其一:MLP-Mixer
参考一文教你彻底理解Google MLP-Mixer(附代码) - 月球上的人的文章 - 知乎
https://zhuanlan.zhihu.com/p/372692759
论文链接:https://arxiv.org/abs/2105.01601
先看总体结构: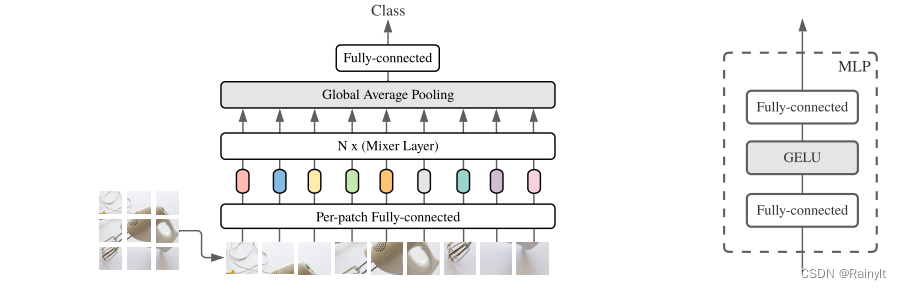
乍一看和Vit特别像,先把图片分Patch,然后拉平过全连接变成Embedding。(或者类似ConvNeXt,直接用kernel_size=patch_size=stride的卷积实现)。
主要就看中间的Mixer Layer怎么实现的。
为什么叫Mixer?因为作者认为,现在的视觉任务无外乎就是混合特征
比如Conv卷积层:
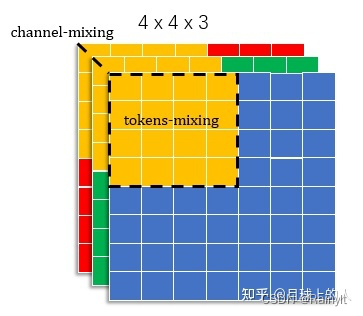
在做卷积的时候实际上就是把一个卷积核所对应的这一块区域做混合(加权相加),卷积核就相当于是混合器。卷积可以分解为Depth-wise卷积和Point-wise卷积,相当于是两个维度的混合,借用这个思想,诞生了转置+MLP的思路:
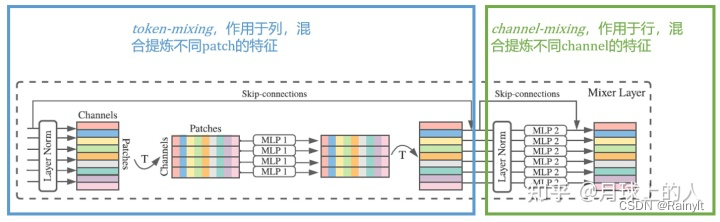
注意,这里使用MLP是共享权重的,因此图中只有MLP1,MLP2,这样的目的是减少参数量,或者可以把MLP看作一个卷积核,每次使用1个卷积核。
MLP1混合的是同一channel里面的所有Patches的信息,MLP2混合的是一个Patch里面的所有Channel的信息。
为什么?回顾一下全连接的作法:
m个数字经过全连接(矩阵乘法)后输出k个数字,每个数字都是这m个数字加权得到的结果,相当于把这m个数字通过不同方法混合。
如果是(n, embeddings)的矩阵呢?
经过全连接后生成(n, k)的矩阵,还是在最后一维做混合。就图中而言,相当于是行内混合
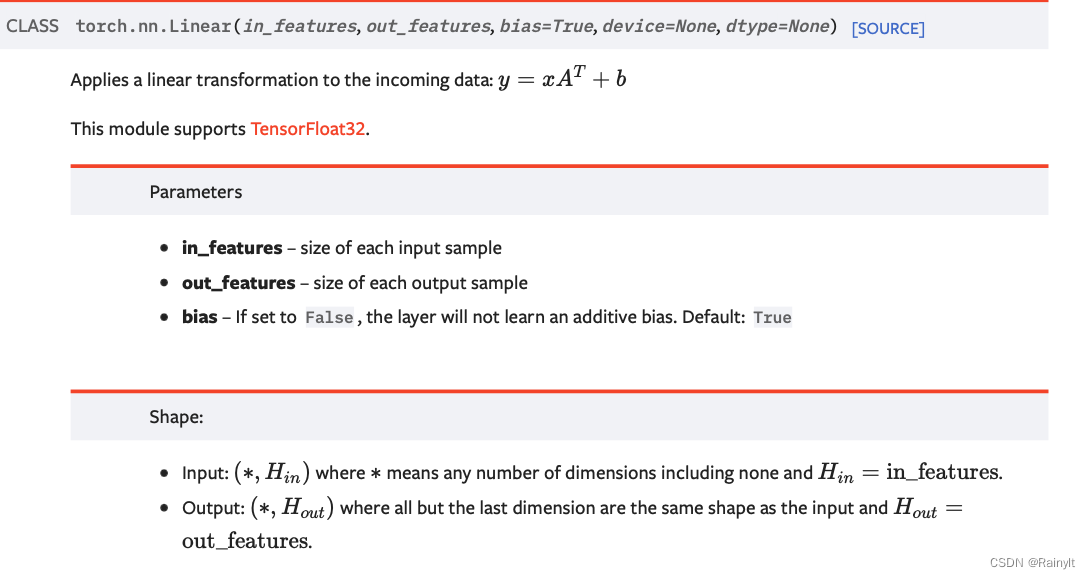
从Pyroch文档我们可以看到,就是做了矩阵乘法。
首先来看,一个(m, )向量通过fc层变成(k, )实际做了什么:
(m,)x(m, k)=>(k, )矩阵乘法
也就是说:一个向量乘一个矩阵就是FC层
对于(n, embeddings),过全连接就是乘一个矩阵
也就是说:使用nn.linear是天然的所有embedding共享同一套weight,想要使用不同的weight得有一个3维的权重矩阵,可能是改F.linear的参数,不过这里不再深究,按Pytorch的nn.linear就是共享一套权重的:

思考
首先是Patch,就是图像的一块,拉平后变成1维,再通过全连接做维度变换,实际上就是过Kernel_size=Patch_size=Stride的卷积,每个Patch内的信息被融合后变成一个向量。
后面的转置前后的MLP虽然可以类比Depth-wise和Point-wise,但并不能完全等效
要把MLP看作卷积,即把它的权重矩阵(input_dim, output_dim)看作卷积核,即output_dim个维度为input_dim个卷积核,即其卷积核始终是1维的。而Point-wise卷积的卷积核是3维,Depth-wise卷积的卷积核是2维,是变化的。
对于转置前,输入(Patches, Channels),乘上(Channels, output_dim)的矩阵输出,
我们可以把二维想象成3维,或者说是一幅图上就只有Patch_num个像素点:
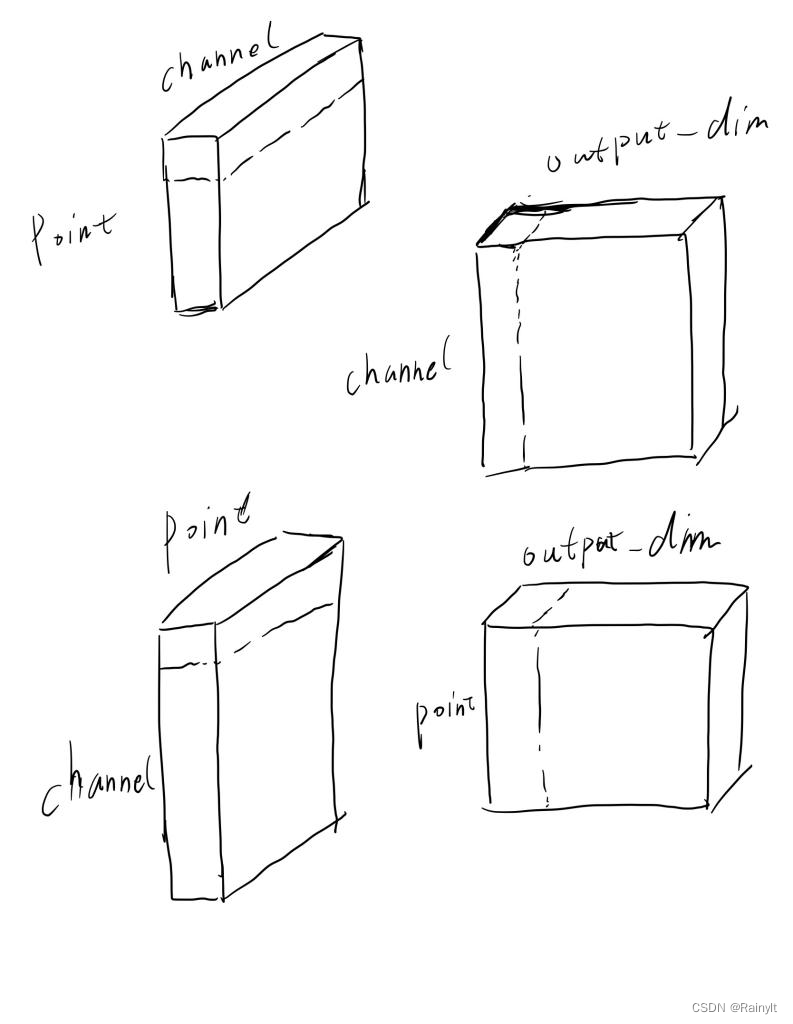
第一个阶段,对每个Point做卷积,滑动卷积核对所有Point做卷积,就跟Point-wise卷积很类似
第二个阶段,对同一Channel的所有Point做卷积,问题是还是滑动窗口,所有Channel使用相同的卷积核。。
CNN中的Depth-wise是不同Channel使用不同的卷积核。
应该说,Depth-wise卷积就不能用矩阵乘法实现,应该用矩阵点乘再以横轴为单位求和得到,另外,
如果直接用和原图大小的矩阵,相当于是和原图大小的卷积核。
由于Depth-wise卷积很难用矩阵乘法实现,这也是为什么在CNN里它速度慢的原因
参数量对比
vit的参数量与精度:

Mixer参数量:207M
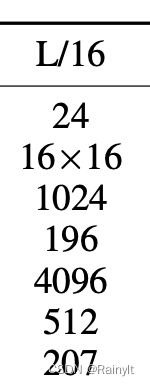
精度:
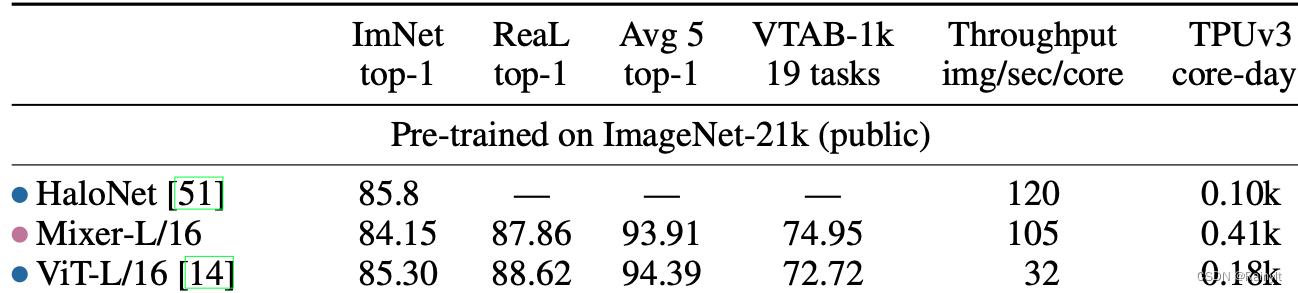
感觉不如Vit。。

