介绍
这个例子展示了如何从头开始进行时间序列分类,从磁盘上的原始 CSV 时间序列文件开始。我们在UCR/UEA 档案中的 FordA 数据集上演示了工作流程 。
加载数据:FordA 数据集
数据集描述
我们在这里使用的数据集称为 FordA。数据来自 UCR 档案。该数据集包含 3601 个训练实例和另外 1320 个测试实例。每个时间序列对应于电机传感器捕获的发动机噪声测量值。对于此任务,目标是自动检测引擎是否存在特定问题。问题是一个平衡的二元分类任务。
读取 TSV 数据
我们将使用该FordA_TRAIN文件进行训练并使用该 FordA_TEST文件进行测试。该数据集的简单性使我们能够有效地演示如何使用 ConvNets 进行时间序列分类。在此文件中,第一列对应于标签。
def readucr(filename):
data = np.loadtxt(filename, delimiter="\t")
y = data[:, 0]
x = data[:, 1:]
return x, y.astype(int)
root_url = "https://raw.githubusercontent.com/hfawaz/cd-diagram/master/FordA/"
x_train, y_train = readucr(root_url + "FordA_TRAIN.tsv")
x_test, y_test = readucr(root_url + "FordA_TEST.tsv")
可视化数据
在这里,我们为数据集中的每个类可视化一个时间序列示例。
classes = np.unique(np.concatenate((y_train, y_test), axis=0))
plt.figure()
for c in classes:
c_x_train = x_train[y_train == c]
plt.plot(c_x_train[0], label="class " + str(c))
plt.legend(loc="best")
plt.show()
plt.close()
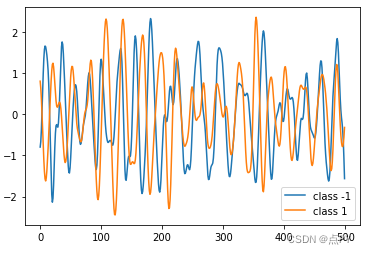
标准化数据
我们的时间序列已经是单一长度(500)。然而,它们的值通常在不同的范围内。这对于神经网络来说并不理想;一般来说,我们应该设法使输入值标准化。对于这个特定的数据集,数据已经被 z 归一化:每个时间序列样本的均值等于 0,标准差等于 1。这种类型的归一化对于时间序列分类问题非常常见,参见 Bagnall 等人。(2016 年)。
请注意,此处使用的时间序列数据是单变量的,这意味着我们每个时间序列示例只有一个通道。因此,我们将使用通过 numpy 的简单整形将时间序列转换为具有一个通道的多变量序列。这将使我们能够构建一个易于应用于多变量时间序列的模型。
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], 1))
x_test = x_test.reshape((x_test.shape[0], x_test.shape[1], 1))
最后,为了使用sparse_categorical_crossentropy,我们必须事先计算类的数量。
num_classes = len(np.unique(y_train))
现在我们对训练集进行洗牌,因为稍后我们将validation_split在训练时使用该选项。并进行归一化。
from sklearn.preprocessing import StandardScaler, RobustScaler
# StandardScaler类是一个用来讲数据进行归一化和标准化的类
# fit_transform方法是fit和transform的结合,fit_transform(X_train) 意思是找出X_train的平均值和标准差,并应用在X_train上。
# 这时对于X_test,我们就可以直接使用transform方法。因为此时StandardScaler已经保存了X_train的平均值和标准差。
idx = np.random.permutation(len(x_train))
x_train = x_train[idx]
y_train = y_train[idx]
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
y_train = sc.transform(y_train)
将标签标准化为正整数。预期的标签将是 0 和 1。
y_train[y_train == -1] = 0
y_test[y_test == -1] = 0
建立模型
我们构建了 本文最初提出的全卷积神经网络。该实现基于 此处提供的 TF 2 版本。以下超参数(kernel_size、过滤器、BatchNorm 的使用)是使用KerasTuner通过随机搜索找到的。
def make_model(input_shape):
input_layer = keras.layers.Input(input_shape)
conv1 = keras.layers.Conv1D(filters=64, kernel_size=3, padding="same")(input_layer)
conv1 = keras.layers.BatchNormalization()(conv1)
conv1 = keras.layers.ReLU()(conv1)
conv2 = keras.layers.Conv1D(filters=64, kernel_size=3, padding="same")(conv1)
conv2 = keras.layers.BatchNormalization()(conv2)
conv2 = keras.layers.ReLU()(conv2)
conv3 = keras.layers.Conv1D(filters=64, kernel_size=3, padding="same")(conv2)
conv3 = keras.layers.BatchNormalization()(conv3)
conv3 = keras.layers.ReLU()(conv3)
gap = keras.layers.GlobalAveragePooling1D()(conv3)
output_layer = keras.layers.Dense(num_classes, activation="softmax")(gap)
return keras.models.Model(inputs=input_layer, outputs=output_layer)
model = make_model(input_shape=x_train.shape[1:])
keras.utils.plot_model(model, show_shapes=True)
训练模型
epochs = 500
batch_size = 32
callbacks = [
keras.callbacks.ModelCheckpoint(
"best_model.h5", save_best_only=True, monitor="val_loss"
),
keras.callbacks.ReduceLROnPlateau(
monitor="val_loss", factor=0.5, patience=20, min_lr=0.0001
),
keras.callbacks.EarlyStopping(monitor="val_loss", patience=50, verbose=1),
]
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
history = model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
callbacks=callbacks,
validation_split=0.2,
verbose=1,
)
根据测试数据评估模型
model = keras.models.load_model("best_model.h5")
test_loss, test_acc = model.evaluate(x_test, y_test)
print("Test accuracy", test_acc)
print("Test loss", test_loss)
绘制模型的训练和验证损失
metric = "sparse_categorical_accuracy"
plt.figure()
plt.plot(history.history[metric])
plt.plot(history.history["val_" + metric])
plt.title("model " + metric)
plt.ylabel(metric, fontsize="large")
plt.xlabel("epoch", fontsize="large")
plt.legend(["train", "val"], loc="best")
plt.show()
plt.close()
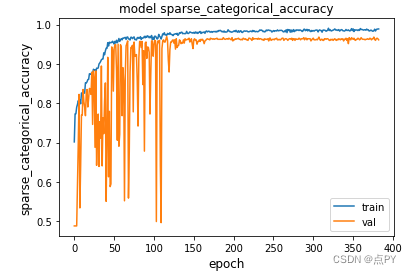
我们可以看到训练准确率在 100 个 epoch 后如何达到几乎 0.95。但是,通过观察验证准确度,我们可以看到网络在 200 个 epoch 后验证和训练准确度达到几乎 0.97 之前仍然需要训练。在第 200 个 epoch 之后,如果我们继续训练,验证准确度将开始下降,而训练准确度将继续增加:模型开始过度拟合。

