��ʦ������ĺܺ�,һ���Ͷ���
�����2020����ѧϰ���ѧϰ(������)����_��������_bilibili
һ������ܹ�
Transformer��2017��Google������Attention Is All You Need,���ص�ַ:https://arxiv.org/pdf/1706.03762.pdf
Transformer��ѭ������-�������ṹ,�������ͽ��������ֱ�����ͼ��������������ʾ:
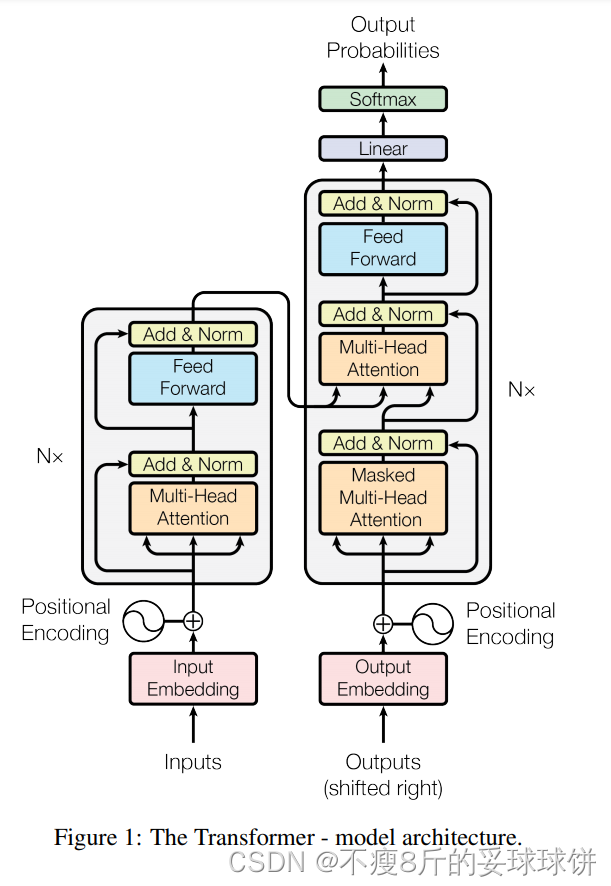
������:��������N = 6����ͬ�IJ���ɡ�ÿһ���������Ӳ㡣��һ������ͷ��ע�����,�ڶ����Ǽ�λ��ȫ�������������߶������Ӳ�ʹ���в�����,���������һ��(LN)��Ҳ����˵,ÿ���Ӳ�������:LayerNorm(x+ Sublayer(x)),����Sublayer(x)���Ӳ㱾��ʵ�ֵĺ�����
������:������Ҳ��N = 6����ͬ����ɡ���ÿ�����������е������Ӳ���,������������������Ӳ�,���Ӳ�Ա����������ִ����ͷע���������������,���߶�ÿ���Ӳ�ʹ���в�����,Ȼ��������һ��(LN)�������ڽ������е���ע���Ӳ��м���mask���������λ��ƫ��,��ȷ��λ�� i ��Ԥ��ֻ������С�� i λ�õ���֪�����
����ע��������
Transformer����������ʹ�ö�ͷע����:
- ����������ע�����,���еļ���ֵ�Ͳ�ѯ������ǰһ����������������е�ÿ��λ�ö����Զ�Ӧ��һ�������λ�á�
- ��������-������ע�����,��ѯǰ��Ľ�������,���ڴ����ֵ���Ա��������������ʹ���������е�ÿ��λ�ö����Բμ����������е�����λ�á�
- ������������ע�����,ͬ�������������е�ÿ��λ�ù�ע��������֮ǰ������λ�á�
Self-attention
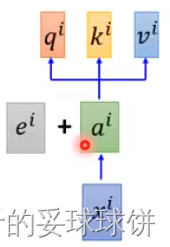
ע�⺯����������Ϊ����ѯ����һ���ֵ��ӳ�䵽���,���в�ѯQ����K��ֵV����������������������ΪֵV�ļ�Ȩ�ͼ����,���з����ÿ��ֵV��Ȩ����ͨ����ѯQ����Ӧ��K�ļ����Ժ�������ġ������Ļ������ҿ�ƪ���ᵽ���������ʦ����Ƶ��
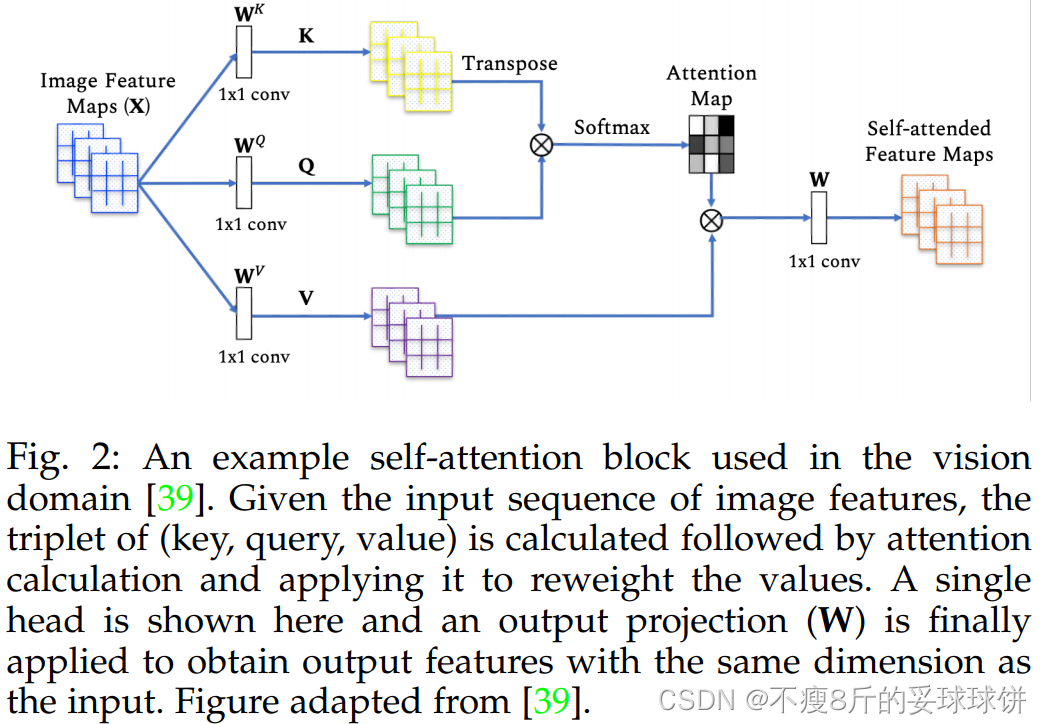
- q:query(to match others)
- k:key(to be matched)
- v:value(information to be extracted)
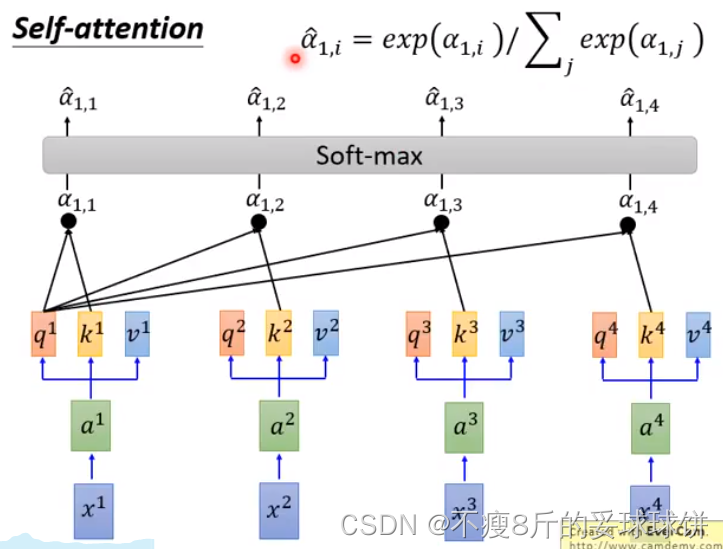
����,��ÿ��query qȥ��ÿ��key k��attention������3ҳPPT������:�����ѯQ�����м�K�ĵ��,ÿ��������?(d��ά��),��Ӧ��softmax��������,�����ֵV��Ȩ����ˡ����Ǽ����������Ϊ:


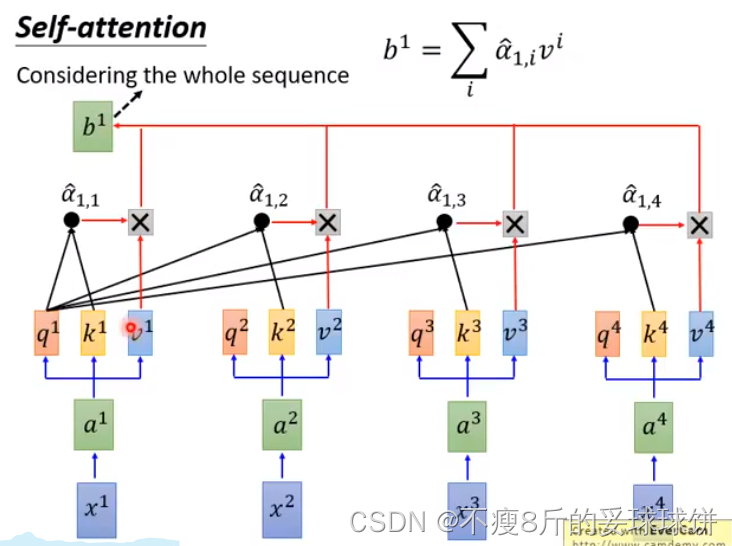
?ͬ������b2...

?�����������������ʾ:

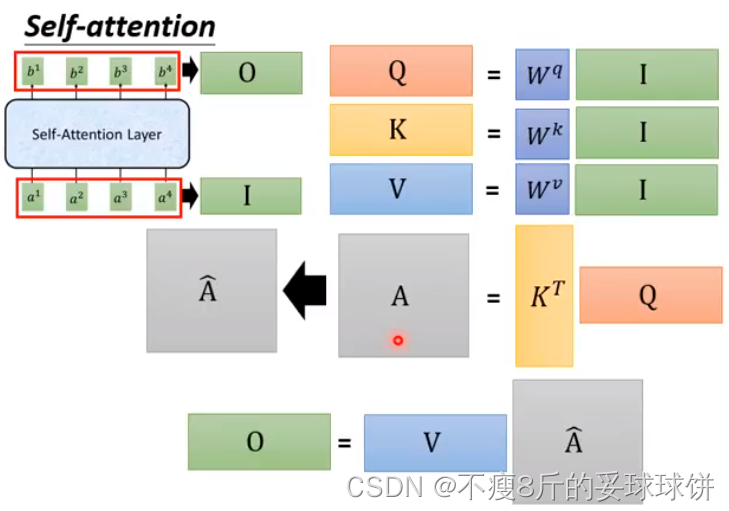
��������һ������˷�,��GPU���Լ��١�
Multi-head Self-attention
��ͬhead���ܹ�ע�ĵ㲻һ����

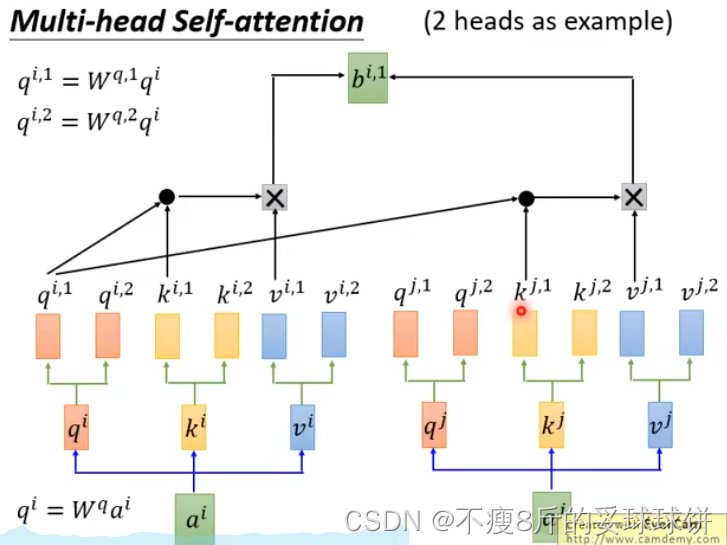
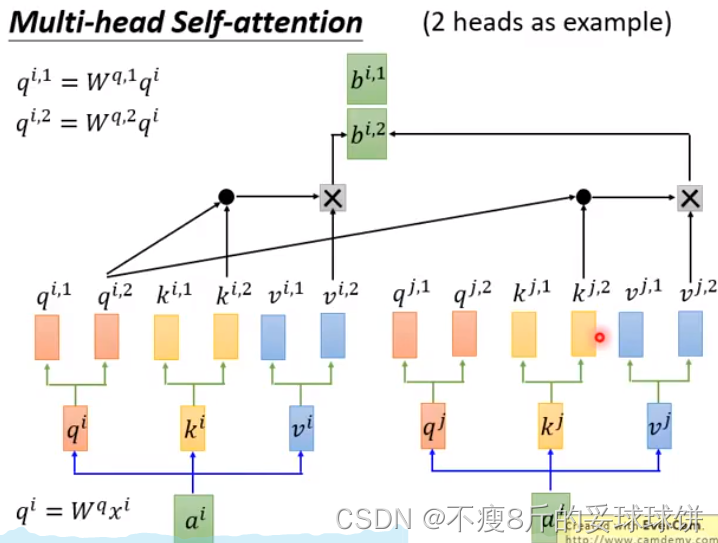
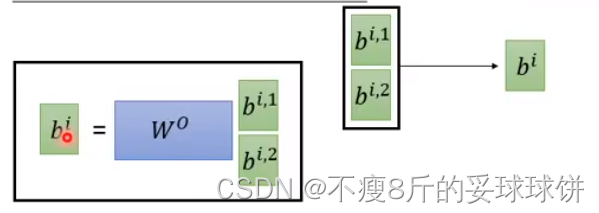
- no position information in self-attention -- input sequence��˳����Ҫ
- origin paper: each position has a unique position vector
?(not learned from data)
�����:
Transformer���Ľ��һ(Transformer)_������BlueWhale�IJ���-CSDN����_transformer����
ʷ����С��֮Transformer���_Stink1995�IJ���-CSDN����_transformer������
Transformer��ʲô?������ƪ��������ඥ_�ޖ��IJ���-CSDN����_transformer��ʲô

