-
MCNN―多列卷积神经网络结构来将图像映射到其人群密度图。
-
基于CNN的工作流程:输入图片,通过卷积神经网络提取人的头部特征,生成人群密度图,并通过密度图积分得出图片中的人群总数,这样做的一个好处是得到的密度图保存有的人群密度空间分布,使得我们从中提取的信息更加丰富,从而更好的通过这些信息去做决策。
人群计数算法分类:
(1) 基于目标检测的方法: 对图像上每个行人或这人头进行定位与识别,根据结果统计人数。
① 优点在于可以做到准确的行人或者人头位置
② 缺点在于对高密度的人群图像来说,其检测效果差;
(2)基于回归的方法:人群数目估计,没有精确定位行人位置,而是对大概的人群数目给出个估计值。
①优点在于对高密度人群图像来说,其效果是比基于目标检测方法的好。
②缺点没有精确的定位。
(2.1)直接回归:在深度学习的卷积神经网络中输入人群图像,直接输出一个人群数目估计值;
( 2.2)密度图回归:密度图回归的意思是(已知的数据集是这样的,每一张人群图像中的每个人头所在近似中心位置的坐标作为人工标注),根据已知的每个人头位置,再估计该位置所在人头的大小,这样可以得到该人头的覆盖区域,通过一种方法(MCNN中采用几何自适应高斯核),将该区域转化为该区域内可能为人头的概率,该区域概率和为1(或者表示每个像素可能有多少个人)。最终我们可以得到一张人群密度图。
- 密度图的表示:人群计数里面的标签就是密度图,标注过程主要分为两部分,1.人群图像标注表示;2.人群图像标注转换为人群密度图。
mcnn
1. MCNN具体的标签密度图生成方法
1)xi位置表示有一个人头中心坐标位置,将其表示为δ(x-xi),带N个头部的就可以用图所示,===》想表达的意思是这个坐标位置有个人。
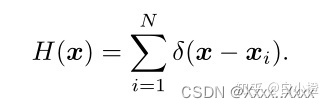
我们需要的是每个不同的xi所对应的像素对应场景中不同大小的区域。因此,需要根据图像中每个人头的大小来确定扩散参数,根据观察得知,在拥挤的场景中,头部大小通常与相邻人的中心距离有关,所以,很多文章都是根据每个人到其相邻的平均距离自适应确定每个人的传播参数。其公式如所示。
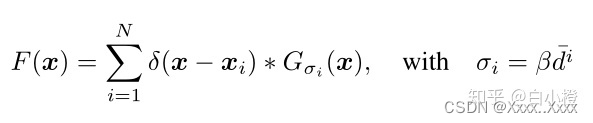
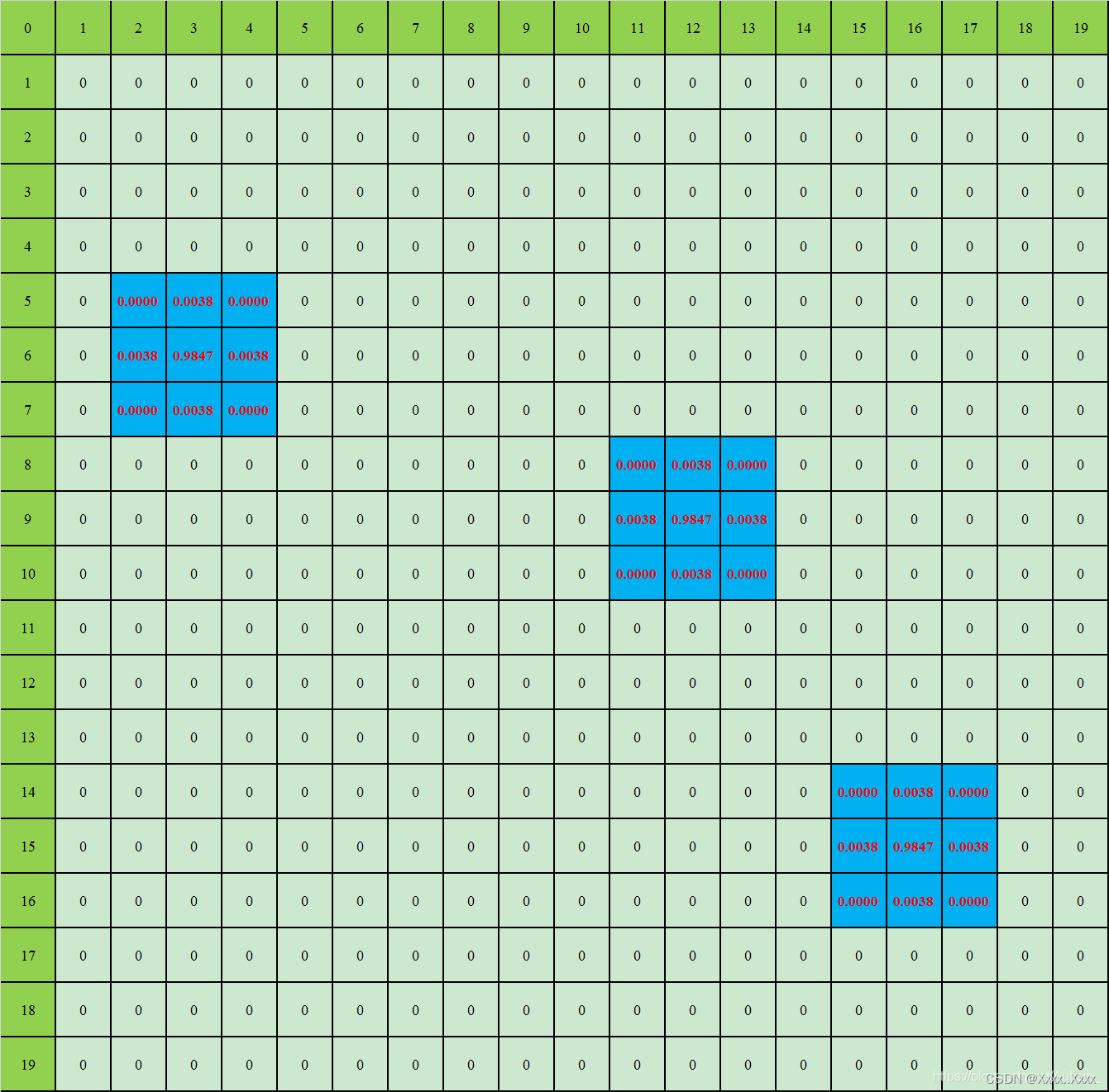
人群标注效果如图4所示,这里有三个人,其位置分别为(3,6),(12,9),(16,15).
效果如下:
2)人群图像标注转换为人群密度图。转化为连续密度函数,
G表示的就是高斯核
σ为高斯核标准差
人头xi的扩散范围与其K近邻个人头的平均距离成正相关。
di那一部分表示在离人头xi最近K个人头的平均距离
β是一个权重,在MCNN中取0.3。
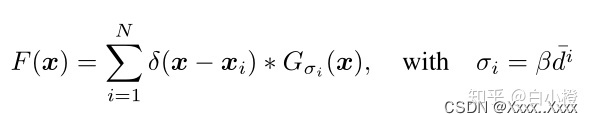
通过一个高斯核函数来完成,将人头扩散为一个范围,其效果图如图所示:
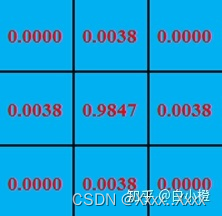
3)公式运算出来的人头大小为3*3,图其内部密度表示。具体的数值计算过程可以去了解高斯函数的原理。数值较高的点表示的人头概率更高,其人头范围总和为1,如图所示:
2. MCNN网络结构
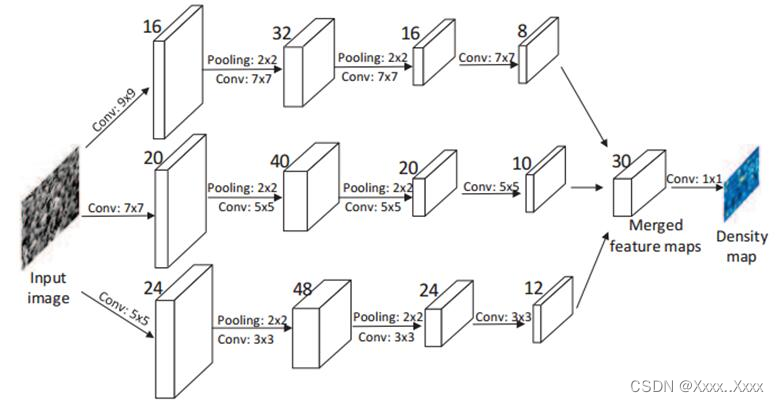
MCNN的多列主要体使用了三列卷积神经网络,表示为
L列(使用大尺度卷积核: 9*9, 7*7, 7*7,7*7),
M(使用中等尺度卷积核: 7*7, 5*5, 5*5, 5*5),
S列(使用小尺度卷积核: 5*5, 3*3, 3*3, 3*3)),
其目的在于使用多种尺度的卷积核来适应不同尺度的人头大小。
最后将L,M,S三列卷积神经网络进行合并,得到网络生成的密度图。
网络结构如下图所示,使用的是全卷积的网络,并且进行了融合。
1)优势
①包含三列卷积神经网络,滤波器大小不同,三列对应具有不同的感受野,因此每个列cnn所学习的特征都能适应由于角度不同而导致的人头大小不均匀而引起的变化
② 在MCNN中,用1*1卷积代替全连接层,因此,模型的输入可以是任意大小的,很大程度上避免了失真的情况。网络的输出为密度图就可以计算得出总人数===》对原始数据集的每张训练集图像随机裁剪9次,得到9张图像子块,每个图像子块为原图的1/4。
(这样的图像子块训练有其优点a. 图像尺寸变小,加快网络训练速度; b. 通过局部图像块的训练完成对完整图像的训练,同样能达到很好的效果)
2)损失函数:
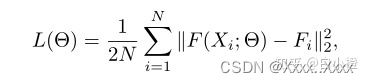
使用欧式距离计算label与ground truth的损失,其中F(xi)为网络生成的密度图,Fi为原密度图。
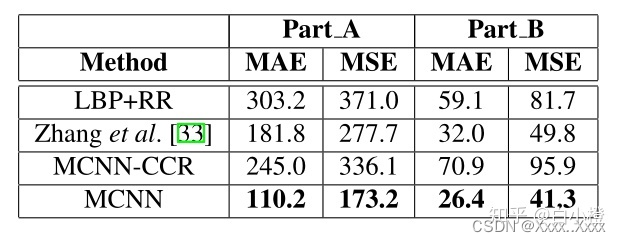
3)评价指标:(平均绝对误差MAE与均方误差MSE)
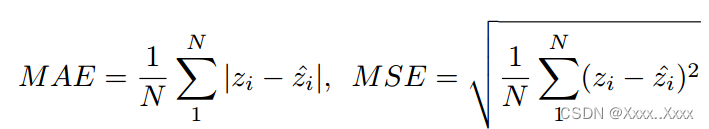
4)结果: