1.前言
1.随着图像分类的准确率不断提高,网络的深度越来越深,图像分类的错误率也越来越低,从2012的AlexNet,2013年的ZFNet,2014年的GoogLeNet,再到后面2015年的ResNet,准确率已经超过了人类的水平,所以单纯从准确率方面考虑的话已经很难提升了;开始从其他方面考虑,比如参数量和计算量,软硬件协同。
2.深度可分离卷积和普通卷积
每一个卷积核对应一个输入通道进行卷积,最后将所有经过卷积之后的结果堆叠起来得到最后的feature map,这样只处理长宽方向的信息。最后使用1x1的卷积处理跨通道的空间信息。
(1)普通的卷积操作(standard convolution)
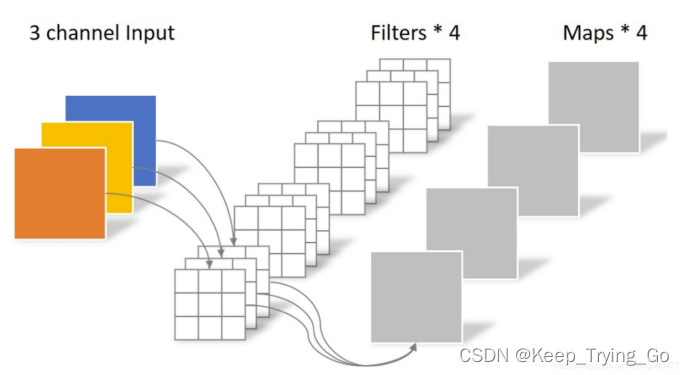
标准卷积的参数量和计算量的计算公式:
输入卷积:Win * Hin * Cin
卷积核:k * k
输出卷积:Wout * Hout * Cout
参数量:(即卷积核的参数)
k * k * Cin * Cout
或者:(k * k * Cin + 1) * Cout (包括偏置bias)
计算量:
k * k * Cin * Wout * Hout * Cout
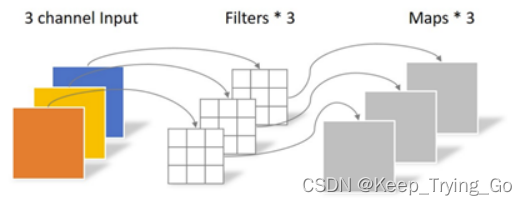
(2)深度可分离卷积(depthwise convolution)
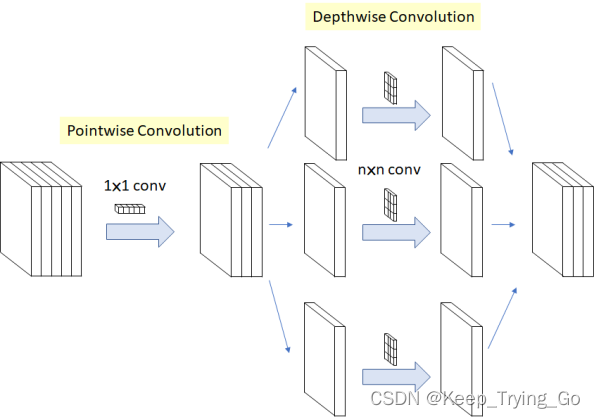
xception中的深度可分离卷积是先使用1x1卷积进行扩通道卷积,再使用深度可分离卷积。
如下图所示:
而原始的深度可分离卷积:
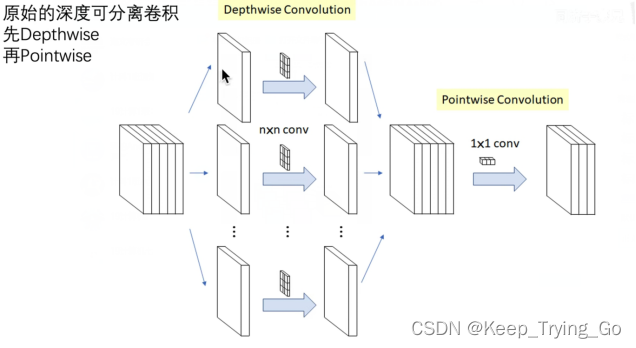
链接:
https://towardsdatascience.com/review-xception-with-depthwise-separable-convolution-better-than-inception-v3-image-dc967dd42568
深度可分离卷积的参数量和计算量的计算公式:
输入卷积:Win * Hin * Cin
卷积核:k * k
输出卷积:Wout * Hout * Cin
参数量:
k * k * Cin
计算量:
k * k * Cin * Wout * Hout
(3)点卷积(pointwise convolution)――1x1卷积
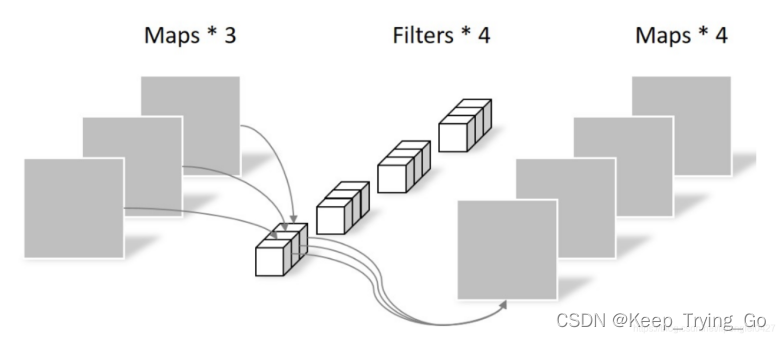
参考博文:
https://blog.csdn.net/kangdi7547/article/details/117925389
注:
深度可分离卷积和普通卷积的区别:
Depthwise :不同的通道使用不同的卷积核进行卷积,也就是使用不同的卷积核来提取特征(一个kernel处理所有的channel)。
Pointwise:标准的1x1卷积操作,kernel=[1,1](一个kernel处理一个channel)。
标准卷积(standard convolutions)和点卷积(pointwise convolution)之间的区别是:
点卷积采用的是1x1的卷积方式。
3.对inceptionV3模块进行改进
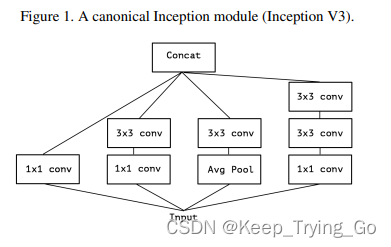
(1)inceptionV3中的原始模块
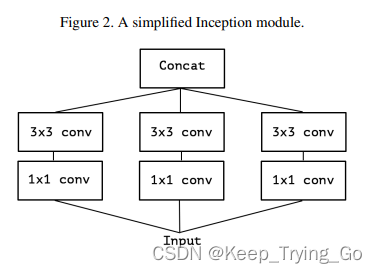
(2)第一层简化
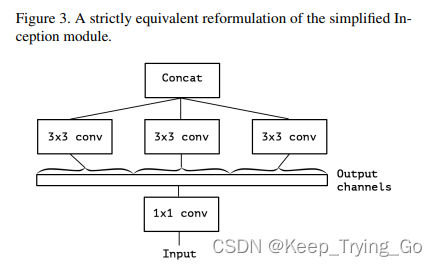
(3)第二层简化
(4)最后的简化
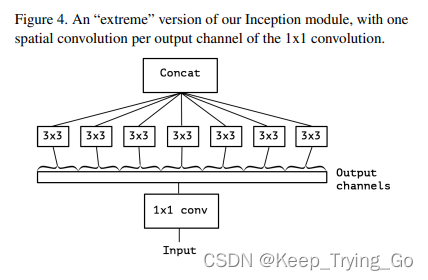
注:每个3x3卷积分别处理不同通道,通道间互不重合。
4.Xception整体网络结构
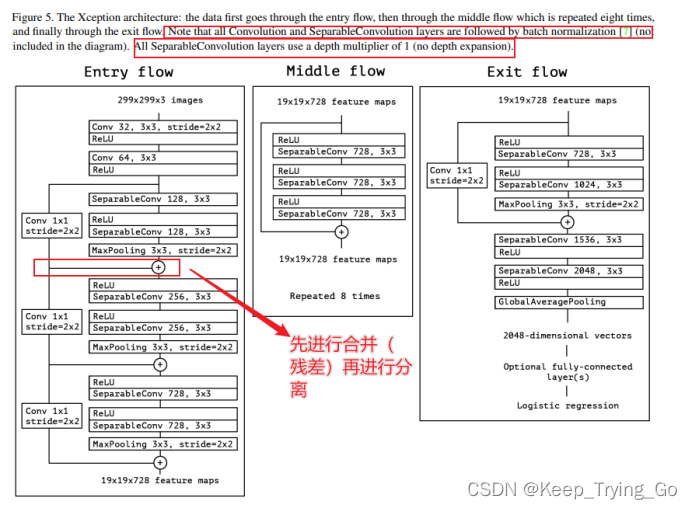
注:Xception包含三个部分:输入部分,中间部分和结尾部分;其中所有卷积层和可分离卷积层后面都使用Batch Normalization处理,所有的可分离卷积层使用一个深度乘数1(深度方向并不进行扩充)。
5.实验结果对比(补充)
(1)深度可分离卷积中激活函数使用问题
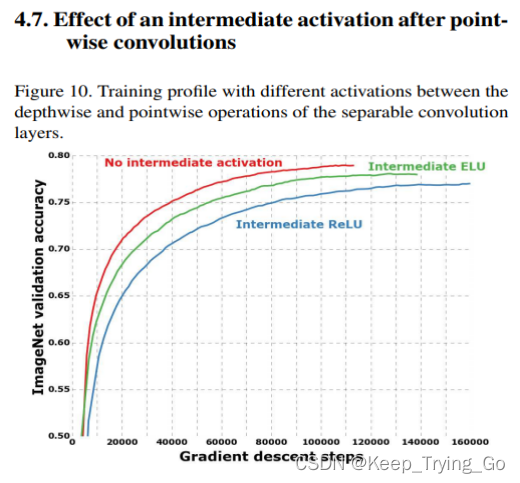
注:作者在论文中提到在使用深度卷积(depthwise convolutions)之前和点卷积(pointwise convolutions)之后不要使用激活函数效果更好。
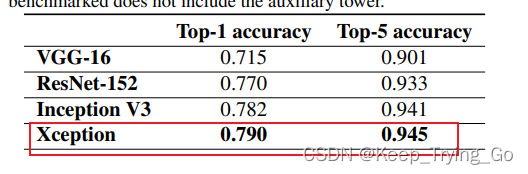
(2)在Imagenet数据集上训练的结果
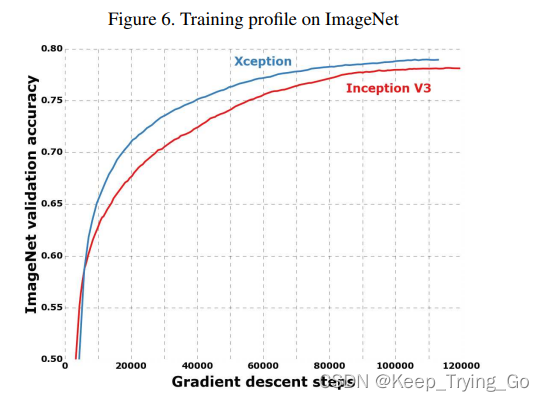
注:从图中可以看到,在Imagenet数据集上,Xception比Inception-V3收敛的更快,效果也更好。
(3)在JTF数据集上训练的结果(不使用全连接层)
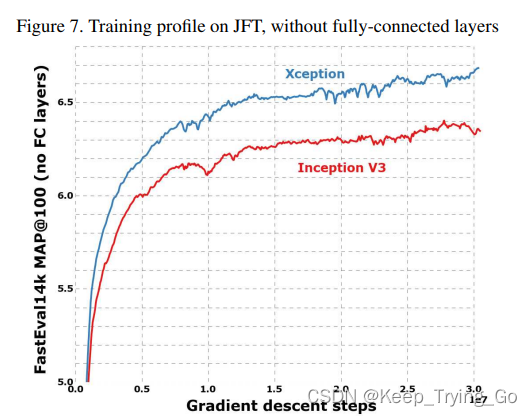
注:从图中可以看到,在JFT数据集上并且都不使用全连接层的情况下,Xception同样比Inception-V3收敛的更快,效果也更好。
(4)在JTF数据集上训练的结果(使用全连接层)
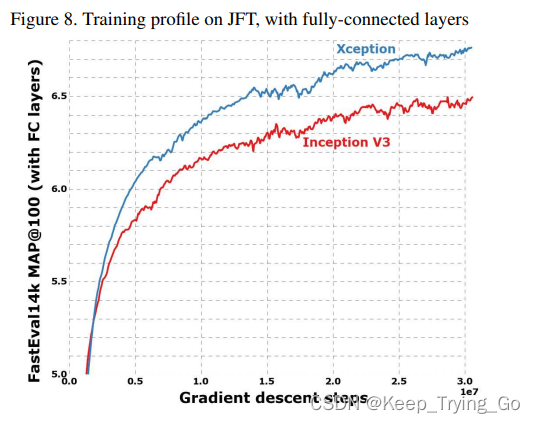
从图中可以看到,在JFT数据集上并且都使用全连接层的情况下,Xception还是同样比Inception-V3收敛的更快,效果也更好。但是相比于不使用全连接层,使用全连接层之后它们都收敛的会慢一点,同时在最后可以看到Xception的MAP上升的空间更大(相对于不使用全连接层)。
当然,上面的这些效果对比都是在Xception和Inception-V3相当的情况下。
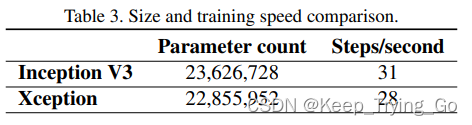
(5)总体效果对比

(6)使用残差和不使用残差的效果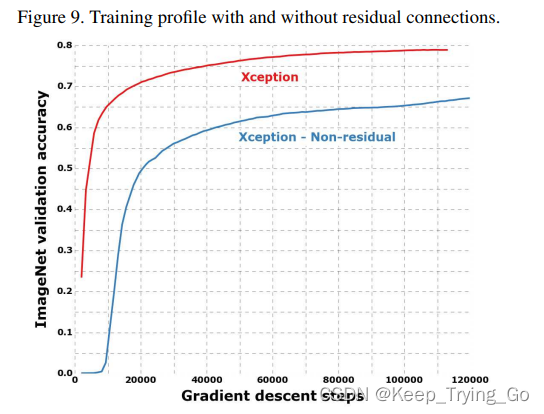
使用残差和不使用残差,使用残差的效果更好,收敛的更快(差距也非常的大)。
6.Tensorflow-2.6.0实现结构
import os
import keras
import numpy as np
import tensorflow as tf
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras.models import Model
class Xception(tf.keras.Model):
def __init__(self):
super(Xception, self).__init__()
#Entry flow
self.conv1=layers.Conv2D(32,kernel_size=[3,3],strides=[2,2],padding='same')
self.conv1batch=layers.BatchNormalization()
self.conv1relu=layers.Activation('relu')
self.conv2=layers.Conv2D(64,kernel_size=[3,3],strides=[1,1],padding='same')
self.conv2batch=layers.BatchNormalization()
self.conv2relu=layers.Activation('relu')
self.DepthSparaconv1=layers.SeparableConv2D(128,kernel_size=[3,3],strides=[1,1],padding='same')
self.DepthSparaconv1relu=layers.Activation('relu')
self.DepthSparaconv2=layers.SeparableConv2D(128,kernel_size=[3,3],strides=[1,1],padding='same')
self.maxpool1=layers.MaxPool2D(pool_size=[3,3],strides=[2,2],padding='same')
self.DepthSparaconv3relu = layers.Activation('relu')
self.DepthSparaconv3 = layers.SeparableConv2D(256, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv4relu = layers.Activation('relu')
self.DepthSparaconv4 = layers.SeparableConv2D(256, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.maxpool2 = layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2], padding='same')
self.DepthSparaconv5relu = layers.Activation('relu')
self.DepthSparaconv5 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv6relu = layers.Activation('relu')
self.DepthSparaconv6 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.maxpool3 = layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2], padding='same')
#Middle Flow
self.DepthSparaconv7relu = layers.Activation('relu')
self.DepthSparaconv7 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv8relu = layers.Activation('relu')
self.DepthSparaconv8 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv9relu = layers.Activation('relu')
self.DepthSparaconv9 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
#Exit Flow
self.DepthSparaconv10relu = layers.Activation('relu')
self.DepthSparaconv10 = layers.SeparableConv2D(728, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv11relu = layers.Activation('relu')
self.DepthSparaconv11 = layers.SeparableConv2D(1024, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.maxpool4 = layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2], padding='same')
self.DepthSparaconv12relu = layers.Activation('relu')
self.DepthSparaconv12 = layers.SeparableConv2D(1536, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.DepthSparaconv13relu = layers.Activation('relu')
self.DepthSparaconv13 = layers.SeparableConv2D(2048, kernel_size=[3, 3], strides=[1, 1], padding='same')
self.avgpool=layers.GlobalAveragePooling2D()
self.dense=layers.Dense(2048)
self.logistic=layers.Activation('softmax')
def call(self,inputs,training=None):
#Entry Flow
print('feature.shape: {}'.format(np.shape(inputs)))
x=self.conv1(inputs)
x=self.conv1batch(x)
x=self.conv1relu(x)
x=self.conv2(x)
x=self.conv2batch(x)
x=self.conv2relu(x)
x3=self.DepthSparaconv1(x)
x3=self.DepthSparaconv1relu(x3)
x3=self.DepthSparaconv2(x3)
x3=self.maxpool1(x3)
x=layers.Conv2D(128,kernel_size=[1,1],strides=[2,2],padding='same')(x)
x4=tf.add(x,x3)
x5 = self.DepthSparaconv3relu(x4)
x5=self.DepthSparaconv3(x5)
x5 = self.DepthSparaconv4relu(x5)
x5=self.DepthSparaconv4(x5)
x5=self.maxpool2(x5)
x6 = layers.Conv2D(256, kernel_size=[1, 1], strides=[2, 2], padding='same')(x4)
x7 = tf.add(x5, x6)
x8 = self.DepthSparaconv5relu(x7)
x8 = self.DepthSparaconv5(x8)
x8 = self.DepthSparaconv6relu(x8)
x8 = self.DepthSparaconv6(x8)
x8 = self.maxpool2(x8)
x9 = layers.Conv2D(728, kernel_size=[1, 1], strides=[2, 2], padding='same')(x7)
x10 = tf.add(x9, x8)
#Middle Flow
print('feature.shape: {}'.format(np.shape(x10)))
x11 = self.DepthSparaconv7relu(x10)
x11 = self.DepthSparaconv7(x11)
x11 = self.DepthSparaconv8relu(x11)
x11 = self.DepthSparaconv8(x11)
x11 = self.DepthSparaconv9relu(x11)
x11 = self.DepthSparaconv9(x11)
x12 = layers.Conv2D(728, kernel_size=[1, 1], strides=[1,1], padding='same')(x10)
x13 = tf.add(x12, x11)
#Exit Flow
print('feature.shape: {}'.format(np.shape(x13)))
x14 = self.DepthSparaconv10relu(x13)
x14 = self.DepthSparaconv10(x14)
x14 = self.DepthSparaconv11relu(x14)
x14 = self.DepthSparaconv11(x14)
x14 = self.maxpool2(x14)
x15 = layers.Conv2D(1024, kernel_size=[1, 1], strides=[2, 2], padding='same')(x13)
x16 = tf.add(x15, x14)
x_out=self.DepthSparaconv12(x16)
x_out=self.DepthSparaconv12relu(x_out)
x_out = self.DepthSparaconv13(x_out)
x_out = self.DepthSparaconv13relu(x_out)
x_out=self.avgpool(x_out)
x_out=self.dense(x_out)
x_out=self.logistic(x_out)
return x_out
model_xception=Xception()
model_xception.build(input_shape=(None,299,299,3))
model_xception.summary()
if __name__ == '__main__':
print('pycharm')



