code:https://github.com/rcmalli/keras-vggface
《现实世界的对抗性例子涉及化妆应用》
摘要:
深度神经网络发展迅速,在图像分类、自然语言处理等领域取得了优异的性能。然而,最近的研究表明,数字和物理对抗的例子都可以欺骗神经网络。人脸识别系统被用于涉及来自物理对抗实例的安全威胁的各种应用。在这里,**我们建议使用全身化妆的身体对抗性攻击。**在人的脸上化妆是一种合理的可能性,这可能会增加攻击的隐蔽性。在我们的攻击框架中,我们结合了循环对抗生成网络(cycle-GAN)和一个受害分类器。采用Cycle-GAN生成对抗性化妆,受害分类器的结构为vgg16。实验结果表明,该算法可以有效地克服化妆应用中的人工错误,如颜色和位置相关的错误。我们还证明,用于训练模型的方法可以影响物理攻击;预先训练的模型所产生的对抗性扰动受相应训练数据的影响。
1介绍
深度神经网络以其在机器学习和人工智能应用(如目标检测、自动语音识别和视觉艺术处理)中令人印象深刻的性能而闻名。然而,最近的研究表明,训练良好的深度神经网络容易受到称为对抗性例子的难以区分的扰动,这种扰动可以应用于数字和物理攻击。广泛的努力致力于解决数字对抗攻击。Madry等人[1]提出了一种基于迭代梯度的攻击,可以在允许的范数球内有效地搜索敌对例子(这个是什么???)。Carlini和Wanger[2]将对抗性攻击形式化为一个优化问题,并发现了难以察觉的扰动。此外,大量的数字攻击([3,4,5,6,7,8])可以在整个图像上对人脸识别(FR)系统制造不引人注意的强扰动。然而,在实践中,数字攻击不能直接应用于物理世界。例如,在设置数字攻击时,恶意攻击者不受任何限制地攻击FR的位置,对实际情况进行对抗性扰动。在合理的情况下,试图误导FR系统的恶意攻击者只能给人脸添加扰动,而不是背景。因此,物理攻击比数字攻击具有更多的局限性,也更加复杂。除了扰动的位置,对抗摄动受多种环境因素的影响,如亮度、视角和物理攻击中的摄像机分辨率。也有一些努力来解决物理攻击。某些物理攻击[9,10,11]已经克服了在可穿戴物体(如眼镜、t恤和帽子)上打印敌对噪声的特定限制。此外,一些研究集中在利用对抗性斑块[12]和对抗性轻[13]攻击FR系统。所有这些研究都考虑了环境因素和对抗性扰动的可约性。
在这项研究中,受到[6]的启发,我们设计了一种攻击,使用全脸化妆作为敌对噪音。而不是打印,我们的目标是手动干扰面部,以确保它会成功误导FR系统。与之前的物理攻击相比,我们的攻击最显著的不同,也是最具挑战性的方面是从数字结果中再现噪声的方法。如图1所示,在之前研究中制作的物理对抗性示例下制作的对抗性示例在视觉上具有人眼的独特性,而我们的对抗性示例具有更自然的外观。本文的主要贡献如下:(1)提出了一种新的对抗性合成方法。(2)在现实世界中实施时,我们的攻击可以弥补化妆应用中的人工错误,因此是一个有效的物理对抗例子。
2相关工作
2.1对抗攻击
对抗性攻击可以使用数字和物理方法进行。数字攻击涉及的限制比物理攻击少。在物理场景中,许多因素会影响对抗性扰动的表现,如光线和摄像机镜头的角度。数字攻击和物理攻击都可以定义为有针对性的攻击和无针对性的攻击。目标攻击的定义更为严格,即对抗性例子的预测结果必须是一个特定的类。然而,模型的输出只是在非目标攻击中与地面真值标签不同。我们将在以下部分介绍数字和物理攻击的细节。
2.1.1数字攻击
最近对攻击方法的几项研究表明,深度神经网络(DNNs)很容易被敌对的例子所愚弄。一般来说,数字对抗攻击的损失函数包括对扰动和攻击损失的限制。例如,Szegedy等[14]提出,给定输入x,可以找到一个解r,允许x + r的分类结果接近目标类,且r很小。这可以形式化为一个优化问题:
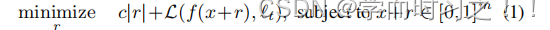
其中L为计算交叉熵等两个概率分布之间距离的函数,f(・)为受害模型,t为目标标签,m为数据维数。超参数c决定扰动r范数的重要性。除了基于优化的攻击,Goodfellow等人[15]、Madry等人[1]和Dong等人[16]提出了基于梯度的攻击dnn的方法。
基于我们攻击的目的,在本节中我们介绍了几种针对FR系统的数字攻击。Zhu等人首先尝试用眼妆干扰目标输入,然后攻击FR系统。Yang等人[8]使用生成神经网络生成攻击FR系统的敌对人脸图像。使用这些方法生成的对抗性例子([3,4,5,7])要么是人为的,要么不能直接应用于物理世界。
2.1.2物理攻击
物理攻击需要考虑更多的因素,它使用了与数字攻击类似的目标函数。然而在方程1中,对r的约束是不充分的,导致物理攻击失败。Sharif等人[9]提出,对于r的扰动应考虑三个方面:(1)如何在现实世界中添加扰动;(2)环境因素:光线、对抗性噪声位置、镜头角度;(3)增加对抗噪声的平滑度。因此,他们提出了一种基于patch的攻击,在特定区域(如眼镜覆盖的区域)内添加扰动来攻击FR系统。对可穿戴物体的类似攻击也被[10,11]合成。Yin等人[17]提出了ad - makeup,它通过黑盒设置转移眼部化妆来执行攻击。
2.2循环生成对抗网络Cycle-GAN
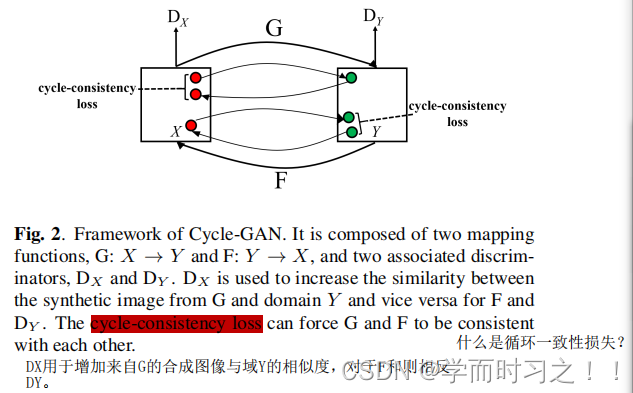
Cycle-GAN[18]是一种涉及图像到图像转换模型的无监督训练的技术。它的应用包括风格转换、物体变形、季节转换以及从绘画中生成照片。如图2所示,Cycle-GAN由映射函数和鉴别器组成,目标是学习给定训练集{xi}Ni=1 X和{yk}Mk=1 Y的两个域X和Y之间的映射函数。它的目标函数包含向前向后的对抗损失和循环一致性损失,这允许图像被翻译成其他风格。考虑到循环gan的应用,它可以可以有效地用于我们的攻击,包括传输化妆和不化妆的面部图像。
3方法
3.1概述
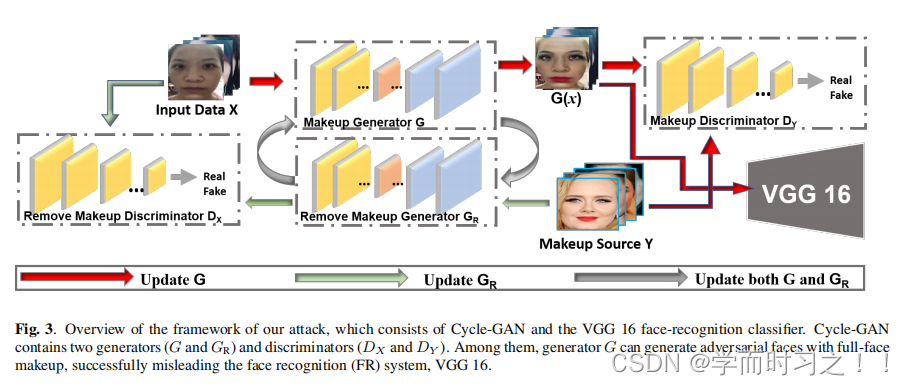
我们使用Cycle-GAN框架来生成难以察觉的对抗性例子。而不是添加无关的噪声图像,全脸化妆被用作对抗干扰误导良好的FR系统。如图3所示,框架由两个组件组成。一个是Cycle-GAN的架构,它负责在化妆和不化妆的人之间转换图像风格。另一个是受害的FR分类器vgg16。化妆生成器以不化妆的个人图像作为输入数据,随机选择涂了化妆品的面孔,可以合成一张全脸妆的脸,成功误导VGG 16。当化妆生成器经过训练后,随机选择输入数据的同一个人的非化妆图像可以欺骗人脸识别系统VGG 16。
3.2化妆产生
我们攻击的目的是产生不引人注目的敌对例子。考虑到在物理世界中的应用,在日常生活中很常见的全脸妆,可以很容易地强制执行。为了实现这一目标,我们选择了Cycle-GAN,它涉及到图像到图像翻译模型的自动训练,没有配对的示例。如图3所示,我们遵循Cycle-GAN[18]的设置,它由两个发生器和两个鉴别器组成。Cycle-GAN包含两个GAN结构。化妆生成器G将非化妆图像转换为全脸化妆图像,而生成器GR可以将包含化妆图像的图像转换为非化妆图像。利用鉴别器DY刺激含有化妆品的合成图像的感知真实性,利用DX提高GR(・)重建生成图像的质量。
non-makeup输入的源图像x x和化妆形象y y,我们首先采用人脸检测使用YoLov4执行裁剪输入x考虑到FR分类器使用在现实生活中,YoLov4应该用不同的角度正确分类的脸排除面临调整的必要性。生成器G以非化妆图像为输入,通过生成式全脸化妆输出G(・);发电机GR取G(・)为不含化妆品的GR(・)输入和输出。为了提高合成图像的质量,我们还应用了鉴别器,使合成图像看起来更自然。鉴别器DY以生成器G生成的带化妆的真实源图像和生成全脸化妆的输出G(・)为输入,鉴别器DX以生成器GR生成的真实无化妆的源图像和输出无化妆的GR(・)为输入。Cycle-GAN包含两个GAN网络;因此,我们定义GAN的损失如下:

3.3化妆攻击
使用化妆品作为一种敌对的干扰,最困难的方面是人们不能准确地使用化妆品。手工化妆在脸上不能完全匹配的数字结果。为了克服这一挑战,我们使用高斯模糊,记为Φ(・),它可以模糊化妆的边界来模拟人工错误。然后,为了产生基于构成的对抗扰动,我们引入以下无目标攻击目标函数

4实验
我们在白盒环境中获得了攻击的结果,并执行了无目标和有目标的攻击。我们收集了一个非化妆图像数据集,其中包括来自我们实验室的8位同事的图像。训练集有2286张图像,测试集有254张样本。我们使用Chen et al.[19]使用的化妆数据集,包含361个训练样本。我们的实验结果表明,每个类的预测概率是用以下公式计算的:


4.1实验设置
我们在白盒设置下进行无目标和有目标的攻击,这意味着攻击者可以访问模型的所有参数。对于攻击目标函数的系数,我们设α = 50, λ = 100, κ = 5。我们根据预先训练的重量和划痕训练分类器。对于pre- training weights1的训练,我们选择Adam作为优化器,用367 epoch对模型进行训练,学习率设置为0.00001。对于从头开始的培训,我们使用了学习率为0.00001和408 epoch的Adam优化器。对于这两种训练方法,我们都将批大小设置为25。在我们的攻击中,我们使用了学习速率为0.0002的Adam优化器,并将批大小设置为1。我们对100多个时代进行了攻击,然后选择看起来最自然的图像作为对抗的例子。所有的实验都是使用Intel Xeon E5-2620v4 CPU, 12gb RAM和NVIDIA TITAN Xp GPU, 12gb RAM的PC进行的。使用的摄像头是华硕ZenFone 5Z ZS620KL(后置摄像头)。
4.2无目标攻击
在无目标攻击下,用预训练权重训练的分类器在测试集上的准确率达到98.41%。在物理世界中,攻击的准确率可以达到84%,如图6 (a)所示。如图5 ?所示,攻击者的准确率下降到0%,攻击者有34%的比例被归类为Class 3。图5 (a)中所示的第3类人(受害类)。图5 (b)和?表明物理对抗示例与数字示例不完全相同。但在消除了噪声干扰的情况下,仍然可以成功地进行攻击。
4.3目标攻击
我们用预先训练的权重训练分类器,并且从头开始训练目标攻击。使用预训练权重训练的模型在测试集上的准确率达到98.41%。此外,从头训练的模型在测试集上的准确率为97.64%。在物理环境中,预训练模型和训练模型的攻击准确率分别达到84%和96%如图6所示。从零开始训练的模型更健壮;因此,即使在观察角度不同的情况下,也能正确地对攻击者进行分类。而在图4中,攻击者可以获得较高比例的某些目标类作为从头开始攻击训练的模型。此外,如果目标图像具有突出的特征,如眼镜,它们可能也会出现在敌对的例子中。


5总结
在本文中,我们针对现实应用提出了一种新颖而强大的攻击机制,该机制可以利用全脸化妆图像对帧检测系统进行攻击。我们的攻击方法不是使用机器添加敌对干扰,而是手动添加它们,并克服了与颜色和位置有关的错误。实验结果表明,该方法在目标攻击和非目标攻击情况下都是有效的。今后,我们将努力减少对抗性噪声的数量,使扰动不易被察觉。我们还打算证明训练模型的方法会影响物理攻击。

