ǰ��
���Ķ����ġ�Proximal Policy Optimization Algorithms�������ܽ�,���д���,��ӭָ����
Ϊʲô��ҪPPO
��������ݶȵ���ѧ����ʽΪ
?
J
(
��
)
=
E
S
[
E
A
��
��
(
.
�O
S
;
��
)
[
Q
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
]
]
(1.0)
\nabla J(\theta)=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]\tag{1.0}
?J(��)=ES?[EA����(.�OS;��)?[Q��?(S,A)?��?ln��(A�OS;��)]](1.0)
���������ἰ,�����е�
A
A
A��ʾ����,
S
S
S��ʾ״̬,
��
\pi
����ʾ���ԡ�ÿʹ��һ��ʽ1.0���²�������,����Ҫ������������������뻷������,�Ӷ����
S
S
S��
A
A
A,���������dz���ʱ��������ѵ��ǰ��ǰ������
S
S
S��
A
A
A,������洢�ھ���ط�������,���ŴӾ���ط������г�ȡ
S
S
S��
A
A
Aѵ����������,�⽫������̶ȼ���ѵ��ʱ�䡣������������,������Proximal Policy Optimization(PPO),�ڽ���PPO֮ǰ,�����Ƚ�����TRPO��
TRPO
TPRO������Ҫ�Բ���,����������ݶȽ��н���,�Ӷ����þ���ط�������ٸ��²������硣������������ѧ����,�ɵ���Ҫ�Բ�������ѧ��ʽ:
E
x
��
p
[
f
(
x
)
]
=
E
x
��
q
[
p
(
x
)
q
(
x
)
f
(
x
)
]
(2.0)
E_{x \sim p}[f(x)]=E_{x \sim q}[\frac{p(x)}{q(x)}f(x)]\tag{2.0}
Ex��p?[f(x)]=Ex��q?[q(x)p(x)?f(x)](2.0)
ֵ��һ�����,ʽ2.0��ʽ����ķֲ���Ȼ������ʽһ��,���Ƿ���ȴ��ͬ:
V a r x �� p [ f ( x ) ] = E x �� p [ f ( x ) 2 ] ? ( E x �� p [ f ( x ) ] ) 2 V a r x �� q [ p ( x ) q ( x ) f ( x ) ] = E x �� p [ f ( x ) 2 p ( x ) q ( x ) ] ? ( E x �� p [ f ( x ) ] ) 2 \begin{aligned} Var_{x\sim p}[f(x)]&=E_{x\sim p}[f(x)^2]-(E_{x\sim p}[f(x)])^2\\ Var_{x\sim q}[\frac{p(x)}{q(x)}f(x)]&=E_{x\sim p}[f(x)^2\frac{p(x)}{q(x)}]-(E_{x\sim p}[f(x)])^2 \end{aligned} Varx��p?[f(x)]Varx��q?[q(x)p(x)?f(x)]?=Ex��p?[f(x)2]?(Ex��p?[f(x)])2=Ex��p?[f(x)2q(x)p(x)?]?(Ex��p?[f(x)])2?
���ֲ� p ( x ) p(x) p(x)�� q ( x ) q(x) q(x)����ʱ,ʽ2.0��ʽ����ֲ��ķ���Ҳ���ơ�
�����ѧϰ���Ż�Ŀ��Ϊ
max
?
J
(
��
)
=
E
A
��
��
(
.
�O
S
;
��
)
[
V
��
(
S
)
]
\max J(\theta)=E_{A\sim \pi(.|S;\theta)}[V_\pi(S)]
maxJ(��)=EA����(.�OS;��)?[V��?(S)]
����ʽ2.0��ʽ1.0������ѧ�仯�ɵ�
?
J
(
��
)
=
E
S
[
E
A
��
��
(
.
�O
S
;
��
)
[
Q
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
]
]
=
E
S
[
E
A
��
��
��
(
.
�O
S
;
��
o
l
d
)
[
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
Q
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
]
]
��
E
S
[
E
A
��
��
��
(
.
�O
S
;
��
o
l
d
)
[
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
]
]
(2.1)
\begin{aligned} \nabla J(\theta)&=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]\\ &=E_S[E_{A\sim \pi'(.|S;\theta_{old})}[\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]\\ &\approx E_S[E_{A\sim \pi'(.|S;\theta_{old})}[\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]\tag{2.1} \end{aligned}
?J(��)?=ES?[EA����(.�OS;��)?[Q��?(S,A)?��?ln��(A�OS;��)]]=ES?[EA������(.�OS;��old?)?[����(A�OS;��old?)��(A�OS;��)?Q��?(S,A)?��?ln��(A�OS;��)]]��ES?[EA������(.�OS;��old?)?[����(A�OS;��old?)��(A�OS;��)?Q����?(S,A)?��?ln��(A�OS;��)]]?(2.1)
������
��
\pi
�������
��
��
\pi'
��������ʱ,��
Q
��
(
S
,
A
)
��
Q
��
��
(
S
,
A
)
Q_\pi(S,A)\approx Q_{\pi'}(S,A)
Q��?(S,A)��Q����?(S,A),�ɴ˿ɵ�ʽ2.1�е����е�Լ���ڷ��š�Ϊ���ò���
��
\pi
�������
��
��
\pi'
��������,���TPRO������
��
\pi
�������
��
��
\pi'
������KLɢ����Ϊ������������ʧ����Ϊ
max
?
L
(
��
)
=
max
?
E
A
��
��
��
(
.
�O
S
;
��
o
l
d
)
,
S
[
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
V
��
(
S
)
]
?
��
K
L
(
��
(
A
�O
S
;
��
)
,
��
��
(
A
�O
S
;
��
o
l
d
)
)
\begin{aligned} \max L(\theta)=\max E_{{A\sim \pi'(.|S;\theta_{old})},S}[\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}V_{\pi}(S)]-\beta KL(\pi(A|S;\theta),\pi'(A|S;\theta_{old})) \end{aligned}
maxL(��)=maxEA������(.�OS;��old?),S?[����(A�OS;��old?)��(A�OS;��)?V��?(S)]?��KL(��(A�OS;��),����(A�OS;��old?))?
��
\beta
��Ϊ��������ѵ��ǰ,���ò���
��
��
(
A
�O
S
;
��
o
l
d
)
\pi'(A|S;\theta_{old})
����(A�OS;��old?)(������ʹ�ù�ȥ����
��
o
l
d
\theta_{old}
��old?�IJ�������)�����������뻷������,��һϵ�ж�����״̬��(
s
t
s_t
st?,
a
t
a_t
at?)���뾭��ط������С�ѵ��ʱ,�Ӿ���ط������ȡһϵ�ж�����״̬,����������ʧ����,�����ݶ����������²�������(KLɢ������μ�����Բο�������)��
PPO
PPO��TRPO���Ż�Ŀ������˸Ķ�,��
r
(
��
)
=
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
r(\theta)=\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}
r(��)=����(A�OS;��old?)��(A�OS;��)?,
A
=
V
��
(
S
)
A=V_\pi(S)
A=V��?(S),���Ż�Ŀ��(ʡ���˲��ַ���)��Ϊ
max
?
L
c
l
i
p
(
��
)
=
max
?
E
A
��
��
��
,
S
[
min
?
(
r
(
��
)
A
,
c
l
i
p
(
r
(
��
)
,
1
?
?
,
1
+
?
)
)
A
)
]
(3.0)
\begin{aligned} \max L^{clip}(\theta)=\max E_{A\sim \pi',S}[\min (r(\theta)A,clip(r(\theta),1-\epsilon,1+\epsilon))A)]\tag{3.0} \end{aligned}
maxLclip(��)=maxEA������,S?[min(r(��)A,clip(r(��),1??,1+?))A)]?(3.0)
c
l
i
p
(
r
(
��
)
,
1
?
?
,
1
+
?
)
)
clip(r(\theta),1-\epsilon,1+\epsilon))
clip(r(��),1??,1+?))��ʾ��
r
(
��
)
<
1
?
?
r(\theta)<1-\epsilon
r(��)<1??ʱ,�ᱻ�ض�Ϊ
1
?
?
1-\epsilon
1??,��
r
(
��
)
>
1
+
?
r(\theta)>1+\epsilon
r(��)>1+?ʱ,�ᱻ�ض�Ϊ
1
+
?
1+\epsilon
1+?��
?
\epsilon
?Ϊ��������ʽ3.0��ȡֵͼ��Ϊ
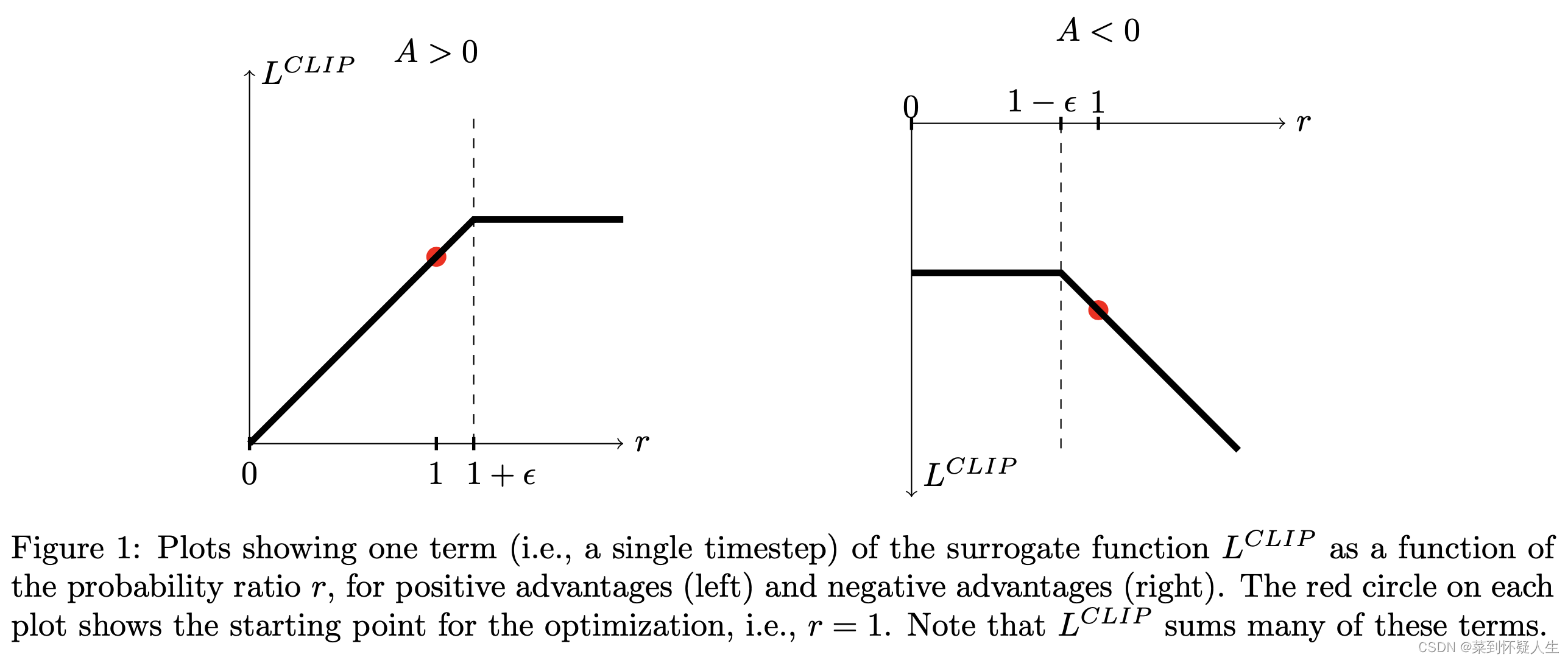
�����˼·Ϊ,��
r
(
��
)
r(\theta)
r(��)�
[
1
?
?
,
1
+
?
]
[1-\epsilon,1+\epsilon]
[1??,1+?]ʱ,����
��
\pi
�������
��
��
\pi'
������Ϊ����,��ʱʽ2.1�е�Լ���ڷ��ų���,��ʱ���ݶ�Լ������������ݶ�(ʽ1.0)����
r
(
��
)
r(\theta)
r(��)���
[
1
?
?
,
1
+
?
]
[1-\epsilon,1+\epsilon]
[1??,1+?]ʱ,��ʱ�ݶ�����������ݶȲ��ϴ�,�ݶ��ṩ���źſ����Ǵ����,��˸��²����ķ���Ӧ��Ҫ��Щ��
������������,����������Figure 1����A>0ʱ,��
r
(
��
)
r(\theta)
r(��)ȡֵ����
1
+
?
1+\epsilon
1+?,�ݶȿ��ܰ����������Ϣ,��ʱ���²������ݶ�����
0
<
(
1
?
?
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
(
��
��
��
��
��
��
��
)
<
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
0<(1-\epsilon)Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)(���ڸ��µ��ݶ�)<\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)
0<(1??)Q����?(S,A)?��?ln��(A�OS;��)(��������������)<����(A�OS;��old?)��(A�OS;��)?Q����?(S,A)?��?ln��(A�OS;��)
��ʹ�ý�С���ݶȸ��²�������
r
(
��
)
r(\theta)
r(��)ȡֵС��
1
?
?
1-\epsilon
1??ʱ,�ݶȿ��ܰ����������Ϣ,��ʱ���²������ݶ�����
(
1
?
?
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
>
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
(
��
��
��
��
��
��
��
)
>
0
(1-\epsilon)Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)>\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)(���ڸ��µ��ݶ�)>0
(1??)Q����?(S,A)?��?ln��(A�OS;��)>����(A�OS;��old?)��(A�OS;��)?Q����?(S,A)?��?ln��(A�OS;��)(��������������)>0
��ʹ�ý�С���ݶȸ��²�������A<0ʱ,��
r
(
��
)
r(\theta)
r(��)ȡֵ����
1
+
?
1+\epsilon
1+?,�ݶȿ��ܰ����������Ϣ,��ʱ���²������ݶ�����
0
>
(
1
+
?
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
>
��
(
A
�O
S
;
��
)
��
��
(
A
�O
S
;
��
o
l
d
)
Q
��
��
(
S
,
A
)
?
��
ln
?
��
(
A
�O
S
;
��
)
(
��
��
��
��
��
��
��
)
0>(1+\epsilon)Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)>\frac{\pi(A|S;\theta)}{\pi'(A|S;\theta_{old})}Q_{\pi'}(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)(���ڸ��µ��ݶ�)
0>(1+?)Q����?(S,A)?��?ln��(A�OS;��)>����(A�OS;��old?)��(A�OS;��)?Q����?(S,A)?��?ln��(A�OS;��)(��������������)
��ʱ���ּ�ʹ�ݶ��а����д�����Ϣ,PPO��ʹ������²�������������Դ�һ�������Ǽ�Ȼ
A
<
0
A<0
A<0,����������������ᳫ,�����Ȼʹ�ýϴ���ݶȸ�������,��ʹ�価���������ö���,��
r
(
��
)
r(\theta)
r(��)ȡֵС��
1
?
?
1-\epsilon
1??ʱͬ����ԭ�ĵĽ�������
With this scheme, we only ignore the change in probability ratio when it
would make the objective improve, and we include it when it makes the objective worse
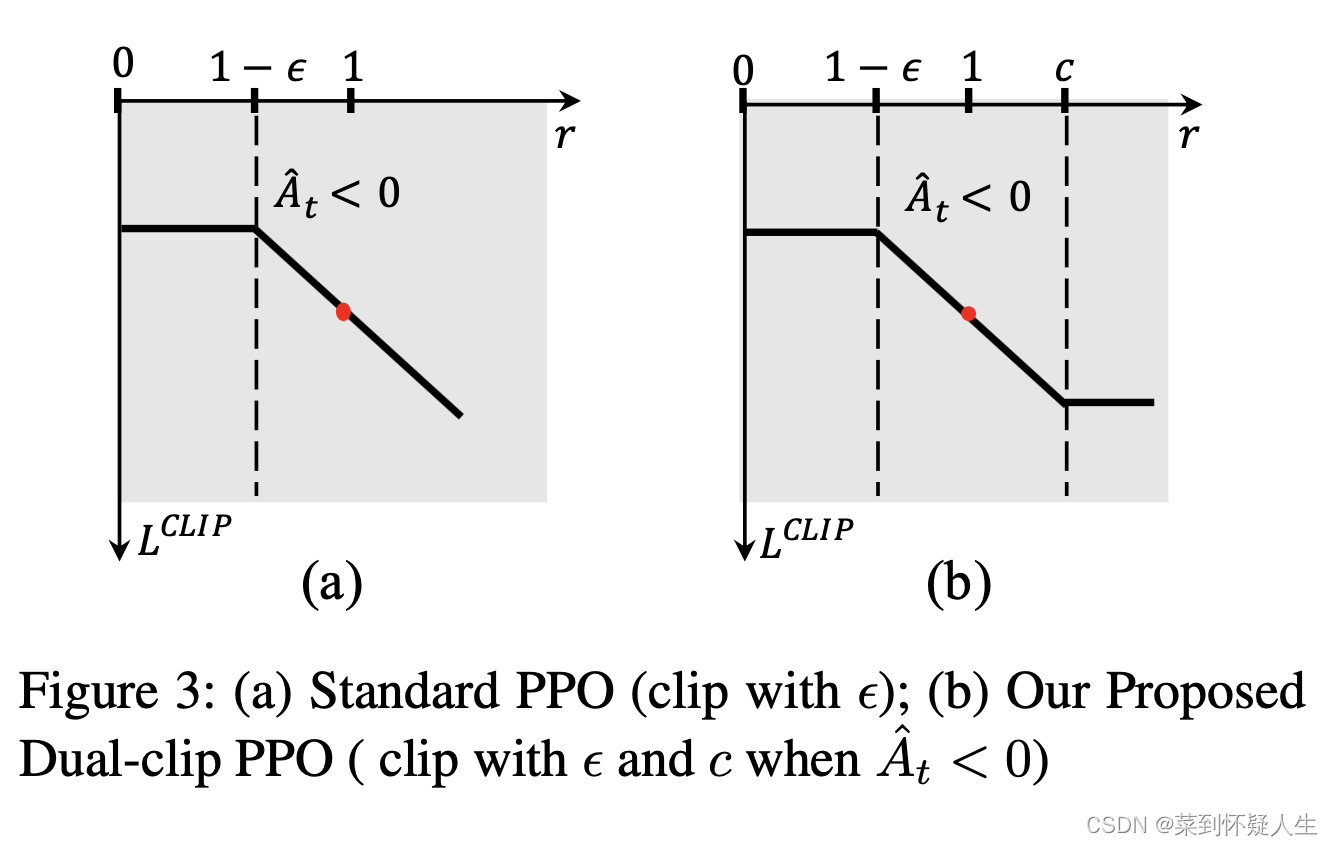
PPO��A<0���ֵ������е�Υ���ҵ�ֱ��,��ʵ��,��Mastering Complex Control in MOBA Games with Deep Reinforcement Learning��һ��ָ��PPO��A<0ʱ�ᵼ�²���������������,�ɴ������Dual PPO,��A<0ʱ,ʽ3.0��ȡֵΪ��ͼ(b),��ȡֵ����
c
c
cʱ,��ʱʹ�ý�С���ݶ������¡�