目录
张量视图变换
tf.reshape(?tensor, shape, name=None)
#将2行3列的矩阵变换为2行3列的矩阵
x=[[1,2,3],[4,5,6]]
print(tf.shape(x))
tf.Tensor([2 3], shape=(2,), dtype=int32)
tf.reshape(x,[3,2])
Out[70]:
<tf.Tensor: id=4269, shape=(3, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4],
[5, 6]])>
#将一维向量变换为3行4列的矩阵
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
print(tf.shape(x).numpy())
[12]
tf.reshape(x, [3, 4])
Out[76]:
<tf.Tensor: id=5056, shape=(3, 4), dtype=int32, numpy=
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])>增加维度
tf.expand_dims(input, axis, name=None)
axis插入的维度位置,在....之前插入
维度shape:[2,4,4,8],axis分别对应[0,1,2,3]
#在shape:[2,3]的张量中”3”前插入维度
x = tf.zeros([2,3])
tf.expand_dims(x, axis=1).shape.as_list()
Out[84]: [2, 1, 3]
#在shape:[2,3]的张量中”3”前插入维度
x = tf.zeros([2,3])
tf.expand_dims(x, axis=1).shape.as_list()
Out[84]: [2, 1, 3]删除维度
tf.squeeze(input, axis=None, name=None)
删除维度只能删除为1的维度
x = tf.zeros([1,3,1,4,1])
print(tf.shape(x))
tf.Tensor([1 3 1 4 1], shape=(5,), dtype=int32)
tf.squeeze(x,2)
Out[143]:
<tf.Tensor: id=15243, shape=(1, 3, 4, 1), dtype=float32, numpy=array())
tf.squeeze(x,[0,2])
<tf.Tensor: id=15243, shape=(3, 4, 1), dtype=float32, numpy=array())交换维度
tf.transpose(a, perm=None, conjugate=False, name='transpose')
transpose交换维度将改变张量的存储顺序
图像张量shape:[b,h,w,c]交换到shape:[b,c,h,w]
对于维度索引[0,1,2,3]交换为[0,3,1,2]
#调用函数transpose,将perm设为新的维度索引[0,3,1,2]
x = tf.zeros([1,2,2,3])
tf.transpose(x,[0,3,1,2])
Out[151]:
<tf.Tensor: id=16771, shape=(1, 3, 2, 2), dtype=float32, numpy=
array([[[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]]], dtype=float32)>复制数据
tf.tile(?input, multiples, name=None)
#在列维度上复制1份数据a = tf.constant([[1,2,3],[4,5,6]], tf.int32)
tf.tile(a, [1,2])
Out[156]:
<tf.Tensor: id=17786, shape=(2, 6), dtype=int32, numpy=
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]])>
在行维度上复制1份数据tf.tile(a, [2,1])
Out[157]:
<tf.Tensor: id=17997, shape=(4, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6],
[1, 2, 3],
[4, 5, 6]])>
#在行维度和列维度上各复制1份数据
tf.tile(a, [2,2])
Out[158]:
<tf.Tensor: id=18211, shape=(4, 6), dtype=int32, numpy=
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6],
[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]])>Broadcasting
是一种轻量级的张量复制方法,在逻辑上扩展张量数据的形状,只有在需要计算的时候实际复制数据,相对tf.tile,减少了很多不必要的计算
Broadcasting函数:tf.broadcast_to(input, shape, name=None)
Broadcasting函数实现逻辑:shape右侧对齐,从低维度到高纬度依次处理,维度值相同时默认不变,当其中一个张量的维度值为空或者为1时,维度自动补齐。否则这两个张量不支持Broadcasting,如下图示意
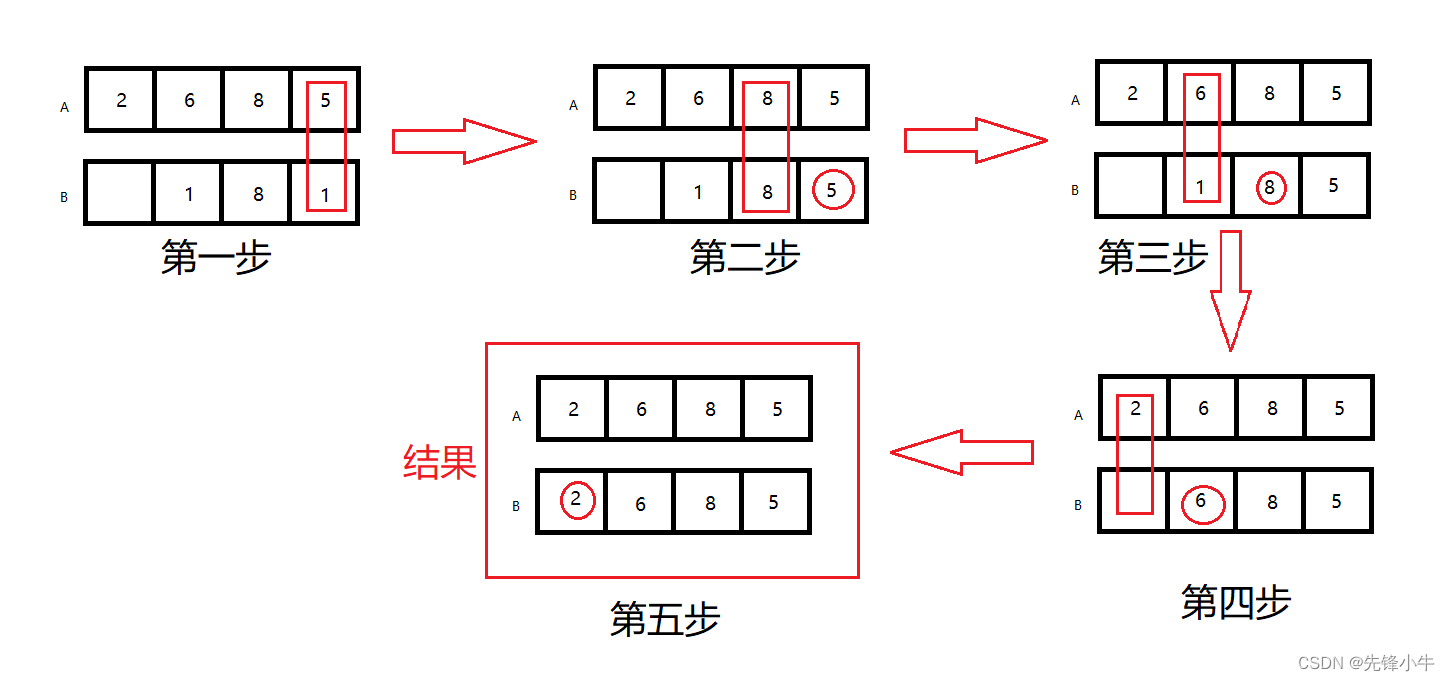
不支持Broadcasting复制的如下图
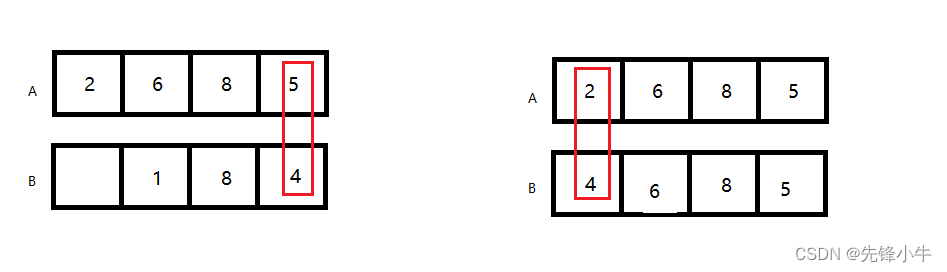
支持Broadcasting
?
?不支持Broadcasting

#将shape为[2, 3]的张量转换为[1, 2, 3]的张量
x = tf.constant([1, 2, 3])
y = tf.broadcast_to(x, [3, 3])
print(y)
tf.Tensor(
[[1 2 3]
[1 2 3]
[1 2 3]], shape=(3, 3), dtype=int32)张量运算
加:tf.add(x, y, name=None)/“+”
减:tf.subtract(x, y, name=None)/“-”
乘:tf.multiply(x, y, name=None)/“*”
除:tf.divide(x, y, name=None)/ “/”
整除:“//”
取余:“%”
乘方:tf.pow(x, a)/“x**a”
矩阵:tf.matmul(a,b)/ “a@b”
张量合并
在现有维度上合并:
tf.concat(values, axis, name='concat') ?注:非合并维度长度必须相同
shape:[2,3,4,6]和shape:[2,6,4,6]的张量只能合并axis=1的维度
在新创建的维度上合并:
tf.stack(values, axis=0, name='stack') 注:张量shape相同才可以合并
shape:[2,3,4]和shape:[2,6,4]的张量不能合并
#张量A,B合并
A = tf.constant([[[1, 2], [2, 3]], [[4, 4], [5, 3]]])
B = tf.constant([[[7, 4], [8, 4]], [[2, 10], [15, 11]]])
tf.concat([A, B], -1)
Out[14]:
<tf.Tensor: id=20, shape=(2, 2, 4), dtype=int32, numpy=
array([[[ 1, 2, 7, 4],
[ 2, 3, 8, 4]],
[[ 4, 4, 2, 10],
[ 5, 3, 15, 11]]])>
#张量A,B,C合并
C = tf.constant([[[20, 21], [22, 23]], [[24, 25], [15, 26]]])
tf.concat([A, B, C], -1)
Out[16]:
<tf.Tensor: id=37, shape=(2, 2, 6), dtype=int32, numpy=
array([[[ 1, 2, 7, 4, 20, 21],
[ 2, 3, 8, 4, 22, 23]],
[[ 4, 4, 2, 10, 24, 25],
[ 5, 3, 15, 11, 15, 26]]])>创建新的维度
tf.stack(values, axis=0, name='stack')
x = tf.constant([1, 4])
y = tf.constant([2, 5])
z = tf.constant([3, 6])
tf.stack([x, y, z])
Out[18]:
<tf.Tensor: id=67, shape=(3, 2), dtype=int32, numpy=
array([[1, 4],
[2, 5],
[3, 6]])>
tf.stack([x, y, z], axis=1)
Out[19]:
<tf.Tensor: id=87, shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]])>张量分割
tf.split(
value, ????????????????#待分割的张量
num_or_size_splits, ??#分割方案
axis=0, ??#维度下标
num=None, name='split'
)
num_or_size_splits为整数时表示平均分割,维度大小必须能整除num_or_size_splits
num_or_size_splits为列表时根据自定义的大小分割
x = tf.Variable(tf.random.uniform([4, 6, 2]))
x1, x2 = tf.split(x, num_or_size_splits=2, axis=1)
x1, x2, x3 = tf.split(x, num_or_size_splits=[1,2,3], axis=1)最大值,最小值,和,均值
最大值:tf.math.reduce_max(?input_tensor, axis=None, keepdims=False, name=None)
最小值:tf.math.reduce_min(?input_tensor, axis=None, keepdims=False, name=None)
和:tf.math.reduce_sum(input_tensor, axis=None, keepdims=False, name=None)
均值:tf.math.reduce_mean(input_tensor, axis=None, keepdims=False, name=None)
#全局数据的最大值,最小值,和,均值
A = tf.constant([[2,14,25,8],[1,4,12,6]] )
tf.reduce_max(A)
Out[9]: <tf.Tensor: id=45, shape=(), dtype=int32, numpy=25>
tf.reduce_min(A)
Out[10]: <tf.Tensor: id=61, shape=(), dtype=int32, numpy=1>
tf.reduce_sum(A)
Out[11]: <tf.Tensor: id=80, shape=(), dtype=int32, numpy=72>
tf.reduce_mean(A)
Out[12]: <tf.Tensor: id=102, shape=(), dtype=int32, numpy=9>
#设置axis值,指定维度的最大值,最小值,和,均值
A = tf.constant([[2,14,25,8],[1,4,12,6]] )
tf.reduce_mean(A, axis=0)
Out[13]: <tf.Tensor: id=127, shape=(4,), dtype=int32, numpy=array([ 1, 9, 18, 7])>
tf.reduce_max(A,axis=0)
Out[14]: <tf.Tensor: id=155, shape=(4,), dtype=int32, numpy=array([ 2, 14, 25, 8])>
tf.reduce_min(A,axis=0)
Out[16]: <tf.Tensor: id=220, shape=(4,), dtype=int32, numpy=array([ 1, 4, 12, 6])>
tf.reduce_min(A,axis=1)
Out[17]: <tf.Tensor: id=257, shape=(2,), dtype=int32, numpy=array([2, 1])>张量比较
tf.math.equal(x, y, name=None)
#张量比较
x = tf.constant([[2, 5],[3,8]])
y = tf.constant([2,5])
tf.equal(x,y)
Out[21]:
<tf.Tensor: id=425, shape=(2, 2), dtype=bool, numpy=
array([[ True, True],
[False, False]])>
x = tf.constant([[2, 5],[3,8]])
y = tf.constant([[2, 5],[3,8]])
tf.equal(y,x)
Out[34]:
<tf.Tensor: id=1116, shape=(2, 2), dtype=bool, numpy=
array([[ True, True],
[ True, True]])数据索引
tf.gather(params, indices, validate_indices=None, axis=None, batch_dims=0, name=None)
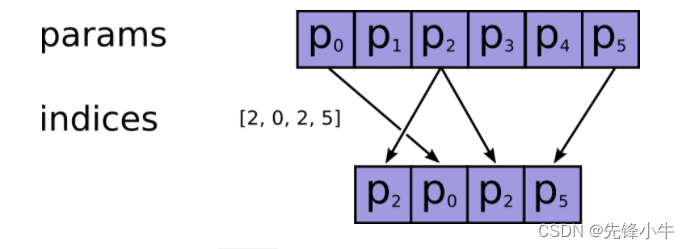
#随机索引
params = tf.constant(['p0', 'p1', 'p2', 'p3', 'p4', 'p5'])
tf.gather(params, 3).numpy()
Out[36]: b'p3'
tf.gather(params, [2,3]).numpy()
Out[37]: array([b'p2', b'p3'], dtype=object)
params = tf.constant([['p0', 'p1', 'p2', 'p3', 'p4'],['p5', 'p6', 'p7', 'p8', 'p9']])
tf.gather(params, [1,1]).numpy()
Out[50]:
array([[b'p5', b'p6', b'p7', b'p8', b'p9'],
[b'p5', b'p6', b'p7', b'p8', b'p9']], dtype=object)
params = tf.constant([['p0', 'p1', 'p2'], ['p3', 'p4','p5'], ['p6', 'p7', 'p8']])
tf.gather(params, [1,2]).numpy()
Out[52]:
array([[b'p3', b'p4', b'p5'],
[b'p6', b'p7', b'p8']], dtype=object)
tf.gather(params, [2,1]).numpy()
Out[53]:
array([[b'p6', b'p7', b'p8'],
[b'p3', b'p4', b'p5']], dtype=object)
tf.gather(params, [2,1], axis=1).numpy()
Out[54]:
array([[b'p2', b'p1'],
[b'p5', b'p4'],
[b'p8', b'p7']], dtype=object)
#通过掩码进行索引
tf.boolean_mask(
tensor, mask, axis=None, name='boolean_mask'
)
A = tf.constant([0, 1, 2, 3, 4])
tf.boolean_mask(A, [1, 1,0,1,0])
Out[60]: <tf.Tensor: id=2719, shape=(3,), dtype=int32, numpy=array([0, 1, 3])>
A = tf.constant([[0, 1, 2],[3, 4,5],[6, 7,8]])
tf.boolean_mask(A, [1, 0,0])
Out[62]: <tf.Tensor: id=2873, shape=(1, 3), dtype=int32, numpy=array([[0, 1, 2]])>
tf.boolean_mask(A, [1, 0,1])
Out[63]:
<tf.Tensor: id=2968, shape=(2, 3), dtype=int32, numpy=
array([[0, 1, 2],
[6, 7, 8]])>
tf.boolean_mask(A,[[0, 1, 1],[1, 0,0],[0, 1,0]])
Out[69]: <tf.Tensor: id=3419, shape=(4,), dtype=int32, numpy=array([1, 2, 3, 7])>数据集加载
boston_housing模块:波士顿房价数据集,回归模型
cifar10/cifar100模块:图片数据集,图片分类
fashion_mnist/mnist模块:手写数字图片集
imdb模块:情感分类任务数据集
reuters模块:新闻数据集
各模块加载函数:
tf.keras.datasets.boston_housing.load_data()
tf.keras.datasets.cifar10.load_data()
tf.keras.datasets.cifar100.load_data(label_mode='fine')
tf.keras.datasets.fashion_mnist.load_data()
tf.keras.datasets.imdb.load_data(
????path='imdb.npz',
????num_words=None,
????skip_top=0,
????maxlen=None,
????seed=113,
????start_char=1,
????oov_char=2,
????index_from=3,
????**kwargs
)
tf.keras.datasets.mnist.load_data(path='mnist.npz'
tf.keras.datasets.reuters.load_data(
????path='reuters.npz',
????num_words=None,
????skip_top=0,
????maxlen=None,
????test_split=0.2,
????seed=113,
????start_char=1,
????oov_char=2,
????index_from=3,
????**kwargs
))
返回值:
(x_train, y_train), (x_test, y_test)
#加载cifar10数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
print('x_train:', x_train.shape, 'y_train:', y_train.shape)
x_train: (50000, 32, 32, 3) y_train: (50000, 1)
#转换为dataset 类型,dataset类型提供了对数据进行预处理的方法
train_tensor = tf.data.Dataset.from_tensor_slices((x_train, y_train))
