论文标题:HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection
源码地址:https://cvlab.yonsei.ac.kr/projects/HVPR
延世大学出品
文章认为voxel的方法和point的方法各有优劣,这是一个老生常谈的问题 文章让读者耳目一新的地方是两者的一种新结合方式及一种省时省力的方式来调用point feature。
老规矩 上图:
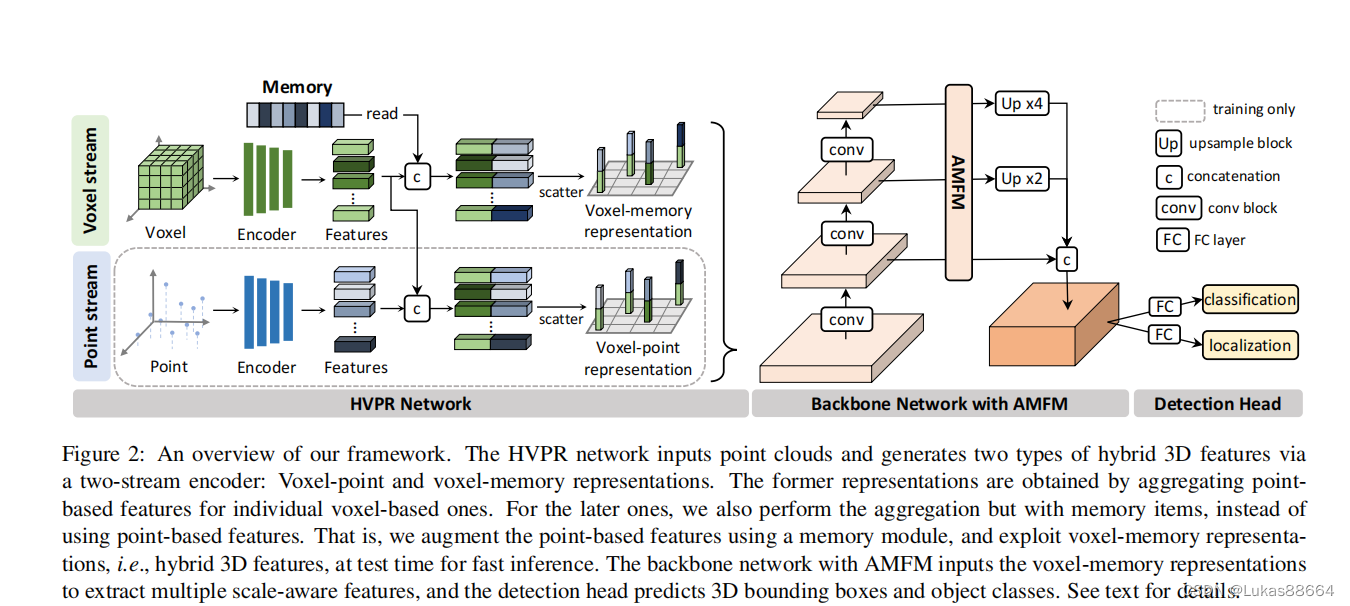
首先讲讲怎么提取voxel和point的特征:
对于voxel:
我们首先划分voxel的范围 这里作者划分voxel的范围是直接采用pillar的形式 对于其中的点采用的是一个tiny pointnet的形式 并跟着一个max pool的操作 (这里为啥不用VFE呢 我也不太清楚 可能是为了承袭pointpillar中的操作?)
对于point:
直接使用的是pointnet++的SA和FP层 得到local feature的交互。
随后便是文章的重点:
如何进行上述两种feature的交互呢?作者首先计算voxel和points的交互矩阵:
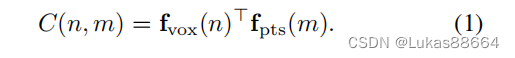
其中C为一个NM的矩阵,N是voxel的个数 M便是points的个数 我们对于这个交互矩阵取每个voxel的权重值:
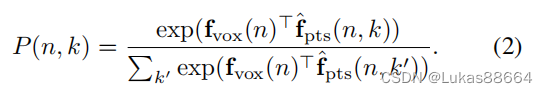
取出每个voxel对应points的value在前k个的值,对这k个值对应的point进行加权:
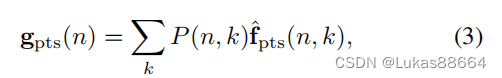
最后再与这个voxel进行concat拼接。
不懂就问,这不就是一个cross attention的操作吗 只不过作者没有对所有的point进行相加 而是取了前k个point的值。那么是不是可以直接用transformer的形式来代替这个feature融合的操作呢?
我想答案是可以的
为了提升voxel与point的交互效率 作者还提出了一个voxel-memory的表现方式 具体方法就是用memory item来代替point,其维度与point一致(C1),我们用voxel作为query来读取memory,然后计算每个voxel与memory的交互矩阵 选取k个最大的进行加权,我们通过下面的loss函数(L2损失)来让point feature与memory item逼近:
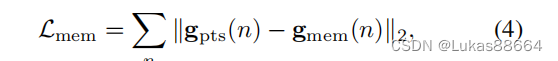
经过上面的步骤我们便得到了voxel图,与image极其类似。
作者还认为3d点云是稀疏的 但是近处与远处的物体并不会改变尺寸 不存在近大远小的关系 只是远处的物体点云更加稀疏。点云的稀疏和不规则模式及其与传感器的距离反映了三维物体的尺度信息。这对于3d目标检测来说 是有意义的。
所以作者对于每个voxel内的point进行了统计 将每个voxel用点云数目和点云的平均三维坐标来进行表示。把他们作为3D scale feature 来生成一个attention map对我们前面的特征图进行加权。
这个3D scale feature map是首先利用pointnet进行编码 随后进行卷积缩放到与对应的feature map同样大小的。
然后将它输入到AMFM模块(Attentive Multi-scale Feature Module)
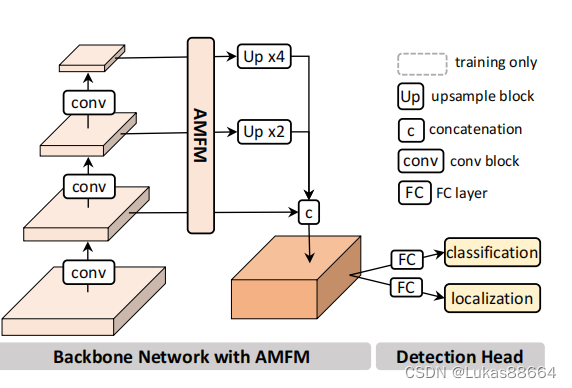
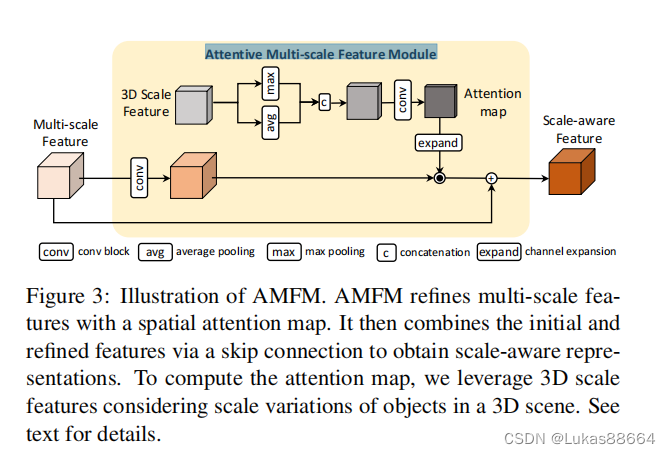
首先对于前面的feature map 我们进行FPN操作 对于不同scale的feature map 利用 3D scale feature进行加权:
3dscale feature先在每一个voxel维度进行max avg操作 得到的结果进行concat,后输入到卷积层进行卷积操作 然后扩展到同feature map维度 进行相乘。feature map则是进行了一个resnet的结构。
由此得到的feature 便有了点云近处点云密集 远处点云稀疏的意识。
检测头没啥好说的 用的是SSD。
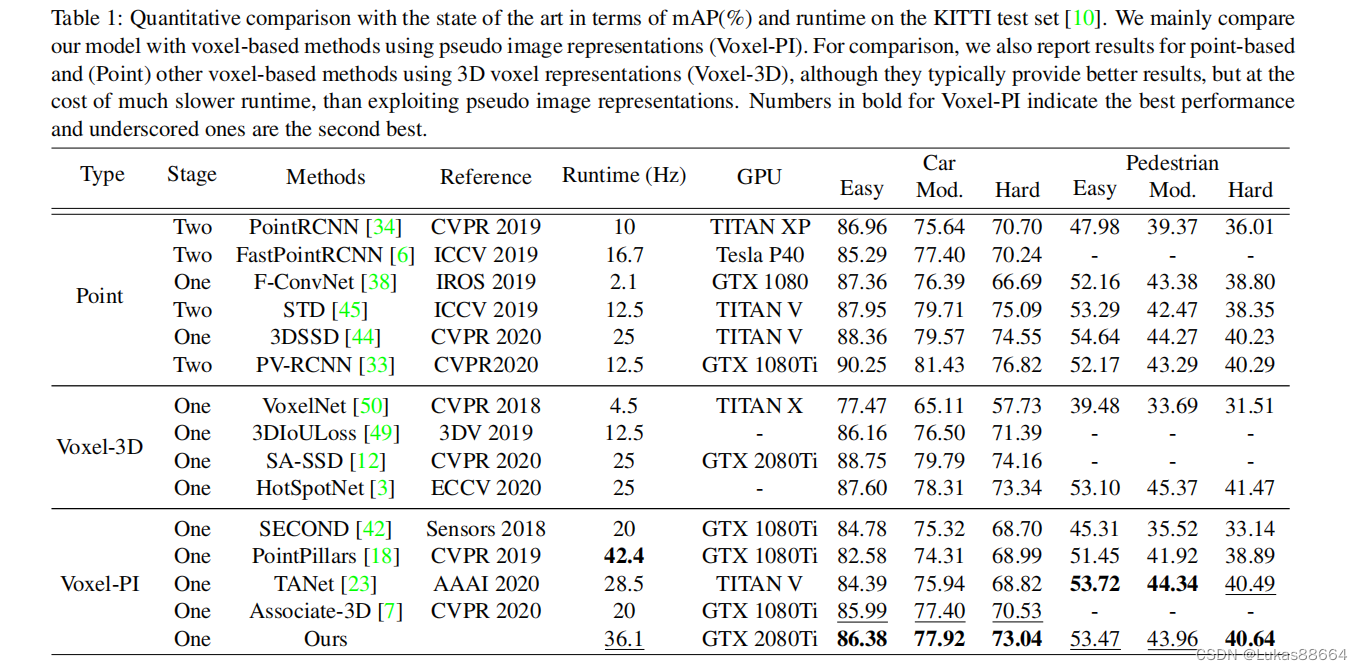
结果不太好看呀 不过是胜在与pointpillar进行比较的 我认为也是合理的 毕竟速度摆在这里。
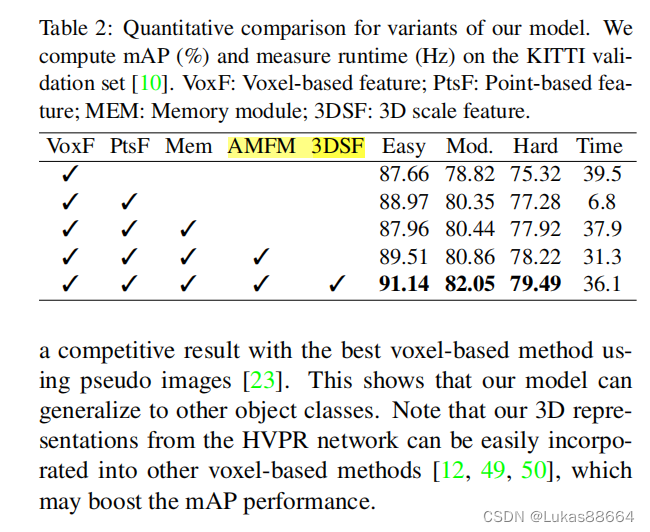
ablation证明AMFM是很有效果的

