注:下有视频讲解,可供参考
Transformer介绍
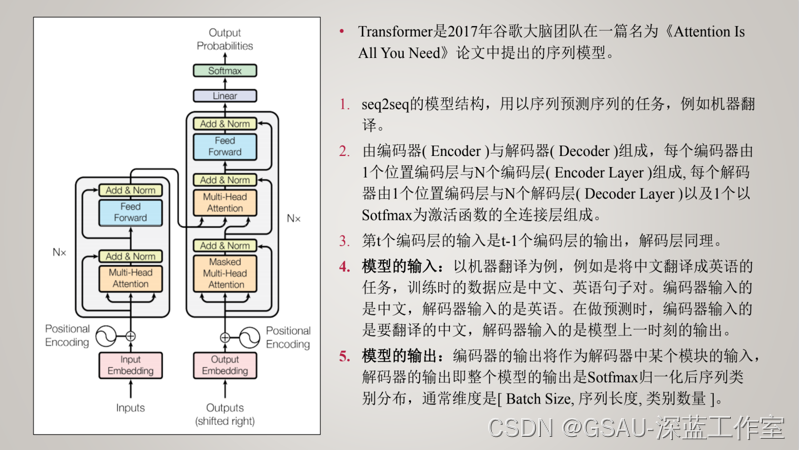
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
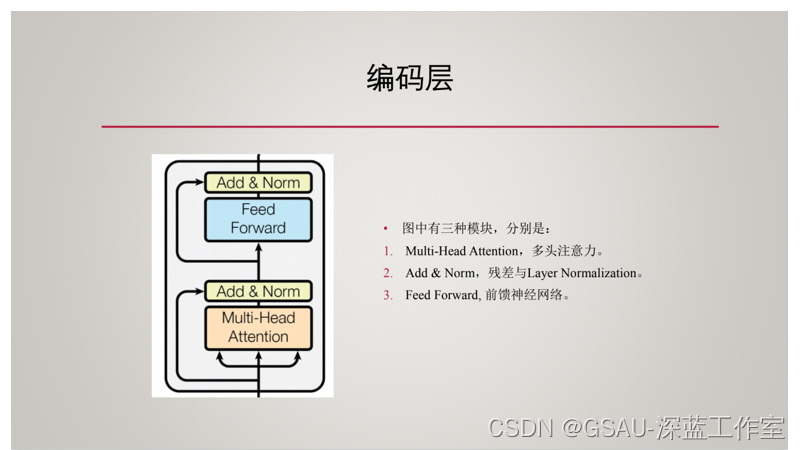
 ?
?
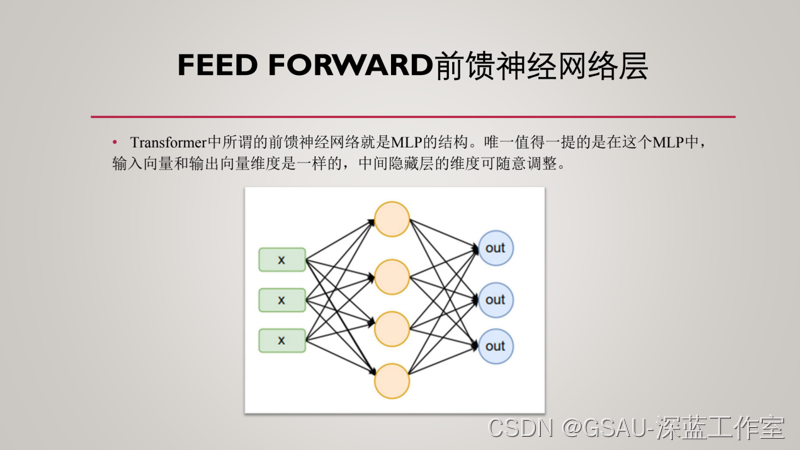
 ?
?
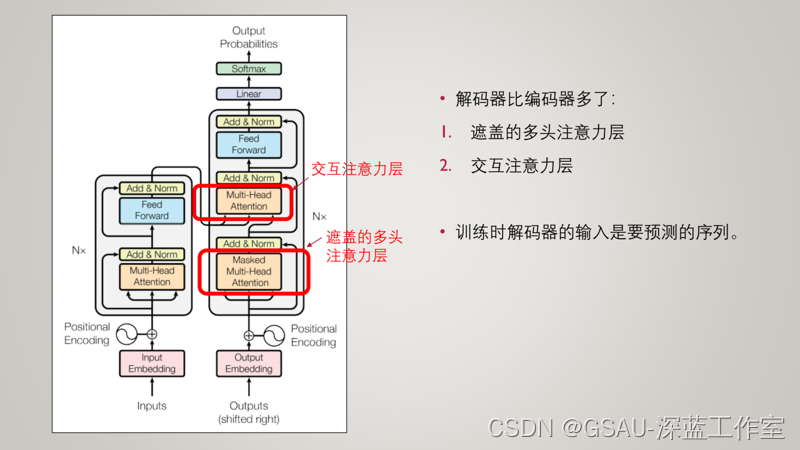 ?
?
 ?
?
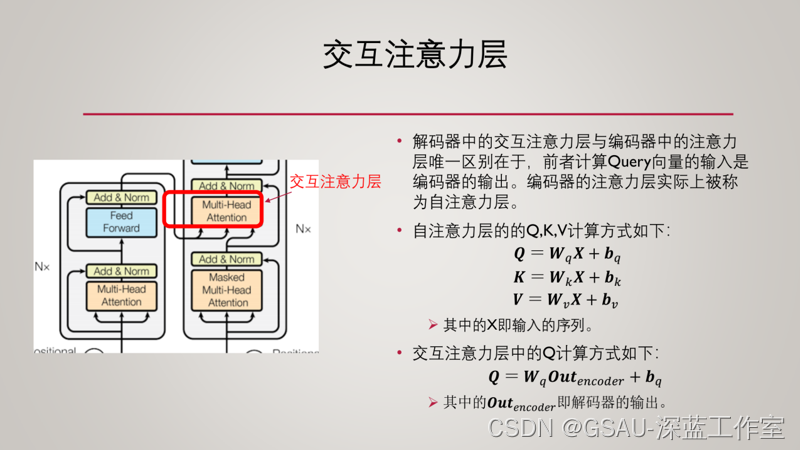 ?
?
 ?
?
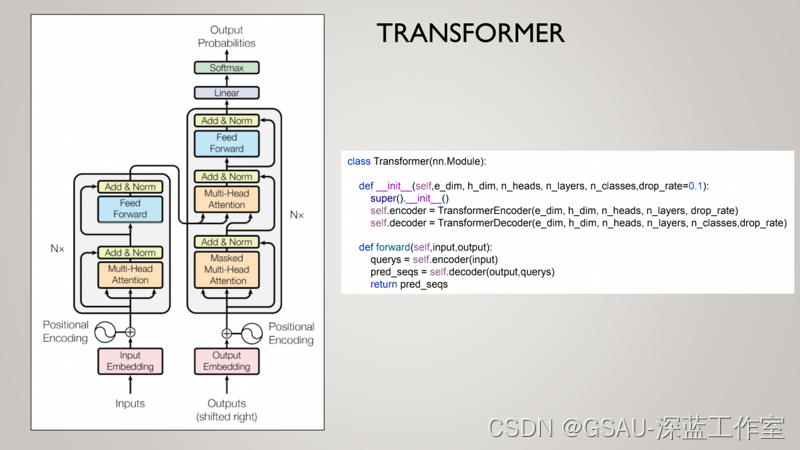
代码段:
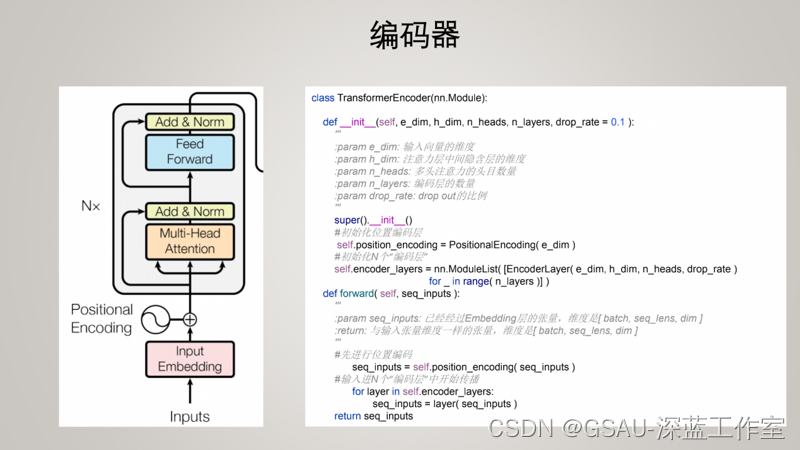
1、编码层
class EncoderLayer(nn.Module):
def __init__( self, e_dim, h_dim, n_heads, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化多头注意力层
self.attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化注意力层之后的LN
self.a_LN = nn.LayerNorm( e_dim )
# 初始化前馈神经网络层
self.ff_layer = FeedForward( e_dim, e_dim//2 )
# 初始化前馈网络之后的LN
self.ff_LN = nn.LayerNorm( e_dim )
self.drop_out = nn.Dropout( drop_rate )
def forward(self, seq_inputs ):
# seq_inputs = [batch, seqs_len, e_dim]
# 多头注意力, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.attention( seq_inputs )
# 残差连接与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.a_LN( seq_inputs + self.drop_out( outs_ ) )
# 前馈神经网络, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.ff_layer( outs )
# 残差与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.ff_LN( outs + self.drop_out( outs_) )
return outs2、编码器:多个编码层和一个位置编码层
class TransformerEncoder(nn.Module):
def __init__(self, e_dim, h_dim, n_heads, n_layers, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param n_layers: 编码层的数量
:param drop_rate: drop out的比例
'''
super().__init__()
#初始化位置编码层
self.position_encoding = PositionalEncoding( e_dim )
#初始化N个“编码层”
self.encoder_layers = nn.ModuleList( [EncoderLayer( e_dim, h_dim, n_heads, drop_rate )
for _ in range( n_layers )] )
def forward( self, seq_inputs ):
'''
:param seq_inputs: 已经经过Embedding层的张量,维度是[ batch, seq_lens, dim ]
:return: 与输入张量维度一样的张量,维度是[ batch, seq_lens, dim ]
'''
#先进行位置编码
seq_inputs = self.position_encoding( seq_inputs )
#输入进N个“编码层”中开始传播
for layer in self.encoder_layers:
seq_inputs = layer( seq_inputs )
return seq_inputs3、解码层
class DecoderLayer(nn.Module):
def __init__( self, e_dim, h_dim, n_heads, drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化自注意力层
self.self_attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化自注意力层之后的LN
self.sa_LN = nn.LayerNorm( e_dim )
# 初始化交互注意力层
self.interactive_attention = MultiHeadAttentionLayer( e_dim, h_dim, n_heads )
# 初始化交互注意力层之后的LN
self.ia_LN = nn.LayerNorm (e_dim )
# 初始化前馈神经网络层
self.ff_layer = FeedForward( e_dim, e_dim//2 )
# 初始化前馈网络之后的LN
self.ff_LN = nn.LayerNorm( e_dim )
self.drop_out = nn.Dropout( drop_rate )
def forward( self, seq_inputs , querys, mask ):
'''
:param seq_inputs: [ batch, seqs_len, e_dim ]
:param querys: encoder的输出
:param mask: 遮盖位置的标注序列 [ 1, seqs_len, seqs_len ]
'''
# 自注意力层, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.self_attention( seq_inputs , mask=mask )
# 残差连与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.sa_LN( seq_inputs + self.drop_out( outs_ ) )
# 交互注意力层, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.interactive_attention( outs, querys )
# 残差连与LN, 输出维度[ batch, seq_lens, e_dim
outs = self.ia_LN( outs + self.drop_out(outs_) )
# 前馈神经网络, 输出维度[ batch, seq_lens, e_dim ]
outs_ = self.ff_layer( outs )
# 残差与LN, 输出维度[ batch, seq_lens, e_dim ]
outs = self.ff_LN( outs + self.drop_out( outs_) )
return outs4、解码器
class TransformerDecoder(nn.Module):
def __init__(self, e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate = 0.1 ):
'''
:param e_dim: 输入向量的维度
:param h_dim: 注意力层中间隐含层的维度
:param n_heads: 多头注意力的头目数量
:param n_layers: 解码层的数量
:param n_classes: 类别数
:param drop_rate: drop out的比例
'''
super().__init__()
# 初始化位置编码层
self.position_encoding = PositionalEncoding( e_dim )
# 初始化N个“解码层”
self.decoder_layers = nn.ModuleList( [DecoderLayer( e_dim, h_dim, n_heads, drop_rate )
for _ in range( n_layers )] )
# 线性层
self.linear = nn.Linear(e_dim,n_classes)
# softmax激活函数
self.softmax = nn.Softmax()
def forward( self, seq_inputs, querys ):
'''
:param seq_inputs: 已经经过Embedding层的张量,维度是[ batch, seq_lens, dim ]
:param querys: encoder的输出,维度是[ batch, seq_lens, dim ]
:return: 与输入张量维度一样的张量,维度是[ batch, seq_lens, dim ]
'''
# 先进行位置编码
seq_inputs = self.position_encoding( seq_inputs )
# 得到mask序列
mask = subsequent_mask( seq_inputs.shape[1] )
# 输入进N个“解码层”中开始传播
for layer in self.decoder_layers:
seq_inputs = layer( seq_inputs, querys, mask )
# 最终线性变化后Softmax归一化
seq_outputs = self.softmax(self.linear(seq_inputs))
return seq_outputs
5、Transformer
class Transformer(nn.Module):
def __init__(self,e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate=0.1):
super().__init__()
self.encoder = TransformerEncoder(e_dim, h_dim, n_heads, n_layers, drop_rate)
self.decoder = TransformerDecoder(e_dim, h_dim, n_heads, n_layers, n_classes,drop_rate)
def forward(self,input,output):
querys = self.encoder(input)
pred_seqs = self.decoder(output,querys)
return pred_seqs?分享视频
Transformer
分享人:张彦博
分享时间:2022/4/28
分享平台:腾讯会议

