前言
??这篇论文比较老了,是2018年12份上传到arxiv的,虽然也就才几年,但是对于现在深度学习相关领域日卷月卷的情况而言,确实有点太旧了。个人感觉,如果对于二阶段目标检测算法已经有了大概的一个了解,这篇论文可以不去深究了,赶紧看看最新论文或者其他相关领域的论文找想法凑毕业要求吧。
??本篇文章是个人阅读文献的一些总结与思考,如有某些地方理解有问题请指出,个人QQ:1981425845
论文及代码链接
??论文链接:论文链接
(这块儿碎碎念一句,如果觉得arxiv下载论文慢别傻傻等,有方法的,自己网上查查,很简单就是把网址稍微改一下就行)
??代码链接:代码链接
论文动机
??作者发现,在3D点云中,不存在2D图像中的各个不同物体之间的遮挡问题(这个很好理解的,3D空间的物体肯定是相互独立的),这也就是说,一个bounding_box中的点应该只有一个物体的语义信息。基于这种思想,作者提出里一种anchor-free的二阶段3D目标检测网络Point-RCNN,第一阶段直接为每一个点生成一个Bounding_box,而第二阶段通过NMS得到一定数量proposal然后进行proposal的精调。
PointRCNN主要模块分析
??这里先介绍一下Point-RCNN的整体结构以及算法流程,然后再对主要的结构进行详细分析,Point-RCNN的结构框图如下图所示:

??这个图中,上半部分为第一阶段,第一阶段的主要作用就是提取出用于第二阶段的Proposal。具体流程也很简单,就是通过Pointnet++ 得到每个点的特征,然后将每个点的特征输入到前背景分割网络中得到得到每个点是前背景的概率,输入到包络框生成网络中生成每个点对应的Bounding_box参数。
(eg:如果不了解Pointbet++可以移步我之前写的一篇文章:Pointnet以及Pointnet++论文笔记
个人认为对于pointnet、pointnet++以及voxel_net这两个系列的网络还是很有必要好好看一下,这是绝大部分后来的网络的backbone的。)
??下半部分是第二阶段,第二阶段主要是对第一阶段得到的Proposal进行调整得到最终的结果。注意第一阶段每一个点都会生成一个Bounding_box的,那是对所有的Bounding_box都进行refinement么?当然不可能了,这样子得多大计算量,而且很多是冗余计算。作者在进行第二阶段的refinement之前,对Bounding_box进行了非极大值抑制。依据的标准就是与Ground_Truth的IOU,注意需要把角度也就是Bounding_box的朝向考虑进去。得到经过NMS的proposal(proposal就是经过NMS的bounding_box)之后,进一步提取特征并与原来第一阶段得到的特征进行拼接,然后进行proposal的refinement和点的类别置信度预测。下面将详细介绍第一部分以及第二部分的关键结构。
第一阶段:
??第一阶段的bockbone就不讲了,就是通过poinetnet++得到了point-wise的特征。然后分别用分类网络得到点的前背景概率与包络框网络得到包络框参数,其实这两个网络就是两个全卷积网络(FCN)。第一阶段要注意的主要就是第一阶段的损失函数组成,包括Focal_loss以及Bin-based 3D-bounding loss。接下来我们分别来介绍这两个部分。
??Focal_loss : 主要用于解决正负样本数不平衡的问题,由何凯明大神提出。(这里挖个坑,做一篇正负样本不平衡的相关处理技术的总结,之后来填)。Focal_loss用于前背景点的分类中,因为在点云中,绝大部分点是背景点,如果采用普通的Cross_Entropy损失函数会导致于网络倾向于识别成背景点。Focal_loss表达式如下:

??这里做一个直观的解释把,我们以二分类,或者更加直接我们要找出的对象就是汽车(代码中实现的是多分类版本,也就是要找出汽车、行人、自行车,我觉得有必要好好研究一下那一块儿)。对于原始点,是汽车的点标签为1,不是的为0,一个点预测的值大一0.5即认为其为汽车。如果负样本的比率比较大,那么其趋向于把每个点的预测值预测地比较低,也就是接近于0。这样地化,我们看上面的式子。对于负样本,由于预测值偏低,那么pt=1-p就会比较大,进而1-pt就会比较小,而对于正样本,刚好相反,1-pt就会偏大。这样子,正样本LOSS的权重或者说影响力就会比较大,用权重来弥补数量上的不足。同时,文中还对(1-pt)取了一个大于1的指数,这样子的话正负样本的权重差距拉的就更大了。
??Bin-based 3D-bounding loss :为了方便,我们以是对点云中的一点P进行处理为例,要确定点P对应的Bounding_box一共需要(x,y,z,w,h,l,θ)七个参数,其中xyz是Bounding_box中心点坐标,lwh对应长宽高,θ对应于俯视图下的朝向。但是实际上我们也并不会直接去得到回归得到Bounding_box的中心点坐标,这样会丧失刚体变化的不变性,我们一般是求Bounding_box中心点相对于P点的位置偏移,也就是我们其实是要得到(Δx,Δy,Δz,w,h,l,θ),一般的做法也就是直接对这七个值进行回归。但是作者通过实验发现了一种bin-based能得到更好的结果。那么什么是bin_based呢,看论文中的图。

??图中,紫色的点是我们当前处理的点(Point-RCNN中每一个点会对应一个Bounding_box),也就是点P,而橙色三角形P点的预测的bounding_box的中心。那么我们怎么表示这个中心的位置呢?首先,我们以P点位置为中心,分别向x,z方向选定一个的搜索范围(注意在KITTI中,y方向才是竖直方向,不考虑;我记得代码中搜索范围是以该点为中心±1.5m),然后将该搜索方位分成离散的区间。我们首先确定bounding_box的中心点在哪个区间,但是仅仅确定其在哪个区间还不行,比如代码中每个区间是0.5m,如果只确定在那个区间,那个最大误差会接近0.5m,这肯定不满足要求。所以确定区间之后,我们还需要对其在小区间的具体哪个位置进行回归,得到其精确的位置。也就是说bounding_box的中心的位置表示为LocationP + δ*区间分类+区间中具体位置回归。其中δ是每个区间的长度。论文中只对x,z与朝向θ进行了bin处理,其他的还是直接通过回归得到的,也就是说每个点对应的bounding_box的标签组成如下(x的bin分类向量,x在小区间的偏移值,z的bin分类向量,y在小区间的偏移值,y值,长,宽,高,角度的bin分类向量,角度在在小区间的偏移值)。
??这块还有个地方提一下吧,就是x,y方向的分类标签与回归标签是怎么计算的,我当时看了老长时间也没有看明白,也许是我悟性不够。文章中给出的式子如下(具体参数什么意思大家自己看论文呀,论文里头都有解释的,打出来太费劲了):

??看这个式子之前,我们记住一点,标签值是正数,别被前头那张图以及惯性思维迷惑。自认为那张图是以P点为原点,那么P点对应的bin编码应该是(0,0),这样的话上面这个式子为什么要加S就会看不懂了。其实原点对应的bin编码应该是S/δ,比如代码中S=1.5,δ=0.5,那么P点对应的bin编码应该是(3,3),注意这个编码值还应该转成one-hot向量形式。剩下的应该就好理解了,大家自己看论文吧。
??第一阶段整体的损失函数如下:

第二阶段:
??第二阶段主要就是对第一阶段给出的Proposal进行redifiment,既然要更为精确地得到proposal,就需要进一步提取更为精确的特征。作者在这个部分采用了以下几个手段:
- 略微扩大proposal范围
- 进一步提取局部特征
??扩大范围很好理解,提高proposal内的特征总量,注意这个扩大量不是越大越好,文章中给出了实验结果:
??进一步提取局部特征其实就是提取proposal中的局部特征。具体方法就是将proposal中的点转到局部的标准坐标系下面。什么是proposal的局部标准坐标系大家看原文以及下图,很好理解了,就是在proposal中定义了统一标准的原点以及坐标轴,如下:

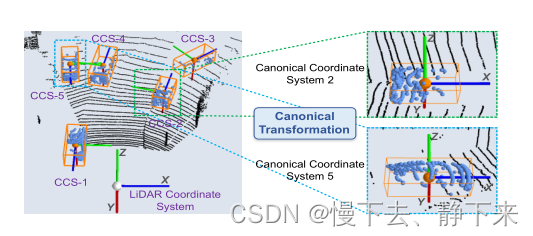
??得到proposal标准坐标系之后,我们进行进一步的局部空间特征提取。这次的特征输入包括每个点在proposal标准坐标系下的位置,点的反射强度,第一阶段的MASK值,也就是是前景点还是背景点以及其距离信息,距离信息用欧式距离来表示,也就是 d = x 2 + y 2 + z 2 d= \sqrt{x^2+y^2+z^2} d=x2+y2+z2?,注意这里头的xyz是在原来坐标系下的xyz,这个特征是很有必要的,因为距离在点云中对特征的影响比较大。得到这些特征之后,通过全连接层进行编码,在与第一阶段的特征进行连接,就得到了第二阶段的完整的特征描述,之后就是利用这些特征进行proposal的refinement。
??第二阶段的LOSS的定义与第一阶段类似,主要就是这次bin的尺度小了一点,因为本来就是微调了。具体大家可以看看论文。
总结及个人思考
??总的来说这个算法偏向于如果去提高精度,但是对于计算速度没有没有进行考虑。比如说Pointnet++作为主干网络本来是就很耗时间的,比如说后面对每个proposal进行扩大,又得遍历一遍整个点云。
??还有一点,其实在作者之后的实现中(OpenPCDet项目)中,作者取消了了bin-based的loss计算方式,还是采用了直接回归的方式。

