www.manythings.org/anki/fra-eng.zip����ļ�����ѹ֮��,���ǿ��Կ�������ÿһ�ж�Ӧһ��Ӣ����Ӻ�һ���������,�Լ����ӵĹ�����,�м���TAB�ָ���
���´����Ƕ�ȡ�ļ������ݲ��鿴�����Ӣ��ľ���:
fra = []
eng = []
with open('fra.txt', 'r') as f:
content = f.readlines()
for line in content:
temp = line.split(sep='\t')
eng.append(temp[0])
fra.append(temp[1])�鿴��Щ����,���Կ�����Щ���Ӱ��������ַ�,����'Cours\u202f!' ������Ҫ����Щ����IJ��ɼ��ַ�(\u202f, \xa0 ...)ȥ����
new_fra = []
new_eng = []
for item in fra:
new_fra.append(re.sub('\s', ' ', item).strip().lower())
for item in eng:
new_eng.append(re.sub('\s', ' ', item).strip().lower())���ʴ���Ϊtoken
��Ϊģ��ֻ�ܴ�������,��Ҫ����Щ�����Ӣ��ĵ���תΪtoken���������BERT tokenizer�ķ�ʽ������,������Բμ�tensorflow�Ľ̳�Subword tokenizers ?|? Text ?|? TensorFlow
���ȴ�������dataset,�ֱ�����˷����Ӣ��ľ��ӡ�
ds_fra = tf.data.Dataset.from_tensor_slices(new_fra)
ds_eng = tf.data.Dataset.from_tensor_slices(new_eng)����tensorflow��bert_vocab���������ʻ��,���ﶨ����һЩ����token��������Ŀ��,����[START]��ʶ���ӵĿ�ʼ,[UNK]��ʶһ�����ڴʻ�����ֵ��µ��ʡ�
bert_tokenizer_params=dict(lower_case=True)
reserved_tokens=["[PAD]", "[UNK]", "[START]", "[END]"]
bert_vocab_args = dict(
# The target vocabulary size
vocab_size = 8000,
# Reserved tokens that must be included in the vocabulary
reserved_tokens=reserved_tokens,
# Arguments for `text.BertTokenizer`
bert_tokenizer_params=bert_tokenizer_params,
# Arguments for `wordpiece_vocab.wordpiece_tokenizer_learner_lib.learn`
learn_params={},
)
fr_vocab = bert_vocab.bert_vocab_from_dataset(
ds_fra.batch(1000).prefetch(2),
**bert_vocab_args
)
en_vocab = bert_vocab.bert_vocab_from_dataset(
ds_eng.batch(1000).prefetch(2),
**bert_vocab_args
)�ʻ���������֮��,���ǿ��Կ������������Щ����:
print(en_vocab[:10])
print(en_vocab[100:110])
print(en_vocab[1000:1010])
print(en_vocab[-10:])�������,���Կ����ʻ�������ϸ���ÿ��Ӣ�ﵥ�������ֵ�,����'##ers'��ʾij�����������ers��β,��Ữ�ֳ�һ��'##ers'��token
['[PAD]', '[UNK]', '[START]', '[END]', '!', '"', '$', '%', '&', "'"]
['ll', 'there', 've', 'and', 'him', 'time', 'here', 'about', 'get', 'didn']
['##ers', 'chair', 'earth', 'honest', 'succeed', '##ted', 'animals', 'bill', 'drank', 'lend']
['##?', '##j', '##q', '##z', '##��', '##�C', '##��', '##��', '##��', '##�']�Ѵʻ������Ϊ�ļ�,Ȼ�����ǾͿ���ʵ��������tokenizer,��ʵ�ֶԷ����Ӣ����ӵ�token��������
def write_vocab_file(filepath, vocab):
with open(filepath, 'w') as f:
for token in vocab:
print(token, file=f)
write_vocab_file('fr_vocab.txt', fr_vocab)
write_vocab_file('en_vocab.txt', en_vocab)
fr_tokenizer = text.BertTokenizer('fr_vocab.txt', **bert_tokenizer_params)
en_tokenizer = text.BertTokenizer('en_vocab.txt', **bert_tokenizer_params)�������ǿ��Բ���һ�¶�һЩӢ����ӽ���token������Ľ��,����������Ҫ��ÿ�����ӵĿ�ͷ�ͽ�β�ֱ����[START]��[END]�����������token,�������Է����Ժ�ģ�͵�ѵ����
START = tf.argmax(tf.constant(reserved_tokens) == "[START]")
END = tf.argmax(tf.constant(reserved_tokens) == "[END]")
def add_start_end(ragged):
count = ragged.bounding_shape()[0]
starts = tf.fill([count,1], START)
ends = tf.fill([count,1], END)
return tf.concat([starts, ragged, ends], axis=1)
sentences = ["Hello Roy!", "The sky is blue.", "Nice to meet you!"]
add_start_end(en_tokenizer.tokenize(sentences).merge_dims(1,2)).to_tensor()����������:
<tf.Tensor: shape=(3, 7), dtype=int64, numpy=
array([[ 2, 1830, 45, 3450, 4, 3, 0],
[ 2, 62, 1132, 64, 996, 13, 3],
[ 2, 353, 61, 416, 60, 4, 3]])>�������ݼ�
�������ǿ��Թ���ѵ��������֤���ˡ�������Ҫ�ѷ����Ӣ��ľ��Ӷ����������ݼ���,���з��������ΪTransformer������������,Ӣ�������Ϊ�������������Լ�ģ�������Target������������Pandas����һ��Dataframe,�����������80%������Ϊѵ����,����Ϊ��֤����Ȼ��ת��ΪTensorflow��dataset
df = pd.DataFrame(data={'fra':new_fra, 'eng':new_eng})
# Shuffle the Dataframe
recordnum = df.count()['fra']
indexlist = list(range(recordnum-1))
random.shuffle(indexlist)
df_train = df.loc[indexlist[:int(recordnum*0.8)]]
df_val = df.loc[indexlist[int(recordnum*0.8):]]
ds_train = tf.data.Dataset.from_tensor_slices((df_train.fra.values, df_train.eng.values))
ds_val = tf.data.Dataset.from_tensor_slices((df_val.fra.values, df_val.eng.values))
�鿴ѵ�����ľ������������ٸ�token
lengths = []
for fr_examples, en_examples in ds_train.batch(1024):
fr_tokens = fr_tokenizer.tokenize(fr_examples)
lengths.append(fr_tokens.row_lengths())
en_tokens = en_tokenizer.tokenize(en_examples)
lengths.append(en_tokens.row_lengths())
print('.', end='', flush=True)
all_lengths = np.concatenate(lengths)
plt.hist(all_lengths, np.linspace(0, 100, 11))
plt.ylim(plt.ylim())
max_length = max(all_lengths)
plt.plot([max_length, max_length], plt.ylim())
plt.title(f'Max tokens per example: {max_length}');�ӽ���п��Կ���ѵ�����ľ���ת��Ϊtoken��������67��token:
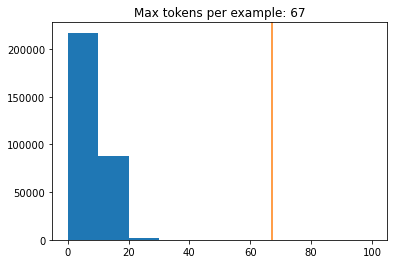
֮��Ϳ���Ϊ���ݼ�����batch,�����´���:
BUFFER_SIZE = 20000
BATCH_SIZE = 64
MAX_TOKENS = 67
def filter_max_tokens(fr, en):
num_tokens = tf.maximum(tf.shape(fr)[1],tf.shape(en)[1])
return num_tokens < MAX_TOKENS
def tokenize_pairs(fr, en):
fr = add_start_end(fr_tokenizer.tokenize(fr).merge_dims(1,2))
# Convert from ragged to dense, padding with zeros.
fr = fr.to_tensor()
en = add_start_end(en_tokenizer.tokenize(en).merge_dims(1,2))
# Convert from ragged to dense, padding with zeros.
en = en.to_tensor()
return fr, en
def make_batches(ds):
return (
ds
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.map(tokenize_pairs, num_parallel_calls=tf.data.AUTOTUNE)
.filter(filter_max_tokens)
.prefetch(tf.data.AUTOTUNE))
train_batches = make_batches(ds_train)
val_batches = make_batches(ds_val)��������һ��batch���鿴һ��:
for a in train_batches.take(1):
print(a)�������,�ɼ�ÿ��batch��������tensor,�ֱ��Ӧ�����Ӣ�����ת��Ϊtoken֮�������,ÿ��������token 2��ͷ,��token 3��β:
(<tf.Tensor: shape=(64, 24), dtype=int64, numpy=
array([[ 2, 39, 9, ..., 0, 0, 0],
[ 2, 62, 43, ..., 0, 0, 0],
[ 2, 147, 70, ..., 0, 0, 0],
...,
[ 2, 4310, 14, ..., 0, 0, 0],
[ 2, 39, 9, ..., 0, 0, 0],
[ 2, 68, 64, ..., 0, 0, 0]])>, <tf.Tensor: shape=(64, 20), dtype=int64, numpy=
array([[ 2, 36, 76, ..., 0, 0, 0],
[ 2, 36, 75, ..., 0, 0, 0],
[ 2, 92, 80, ..., 0, 0, 0],
...,
[ 2, 68, 60, ..., 0, 0, 0],
[ 2, 36, 75, ..., 0, 0, 0],
[ 2, 67, 9, ..., 0, 0, 0]])>)��������������λ����Ϣ
������õ���batch�������뵽embedding��,�Ϳ���ÿ��tokenת��Ϊһ����λ����,����ת��Ϊһ��128ά��������֮��������Ҫ�������������һ��λ����Ϣ�Ա�ʾ���token�ھ����е�λ�á����ĸ�����һ�ֶ�λ����Ϣ���б���ķ���,�����µĹ�ʽ:
��ʽ��pos��ʾ�����λ��,����һ��������50������,posȡֵ��ΧΪ0-49. d_model��ʾembedding��ά��,�����ÿ������ӳ��Ϊһ��128ά������,d_model=128. i��ʾ��128ά�����ά��,ȡֵ��ΧΪ0-127
��˹�ʽ�ĺ���Ϊ,�Ե�N������,����128ά��Ƕ��������,ÿ��ά�ȶ����϶�Ӧ��λ����Ϣ.
�Ե�3������Ϊ��,pos=2, �����Ӧ��128ά����,��ż��ά(0,2,4...)��Ҫ����sin(2/10000^(2i/128)),2i�Ķ�Ӧȡֵ��(0,2,4...). ��2i+1ά(1,3,5...)��Ҫ����cos(2/10000^(2i/128)),2i�Ķ�Ӧȡֵ��(0,2,4...)
���´��뽫����λ�ñ�������,����������Լ��뵽token��Ƕ�������С�
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)����Padding�����look ahead����
Mask���ڱ�ʶ����������Ϊ0��λ��,���Ϊ0,��MaskΪ1. ��������ʹ��padding���ַ�������뵽ģ�͵�ѵ����
Look ahead mask��������Ԥ�����ڸ�δ�����ַ�,���緭��һ�䷨��,��Ӧ��Ӣ����Ŀ������,��ѵ��ʱ,��Ԥ���һ��Ӣ�ﵥ��ʱ,��Ҫ������Ӣ�ﶼ�ڸ�,��Ԥ��ڶ���Ӣ�ﵥ��ʱ,��Ҫ������Ӣ��ĵ�һ������֮��Ķ��ڸǡ����Ŀ���DZ�����ģ�Ϳ���֮��ҪԤ��ĵ���,Ӱ��ģ�͵�ѵ����
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)��ע��������
����������Transformer�ĺ��ĸ�����,������Ҫ�����������,ͨ����������ת���ľ���,������ΪQ,K,V����������
ͨ������Q��K�����������õ�ע����ϵ��,�ٺ�V���,�õ���Ӧ����ֵ,�����µ�ͼƬ:
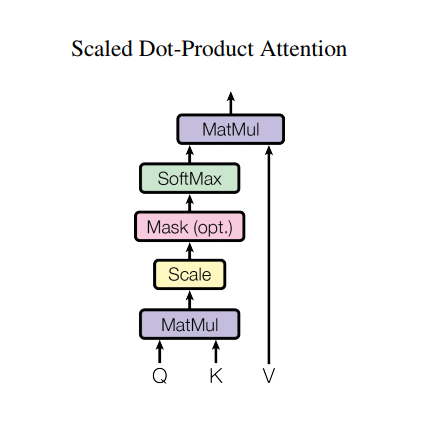
ע����Ȩ�صļ��㹫ʽ����:

