文章说明:对movie_metadata数据做简单的分析处理,做了三个简单的案例分析,可在此基础上进行拓展和更好的分析。
movie_metadata数据下载链接
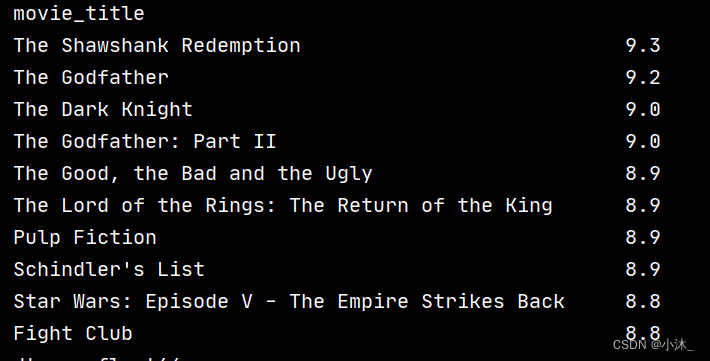
1、电影排行榜
import pandas as pd
# 数据预处理
movies_df = pd.read_csv('movie_metadata.csv')
movies_df = movies_df.drop_duplicates() # 数据清洗去重
movies_df = movies_df.dropna() # 删除缺失值
""" 字段说明
imdb_score 电影在imdb上的评分
movie_title 电影名称
"""
# 获取最大评分的电影
movie_sort_imdb_score = movies_df.sort_values(['imdb_score'], ascending=False).head(10)
movie_max_series = pd.Series(data=movie_sort_imdb_score['imdb_score'].values,
index=movie_sort_imdb_score['movie_title'])
print(movie_max_series)
"""写自己对这个结果的分析
"""
2、词云
from wordcloud import WordCloud
import pandas as pd
""" 对【plot_keywords】词云分析
1、提取字段数据并转为一行
2、生成词云
"""
# 数据预处理
movies_df = pd.read_csv('movie_metadata.csv')
movies_df = movies_df.drop_duplicates() # 数据清洗去重
movies_df = movies_df.dropna() # 删除缺失值
movies_plot_keywords = movies_df['plot_keywords'] # 提取plot_keywords数据
# print(movies_plot_keywords)
plot_keywords = ''
# 遍历数据
for word in movies_plot_keywords:
plot_keywords += '|' + word
# print(plot_keywords)
wc = WordCloud().generate(plot_keywords) # 生成词云
wc.to_file('xiaomu.jpg') # 保存图片
"""写自己对这个结果的分析
"""
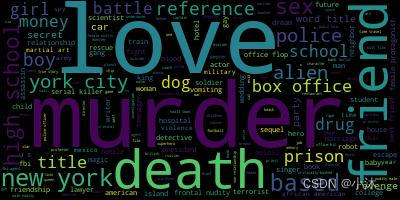
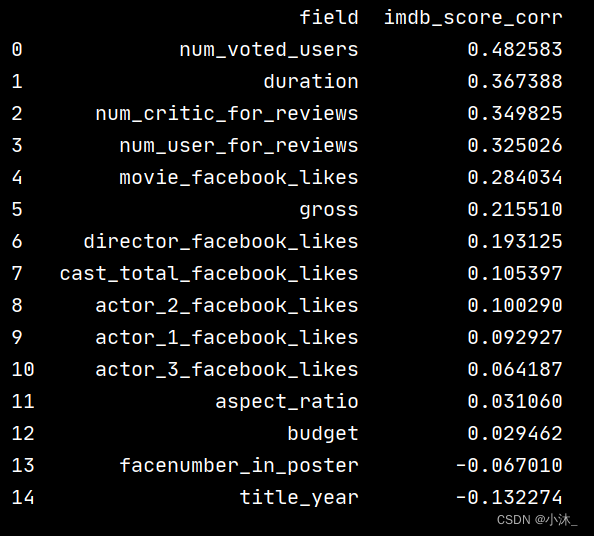
3、相关性分析
import pandas as pd
"""
1、将电影imdb上的评分和各个因素进行相关性分析
2、将相关性的占比做成百分比形式
"""
# 数据预处理(自己考量怎那么处理)
movies_df = pd.read_csv('movie_metadata.csv')
movies_df = movies_df.drop_duplicates() # 数据清洗去重
movies_df = movies_df.dropna() # 删除缺失值
drop_list = ['movie_imdb_link', 'num_voted_users', 'num_critic_for_reviews', 'num_user_for_reviews']
print(movies_df)
# movies_df.drop(labels=[drop_list], axis=1, inplace=True) # 删除列
""" 字段说明
facenumber_in_poster: 海报中的人脸数量
director_name: 导演姓名
movie_title: 电影片名
director_facebook_likes: 脸书喜欢该导演的人数
title_year: 电影年份
duration: 电影时长
actor_1_name: 男一号姓名
country: 国家
actor_1_facebook_likes: 脸书上喜爱男一号的人数
genres: 电影题材
color: 画面颜色。
actor_2_name: 男二号姓名
aspect_ratio: 画布的比例
actor_2_facebook_likes: 脸书上喜爱男二号的人数
content_rating: 电影分级
plot_keywords: 剧情关键字
actor_3_name: 三号男演员姓名
language: 语言
actor_3_facebook_likes: 脸书上喜爱3号男演员的人数
budget: 制作成本
cast_total_facebook_likes: 脸书上投喜爱的总数
gross: 总票房
movie_facebook_likes: 脸书上被点赞的数量
movie_imdb_link: imdb地址
imdb_score: imdb上的评分
num_voted_users: 参与投票的用户数量
num_critic_for_reviews: 评论家评论的数量
num_user_for_reviews: 用户的评论数量
"""
# 将所有的字段和 【gross】 字段做相关性分析
movies_imdb_score = movies_df.corr()['imdb_score']
# 将gross删除并排序(降序)
movies_imdb_score = movies_imdb_score.sort_values(ascending=False).drop("imdb_score")
# 将类型转为DataFrame
movies_imdb_score = movies_imdb_score.to_frame()
# 重置索引(将索引构造出来)
movies_imdb_score = movies_imdb_score.reset_index()
# 改列名为【field】和【imdb上的评分】
movies_imdb_score.rename(columns={'index': 'field', 'imdb_score': 'imdb_score_corr'}, inplace=True)
print(movies_imdb_score)
"""写自己对这个结果的分析
"""